
那些轻轻拍了拍Attention的后浪们
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文介绍了11篇attention相关研究,参考了paperswithcode。
链接:https://paperswithcode.com/methods/category/attention-mechanisms
Linearized Attention(核函数)
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
论文链接:https://arxiv.org/pdf/2006.16236.pdf
Transformer中的Attention机制,形式为:
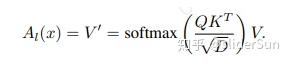
为了给计算复杂度降低到线性,使用核函数来简化Attention的计算过程,并且替换掉SoftMax。
我们可以将任何相似函数的广义Attention定义一般化:
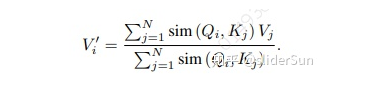
为了保留Attention的相似特性,我们要求恒成立。
我们可以给各自加个激活函数,
重写为如下所示
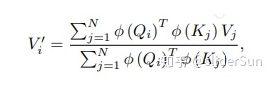
然后利用矩阵乘法的结合能进一步简化
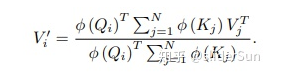
当分子写成向量化的形式时,上面的方程更简单
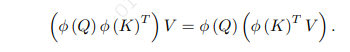
请注意,特征映射是按行向量应用于矩阵Q和K的。
本文选择的是。
Linear Attention最主要的想法是去掉标准Attention中的Softmax,就可以使得Attention的复杂度降低到。
Multi-Head Linear Attention
Linformer: Self-Attention with Linear Complexity
论文链接:https://arxiv.org/pdf/2006.04768v3.pdf
代码链接:https://github.com/tatp22/linformer-pytorchgithub.com
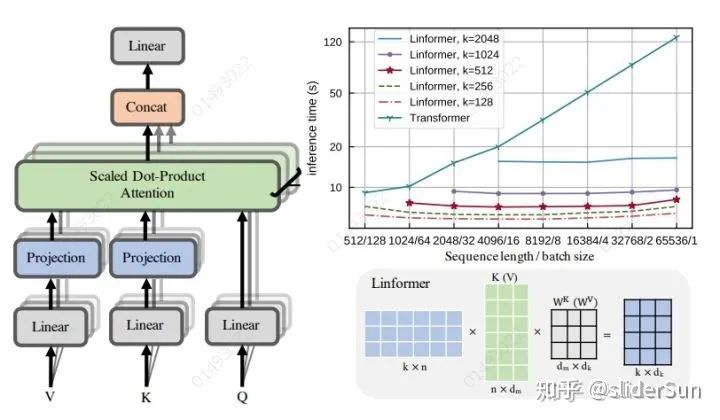
Multi-Head Linear Attention是线性多头自我注意模块,是与Linformer体系结构一起提出的。主要思想是添加两个线性投射矩阵。首先投影原始的(n×d)维 和 层和投射到维度的上下文映射矩阵。然后使用缩放的点积注意力计算(n×k)维上下文映射矩阵。
最后,我们使用计算每个头的上下文嵌入 。
详细介绍参见之前的一篇:https://zhuanlan.zhihu.com/p/147225773
LSH Attention
Reformer: The Efficient Transformer
论文链接:https://arxiv.org/pdf/2001.04451v2.pdf
代码链接:https://github.com/huggingface/transformersgithub.com
Locality sensitive hashing:Reformer的论文选择了局部敏感哈希的angular变体。它们首先约束每个输入向量的L2范数(即将向量投影到一个单位球面上),然后应用一系列的旋转,最后找到每个旋转向量所属的切片。这样一来就需要找到最近邻的值,这就需要局部敏感哈希(LSH)了,它能够快速在高维空间中找到最近邻。一个局部敏感哈希算法可以将每个向量 x 转换为 hash h(x),和这个 x 靠近的哈希更有可能有着相同的哈希值,而距离远的则不会。在这里,研究者希望最近的向量最可能得到相同的哈希值,或者 hash-bucket 大小相似的更有可能相同。
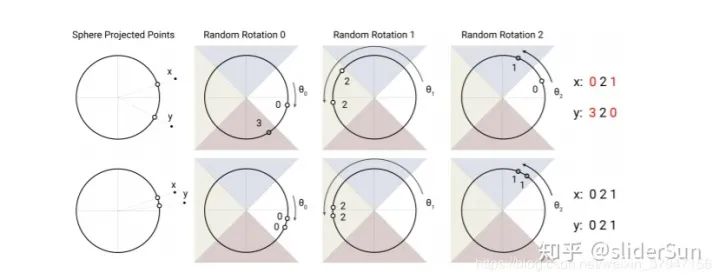
