
动手实验+源码分析,彻底弄懂 Linux 网络命名空间
作者丨张彦飞allen
来源丨开发内功修炼
大家好,我是飞哥!
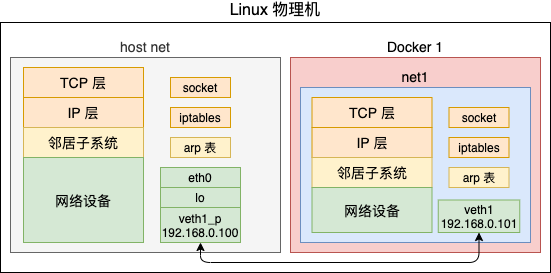
在 Linux 上通过 veth 我们可以创建出许多的虚拟设备。通过 Bridge 模拟以太网交换机的方式可以让这些网络设备之间进行通信。不过虚拟化中还有很重要的一步,那就是隔离。借用 Docker 的概念来说,那就是不能让 A 容器用到 B 容器的设备,甚至连看一眼都不可以。只有这样才能保证不同的容器之间复用硬件资源的同时,还不会影响其它容器的正常运行。
在 Linux 上实现隔离的技术手段就是 namespace。通过 namespace 可以隔离容器的进程 PID、文件系统挂载点、主机名等多种资源。不过我们今天重点要介绍的是网络 namespace,简称 netns。它可以为不同的命名空间从逻辑上提供独立的网络协议栈,具体包括网络设备、路由表、arp表、iptables、以及套接字(socket)等。使得不同的网络空间就都好像运行在独立的网络中一样。

你是不是和飞哥一样,也很好奇 Linux 底层到底是如何实现网络隔离的?我们今天来好好挖一挖 netns 的内部实现。
一、如何使用 netns
由于我们平时的开发工作很少涉及网络空间,所以我们先来看一下网络空间是如何使用的吧。我们来创建一个新的命名空间net1。再创建一对儿 veth,将 veth 的一头放到 net1 中。分别查看一下母机和 net1 空间内的 iptable、设备等。最后让两个命名空间之间进行通信。
# ip netns add net1
来查看一下它的 iptable、路由表、以及网络设备
# ip netns exec net1 route
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
# ip netns exec net1 iptables -L
ip netns exec net1 iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
......
# ip netns exec net1 ip link list
lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
由于是新创建的 netns,所以上述的输出中路由表、iptable规则都是空的。不过这个命名空间中初始的情况下就存在一个 lo 本地环回设备,只不过默认是 DOWN(未启动)状态。
接下来我们创建一对儿 veth,并把 veth 的一头添加给它。
# ip link add veth1 type veth peer name veth1_p
# ip link set veth1 netns net1
在母机上查看一下当前的设备,发现已经看不到 veth1 这个网卡设备了,只能看到 veth1_p。
# ip link list
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 ...
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 ...
3: eth1: <BROADCAST,MULTICAST> mtu 1500 ...
45: veth1_p@if46: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 0e:13:18:0a:98:9c brd ff:ff:ff:ff:ff:ff link-netnsid 0
这个新设备已经跑到 net1 这个网络空间里了。
# ip netns exec net1 ip link list
1: lo: <LOOPBACK> mtu 65536 ...
46: veth1@if45: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 7e:cd:ec:1c:5d:7a brd ff:ff:ff:ff:ff:ff link-netnsid 0
把这对儿 veth 分别配置上 ip,并把它们启动起来
# ip netns exec net1 ip addr add 192.168.0.100/24 dev veth1_p
# ip netns exec net1 ip addr add 192.168.0.101/24 dev veth1
# ip netns exec net1 ip link set dev veth1_p up
# ip netns exec net1 ip link set dev veth1 up
在母机和 net1 中分别执行 ifconfig 查看当前启动的网络设备。
# ifconfig
eth0: ...
lo: ...
veth1_p: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.100 netmask 255.255.255.0 broadcast 0.0.0.0
...
