
干货|利用Python自动根据数据生成降雨量统计分析报告

作者:小小明
简介:Pandas数据处理专家,10余年编码经验,至今已帮助过成千上万名数据从业者解决工作实际遇到的问题,其中数据处理和办公自动化问题涉及的行业包括会计、HR、气象、金融等等,现为菜J学Python核心技术团队成员之一。
点击上方“IT共享之家”,进行关注
回复“资料”可获赠Python学习福利

import pandas as pd
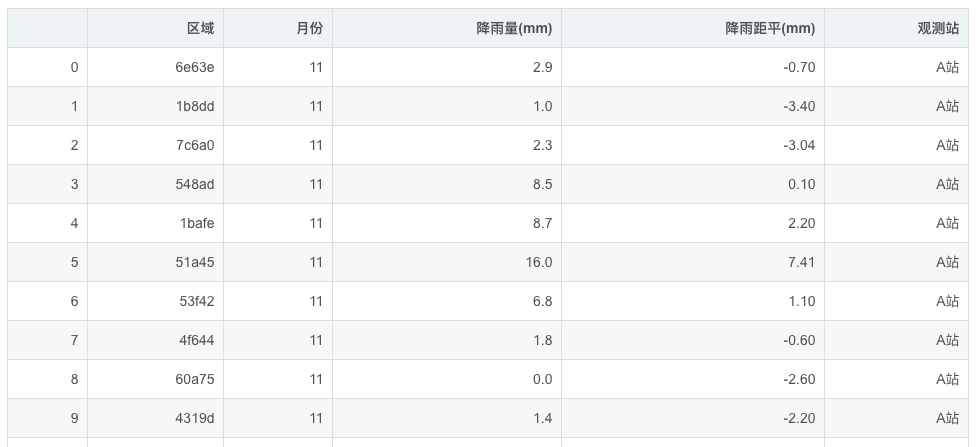
df = pd.read_csv("11月份数据.csv", encoding='gbk')
# 当前统计月份
month = 11
df = df.query('月份==@month')
df.head(10)
pd.isnull(df).sum()
区域 0
月份 0
降雨量(mm) 0
降雨距平(mm) 1
观测站 0
dtype: int64
df.dropna(inplace=True)
rainfall_high = df.eval('`降雨距平(mm)` > 0').value_counts().get(True, 0)
rainfall_equal = df.eval('`降雨距平(mm)` == 0').value_counts().get(True, 0)
rainfall_low = df.eval('`降雨距平(mm)` < 0').value_counts().get(True, 0)
print(rainfall_high, rainfall_equal, rainfall_low)
13 1 18
p1 = f"{month}月份"
if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p1 += f"除{rainfall_equal}个观测站降雨量较往年无变化外,"
if rainfall_high == 0:
p1 += f"各气象观测站降雨量较往年均偏低。"
elif rainfall_low == 0:
p1 += f"各气象观测站降雨量较往年均偏高。"
else:
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
p1 += f"大部分气象观测站降雨量较往年偏高。"
elif rainfall_low > rainfall_high*1.1:
p1 += f"大部分气象观测站降雨量较往年偏低。"
else:
p1 += f"各气象观测站降雨量较往年整体持平。"
p1
'11月份大部分气象观测站降雨量较往年偏低。'
p2 = ""
t = df['降雨量(mm)']
p2 += f"各区域降雨量在{t.min()}~{t.max()}mm之间,其中{df.loc[t.argmax(), '区域']}区域的降雨量最大,为{t.max()}mm。"
p2
'各区域降雨量在0.0~16.0mm之间,其中51a45区域的降雨量最大,为16.0mm。'
p3s = []
for station, tmp in df.groupby('观测站'):
t = tmp['降雨量(mm)']
p3 = f"各区域降雨量在{t.min()}~{t.max()}mm之间,"
rainfall_high_mask = tmp.eval('`降雨距平(mm)` > 0')
rainfall_equal_mask = tmp.eval('`降雨距平(mm)` == 0')
rainfall_low_mask = tmp.eval('`降雨距平(mm)` < 0')
rainfall_high = rainfall_high_mask.value_counts().get(True, 0)
rainfall_equal = rainfall_equal_mask.value_counts().get(True, 0)
rainfall_low = rainfall_low_mask.value_counts().get(True, 0)
# print(rainfall_high, rainfall_equal, rainfall_low)
if rainfall_low == 0 or rainfall_high == 0:
if rainfall_equal != 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')
p3 += "降雨量较往年无变化外,"
if rainfall_high == 0:
p3 += f"各区域降雨量均较往年偏低"
elif rainfall_low == 0:
p3 += f"各区域降雨量均较往年偏高"
t = tmp['降雨距平(mm)'].abs()
p3 += f"{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_equal_mask, '区域']+'区域')
p3 += "降雨量较往年无变化,"
# 10%以内差异认为是持平
if rainfall_high > rainfall_low*1.1:
if rainfall_equal == 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
p3 += f"其余各区域降雨量较往年偏高{t.min()}~{t.max()}mm;"
elif rainfall_low > rainfall_high*1.1:
if rainfall_equal == 0:
p3 += '除'
p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm"
else:
p3 += f"{t.min()}mm"
p3 += "外,"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
p3 += f"其余各区域降雨量较往年偏低{t.min()}~{t.max()}mm;"
else:
if rainfall_equal != 0:
p3 = p3[:-1]+'外,'
p3 += f"各区域降雨量较往年偏高和偏低的数量持平,其中"
p3 += '、'.join(tmp.loc[rainfall_low_mask, '区域']+'区域')
p3 += "降雨量较往年偏低"
t = tmp.loc[rainfall_low_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm,"
else:
p3 += f"{t.min()}mm,"
p3 += '、'.join(tmp.loc[rainfall_high_mask, '区域']+'区域')
p3 += "降雨量较往年偏高"
t = tmp.loc[rainfall_high_mask, '降雨距平(mm)'].abs()
if t.shape[0] > 1:
p3 += f"{t.min()}~{t.max()}mm;"
else:
p3 += f"{t.min()}mm;"
p3s.append([station, p3])
p3s[-1][-1] = p3s[-1][-1][:-1]+"。"
p3s
docxtemplate.docx的内容:一、{{ month }}月各气象观测站降雨量实况
(一)降水
{{ p1 }}
{{ p2 }}
{%p for station,p3 in p3s %}
{{ station }}:{{ p3 }}
{%p endfor %}
from docxtpl import DocxTemplate
tpl = DocxTemplate("docxtemplate.docx")
context = {
'month': month,
'p1': p1,
'p2': p2,
'p3s': p3s,
}
tpl.render(context)
tpl.save("11月降雨量报告.docx")

看完本文有收获?请转发分享给更多的人
IT共享之家
入群请在微信后台回复【入群】
------------------- End -------------------
往期精彩文章推荐:
评论