# ip netns exec net1 ifconfig
veth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.0.101 netmask 255.255.255.0 broadcast 0.0.0.0
...
我们来让它和母机通信一下试试。
# ip netns exec net1 ping 192.168.0.100 -I veth1
PING 192.168.0.100 (192.168.0.100) from 192.168.0.101 veth1: 56(84) bytes of data.
64 bytes from 192.168.0.100: icmp_seq=1 ttl=64 time=0.027 ms
64 bytes from 192.168.0.100: icmp_seq=2 ttl=64 time=0.010 ms
好了,现在一个新网络命名空间创建实验就结束了。在这个空间里,网络设备、路由表、arp表、iptables都是独立的,不会和母机上的冲突,也不会和其它空间里的产生干扰。而且还可以通过 veth 来和其它空间下的网络进行通信。
想快速做这个实验的同学可以使用我写的一个makefile,见 https://github.com/yanfeizhang/coder-kung-fu/tree/main/tests/network/test05
二、内核中 namespace 的定义
在内核中,很多组件都是和 namespace 有关系的,我们先来看看这个关联关系是如何定义的。后面我们再看下 namespace 本身的详细结构。
2.1 归属到 namespace 的东东
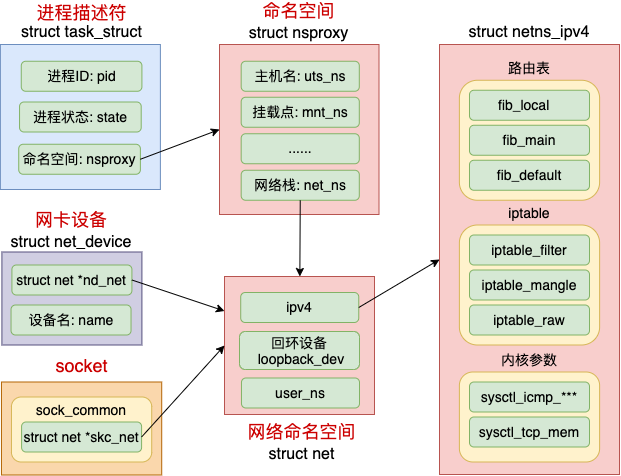
在 Linux 中,很多我们平常熟悉的概念都是归属到某一个特定的网络 namespace 中的,比如进程、网卡设备、socket 等等。
Linux 中每个进程(线程)都是用 task_struct 来表示的。每个 task_struct 都要关联到一个 namespace 对象 nsproxy,而 nsproxy 又包含了 netns。对于网卡设备和 socket 来说,通过自己的成员来直接表明自己的归属。
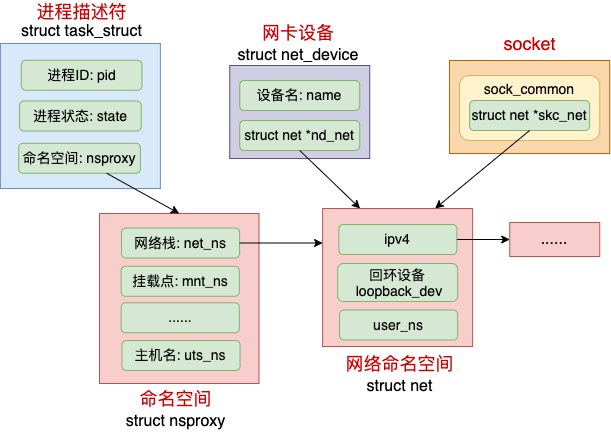
拿网络设备来举例,只有归属到当前 netns 下的时候才能够通过 ifconfig 看到,否则是不可见的。我们详细来看看这几个数据结构的定义,先来看进程。
//file:include/linux/sched.h
struct task_struct {
/* namespaces */
struct nsproxy *nsproxy;
......
}
命名空间的核心数据结构是上面的这个 struct nsproxy。所有类型的 namespace(包括 pid、文件系统挂载点、网络栈等等)都是在这里定义的。
//file: include/linux/nsproxy.h
struct nsproxy {
struct uts_namespace *uts_ns; // 主机名
struct ipc_namespace *ipc_ns; // IPC
struct mnt_namespace *mnt_ns; // 文件系统挂载点
struct pid_namespace *pid_ns; // 进程标号
struct net *net_ns; // 网络协议栈
};
其中 struct net *net_ns 就是今天我们要讨论的网络命名空间。它的详细定义我们待会再说。我们接着再看表示网络设备的 struct net_device,它也是要归属到某一个网络空间下的。
//file: include/linux/netdevice.h
struct net_device{
//设备名
char name[IFNAMSIZ];
//网络命名空间
struct net *nd_net;
...
}
所有的网络设备刚创建出来都是在宿主机默认网络空间下的。可以通过ip link set 设备名 netns 网络空间名将设备移动到另外一个空间里去。前面的实验里,当 veth 1 移动到 net1 下的时候,该设备在宿主机下“消失”了,在 net1 下就能看到了。
还有我们经常用的 socket,也是归属在某一个网络命名空间下的。
//file:
struct sock_common {
struct net *skc_net;
}
2.2 网络 namespace 定义
本小节中,我们来看网络 namespace 的主要数据结构 struct net 的定义。
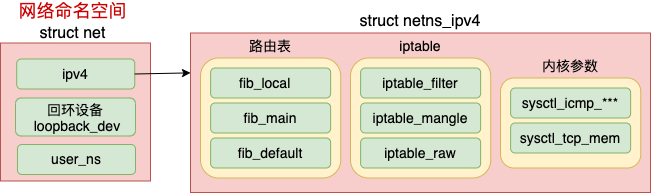
可见每个 net 下都包含了自己的路由表、iptable 以及内核参数配置等等。我们来看具体的代码。
//file:include/net/net_namespace.h
struct net {
//每个 net 中都有一个回环设备
struct net_device *loopback_dev; /* The loopback */
//路由表、netfilter都在这里
struct netns_ipv4 ipv4;
......
unsigned int proc_inum;
}
由上述定义可见,每一个 netns 中都有一个 loopback_dev,这就是为什么我们在第一节中看到刚创建出来的空间里就能看到一个 lo 设备的底层原因。
网络 netspace 中最核心的数据结构是 struct netns_ipv4 ipv4。在这个数据结构里,定义了每一个网络空间专属的路由表、ipfilter 以及各种内核参数。
//file: include/net/netns/ipv4.h
struct netns_ipv4 {
//路由表
struct fib_table *fib_local;
struct fib_table *fib_main;
struct fib_table *fib_default;
//ip表
struct xt_table *iptable_filter;
struct xt_table *iptable_raw;
struct xt_table *arptable_filter;
//内核参数
long sysctl_tcp_mem[3];
...
}
三、网络 namespace 的创建
回顾第一小节中,我们实验步骤主要是创建了一个 netns,为其添加了一个 veth 设备。在这节中我们来窥探一下刚才的实验步骤内部到底是如何运行的。
3.1 进程与网络命名空间
Linux 上存在一个默认的网络命名空间,Linux 中的 1 号进程初始使用该默认空间。Linux 上其它所有进程都是由 1 号进程派生出来的,在派生 clone 的时候如果没有额外特别指定,所有的进程都将共享这个默认网络空间。
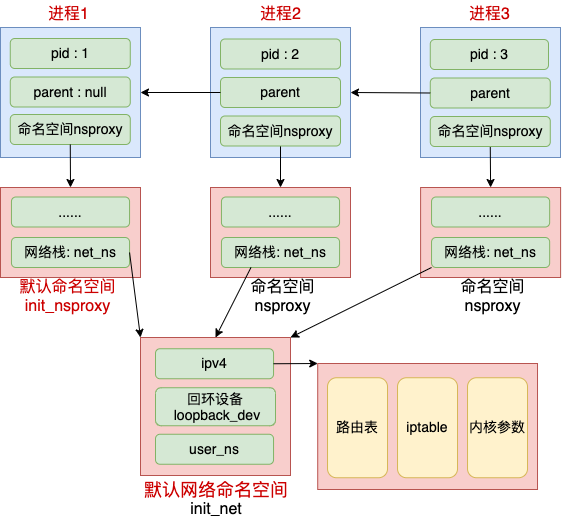
在 clone 里可以指定创建新进程时的 flag,都是 CLONE_ 开头的。和 namespace 有的的标志位有 CLONE_NEWIPC、CLONE_NEWNET、CLONE_NEWNS、CLONE_NEWPID 等等。如果在创建进程时指定了 CLONE_NEWNET 标记位,那么该进程将会创建并使用新的 netns。
其实内核提供了三种操作命名空间的方式,分别是 clone、setns 和 unshare。本文中我们只用 clone 来举例,ip netns add 使用的是 unshare,原理和 clone 是类似的。
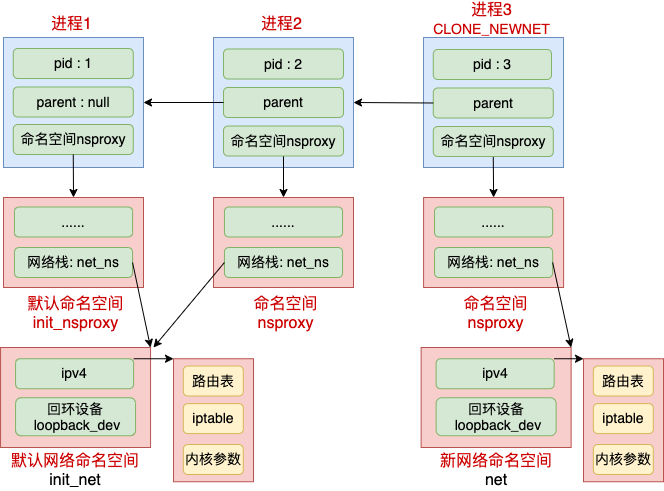
//file: init/init_task.c
struct task_struct init_task = INIT_TASK(init_task);
//file: include/linux/init_task.h
#define INIT_TASK(tsk) \
{
...
.nsproxy = &init_nsproxy, \
}
上面的代码是在初始化第 1 号进程。可见 nsproxy 是已经创建好的 init_nsproxy。再看 init_nsproxy 是如何创建的。
//file: kernel/nsproxy.c
struct nsproxy init_nsproxy = {
.uts_ns = &init_uts_ns,
.ipc_ns = &init_ipc_ns,
.mnt_ns = NULL,
.pid_ns = &init_pid_ns,
.net_ns = &init_net,
};
初始的 init_nsproxy 里将多个命名空间都进行了初始化,其中我们关注的网络命名空间,用的是默认网络空间 init_net。它是系统初始化的时候就创建好的。
//file: net/core/net_namespace.c
struct net init_net = {
.dev_base_head = LIST_HEAD_INIT(init_net.dev_base_head),
};
EXPORT_SYMBOL(init_net);
//file: net/core/net_namespace.c
static int __init net_ns_init(void)
{
...
setup_net(&init_net, &init_user_ns);
...
register_pernet_subsys(&net_ns_ops);
return 0;
}
上面的 setup_net 方法中对这个默认网络命名空间进行初始化。
看到这里我们清楚了 1 号进程的命名空间初始化过程。Linux 中所有的进程都是由这个 1 号进程创建的。如果创建子进程过程中没有指定 CLONE_NEWNET 这个 flag 的话,就直接还使用这个默认的网络空间。
如果创建进程过程中指定了 CLONE_NEWNET,那么就会重新申请一个网络命名空间出来。见如下的关键函数 copy_net_ns(它的调用链是 do_fork => copy_process => copy_namespaces => create_new_namespaces => copy_net_ns)。
//file: net/core/net_namespace.c
struct net *copy_net_ns(unsigned long flags,
struct user_namespace *user_ns, struct net *old_net)
{
struct net *net;
// 重要!!!
// 不指定 CLONE_NEWNET 就不会创建新的网络命名空间
if (!(flags & CLONE_NEWNET))
return get_net(old_net);
//申请新网络命名空间并初始化
net = net_alloc();
rv = setup_net(net, user_ns);
...
}
记住 setup_net 是初始化网络命名空间的,这个函数接下来我们还会提到。
3.2 命名空间内的网络子系统初始化
命名空间内的各个组件都是在 setup_net 时初始化的,包括路由表、tcp 的 proc 伪文件系统、iptable 规则读取等等,所以这个小节也是蛮重要的。
由于内核网络模块的复杂性,在内核中将网络模块划分成了各个子系统。每个子系统都定义了一个
//file: include/net/net_namespace.h
struct pernet_operations {
// 链表指针
struct list_head list;
// 子系统的初始化函数
int (*init)(struct net *net);
// 网络命名空间每个子系统的退出函数
void (*exit)(struct net *net);
void (*exit_batch)(struct list_head *net_exit_list);
int *id;
size_t size;
};
各个子系统通过调用 register_pernet_subsys 或 register_pernet_device 将其初始化函数注册到网络命名空间系统的全局链表 pernet_list 中。你在源码目录下用这两个函数搜索的话,会看到各个子系统的注册过程。

//file: net/core/net_namespace.c
static struct list_head *first_device = &pernet_list;
int register_pernet_subsys(struct pernet_operations *ops)
{
error = register_pernet_operations(first_device, ops);
...
}
register_pernet_operations 又会调用 __register_pernet_operations。
//file: include/net/net_namespace.h
#define for_each_net(VAR) \
list_for_each_entry(VAR, &net_namespace_list, list)
//file: net/core/net_namespace.c
static int __register_pernet_operations(struct list_head *list,
struct pernet_operations *ops)
{
struct net *net;
list_add_tail(&ops->list, list);
if (ops->init || (ops->id && ops->size)) {
for_each_net(net) {
error = ops_init(ops, net);
...
}
在上面 list_add_tail 这一行,完成了将子系统传入的 struct pernet_operations *ops 链入到 pernet_list 中。并注意一下,for_each_net 是遍历了所有的网络命名空间,然后在这个空间内执行了 ops_init 初始化。
这个初始化是网络子系统在注册的时候调用的。同样当新的命名空间创建时,会遍历该全局变量 pernet_list,执行每个子模块注册上来的初始化函数。再回到我们 3.1.1 里提到的 setup_net 函数。
//file: net/core/net_namespace.c
static __net_init int setup_net(struct net *net, struct user_namespace *user_ns)
{
const struct pernet_operations *ops;
list_for_each_entry(ops, &pernet_list, list) {
error = ops_init(ops, net);
...
}
//file: net/core/net_namespace.c
static int ops_init(const struct pernet_operations *ops, struct net *net)
{
if (ops->init)
err = ops->init(net);
}
在创建新命名空间调用到 setup_net 时,会通过 pernet_list 找到所有的网络子系统,把它们都 init 一遍。
我们拿路由表来举例,路由表子系统通过 register_pernet_subsys 将 fib_net_ops 注册进来了。
//file: net/ipv4/fib_frontend.c
static struct pernet_operations fib_net_ops = {
.init = fib_net_init,
.exit = fib_net_exit,
};
void __init ip_fib_init(void)
{
register_pernet_subsys(&fib_net_ops);
...
}
这样每当创建一个新的命名空间的时候,就会调用 fib_net_init 来创建一套独立的路由规则。
再比如拿 iptable 中的 nat 表来说,也是一样。每当创建新命名空间的时候,就会调用 iptable_nat_net_init 创建一套新的表。
//file: net/ipv4/netfilter/iptable_nat.c
static struct pernet_operations iptable_nat_net_ops = {
.init = iptable_nat_net_init,
.exit = iptable_nat_net_exit,
};
static int __init iptable_nat_init(void)
{
err = register_pernet_subsys(&iptable_nat_net_ops);
...
3.3 添加设备
在一个设备刚刚创建出来的时候,它是属于默认网络命名空间 init_net 的,包括 veth 设备。不过可以在创建完后修改设备到新的网络命名空间。
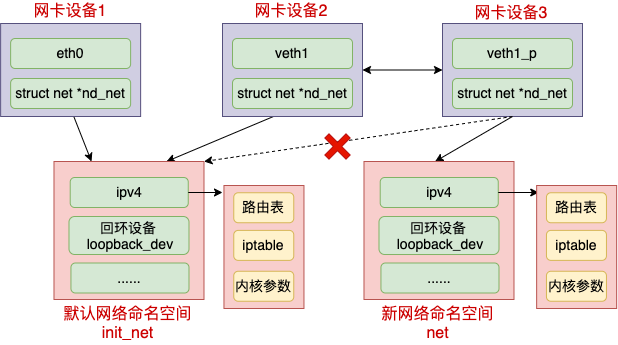
//file: core/dev.c
struct net_device *alloc_netdev_mqs(...)
{
dev_net_set(dev, &init_net);
}
//file: include/linux/netdevice.h
void dev_net_set(struct net_device *dev,struct net *net)
{
release_net(dev->nd_net);
dev->nd_net = hold_net(net);
}
在执行 修改设备所属的 namespace 的时候,会将 dev->nd_net 再指向新的 netns。对于 veth 来说,它包含了两个设备。这两个设备可以放在不同的 namespace 中。这就是 Docker 容器和其母机或者其它容器通信的基础。
//file: core/dev.c
int dev_change_net_namespace(struct net_device *dev, struct net *net, ...)
{
...
dev_net_set(dev, net)
}
四、在 namespace 下的网络收发
在前面一节中,我们知道了内核是如何创建 netns 出来,也了解了网络设备是如何添加到其它命名空间里的。在这一小节,我们聊聊,当考虑到网络命名空间的时候,网络包的收发又是怎么样的呢?
4.1 socket 与网络命名空间
首先来考虑的就是我们熟悉的 socket。其实每个 socket 都是归属于某一个网络命名空间的,这个关联关系在上面的 2.1 小节提到过。
到底归属那个 netns,这是由创建这个 socket 的进程所属的 netns 来决定。当在某个进程里创建 socket 的时候,内核就会把当前进程的 nsproxy->net_ns 找出来,并把它赋值给 socket 上的网络命名空间成员 skc_net。
在默认下,我们创建的 socket 都属于默认的网络命名空间 init_net
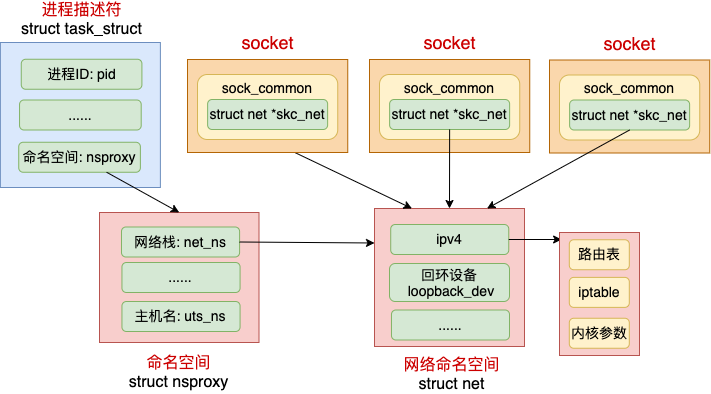
//file: include/net/sock.h
struct sock_common {
...
struct net *skc_net;
}
接下来就是 socket 创建的时候,内核中可以通过 current->nsproxy->net_ns 把当前进程所属的 netns 找出来,最终把 socket 中的 sk_net 成员和该命名空间建立好了联系。
//file: net/socket.c
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
在 socket_create 中,看到 current->nsproxy->net_ns 了吧,它获取到了进程的 netns。再依次经过__sock_create => inet_create => sk_alloc,调用到 sock_net_set 的时候,成功设置了新 socket 和 netns 的关联关系。
//file: include/net/sock.h
static inline
void sock_net_set(struct sock *sk, struct net *net)
{
write_pnet(&sk->sk_net, net);
}
4.2 网络包的收发过程
网络包的接收和发送过程我们在这两篇文章里详细介绍过,图解Linux网络包接收过程 和 25 张图,一万字,拆解 Linux 网络包发送过程。
本小节的不再重复赘述这个收发过程,我们就以网络包发送过程中的路由功能为例,来看一下网络在传输的时候是如何使用到 netns 的。其它收发过程中的各个步骤也都是类似的。
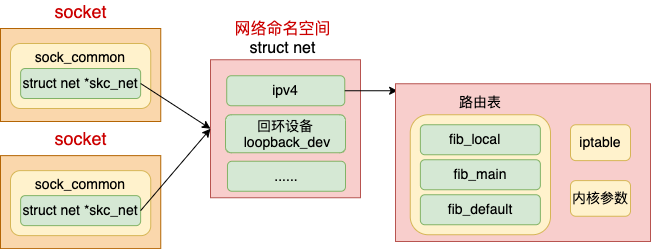
我们来看详细的路由查找源码。在25 张图,一万字,拆解 Linux 网络包发送过程 中我们提到过在发送过程中在 IP 层的发送函数 ip_queue_xmit 中调用 ip_route_output_ports 来查找路由项。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl)
{
rt = ip_route_output_ports(sock_net(sk), fl4, sk,
daddr, inet->inet_saddr,
...);
}
注意上面的 sock_net(sk) 这一步,在这里将 socket 上记录的命名空间 struct net *sk_net 给找了出来。
//file: include/net/sock.h
static inline struct net *sock_net(const struct sock *sk)
{
return read_pnet(&sk->sk_net);
}
找到命名空间以后,就会将它(以 struct net * 指针的形式)一路透传到后面的各个函数中。在127.0.0.1 之本机网络通信过程知多少 ?! 中我们介绍了路由查找最后会执行到 fib_lookup,我们来看下这个函数的源码。
路由查找的调用链条有点长,是 ip_route_output_ports => ->ip_route_output_flow => __ip_route_output_key() => ip_route_output_key_hash => ip_route_output_key_hash_rcu)
//file: include/net/ip_fib.h
static inline int fib_lookup(struct net *net, ...)
{
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
table = fib_get_table(net, RT_TABLE_MAIN);
...
}
static inline struct fib_table *fib_get_table(struct net *net, u32 id)
{
ptr = id == RT_TABLE_LOCAL ?
&net->ipv4.fib_table_hash[TABLE_LOCAL_INDEX] :
&net->ipv4.fib_table_hash[TABLE_MAIN_INDEX];
return hlist_entry(ptr->first, struct fib_table, tb_hlist);
}
由上述代码可见,在路由过程中是根据前面步骤中确定好的命名空间 struct net *net 来查找路由项的。不同的命名空间有不同的 net 变量,所以不同的 netns 中自然也就可以配置不同的路由表了。
网络收发过程中其它步骤也是类似的,涉及到需要隔离的地方,都是通过命名空间( struct net *) 去查找的。
五、结论
Linux 的网络 namespace 实现了独立协议栈的隔离。这个说法其实不是很准确,内核网络代码只有一套,并没有隔离。
它是通过为不同空间创建不同的 struct net 对象。每个 struct net 中都有独立的路由表、iptable 等数据结构。每个设备、每个 socket 上也都有指针指明自己归属那个 netns。通过这种方法从逻辑上看起来好像是真的有多个协议栈一样。
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
面试题】即可获取