图1:局部敏感哈希算法使用球投影点的随机旋转,通过argmax在有符号的轴投影上建立bucket。在这个高度简化的2D描述中,对于三个不同的角哈希,两个点x和y不太可能共享相同的哈希桶(上图),除非它们的球面投影彼此接近(下图)。
该图演示了一个用4个桶进行3轮哈希的设置。下面的图中的向量映射到了同一个bucket,因为它们的输入很接近,而上一张图中的向量映射到第一个和最后一个bucket。
找到给定的向量选择之后属于哪个桶也可以看成是找到和输入最一致的向量——下面是Reformer的代码:
# simplified to only compute a singular hashrandom_rotations = np.random.randn(hidden_dim, n_buckets // 2)rotated_vectors = np.dot(x, random_rotations)rotated_vectors = np.hstack([rotated_vectors, -rotated_vectors])buckets = np.argmax(rotated_vectors, axis=-1)
把每个向量映射为一个哈希值叫做局部敏感哈希,如果比较近的向量能以高概率映射到同一个哈希值,而比较远的向量能以高概率被映射到不同的哈希值。为了得到个不同的哈希值,我们随机一个矩阵,大小为[dimension, b/2],然后定义h(x) = arg max([xR;−xR]) [u;v]表示两个向量的连接。这样,对所有的,我们就可以把它们分配到个哈希桶里面。
LSH attention:了解了我们的LSH方案和散列注意的一般思想之后,我们现在将正式定义我们在本文中使用的LSH注意。我们首先重写了正常注意的公式(1),一次只查询一个位置i:
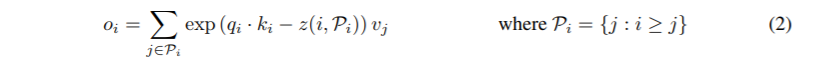
我们引入Pi表示在位置i处查询所处理的集合,z表示配分函数(即softmax中的规格化项)。为了清晰,我们还省略了的缩放。

出于成批处理的目的,我们通常对更大的集合Pei={0,1,…l}⊇Pi,掩盖元素不在Pi:
在为每个token计算一个桶之后,将根据它们的桶对这些token进行排序,并将标准的点积注意力应用到桶中的token的块上。
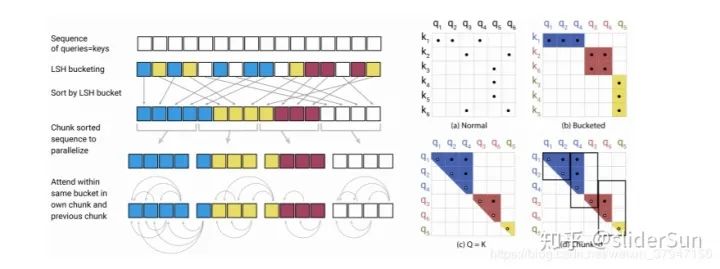
图2:简化的局部敏感哈希注意力,展示了 hash-bucketing、排序和分块步骤,并最终实现注意力机制。
现在我们转向LSH注意力,我们可以把它看作是通过只允许一个散列桶中的注意力来限制我可以关注的查询位置的目标项的集合Pi。
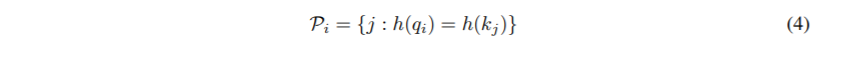
图2(a-b)显示了全注意力与散列变体的示意图比较。第(a)部分描述了全注意的注意矩阵通常是稀疏的,但是计算没有利用这种稀疏性。在(b)中,查询和键按照它们的散列桶排序。由于相似的物品很有可能落在同一个桶里,所以只允许在每个桶里集中注意力就可以近似地得到完整的注意力模式。
在这种格式中,散列桶的大小往往不均匀,这使得很难跨桶进行批处理。此外,一个bucket中的查询数量和键的数量可能是不相等的——实际上,一个bucket可能包含许多查询,但是没有键。为了缓解这些问题,我们首先通过设置来确保h(kj) = h(qj)。接下来,我们根据桶号对查询进行排序,在每个桶内,根据序列位置对查询进行排序;这定义了一个排序后i 7→si的排列。在排序后的注意矩阵中,来自同一桶的对将聚集在对角线附近(如图2c所示)。我们可以采用成批处理的方法,其中m个连续的查询块(排序后)相互处理,一个块返回(图2d)。按照我们之前的符号,这对应于设置:
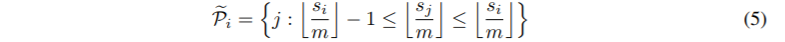
所以Reformer将Attention的复杂度降到了 。Reformer是通过LSH(近似地)快速地找到最大的若干个Attention值,然后只去计算那若干个值。
详细介绍参见之前的一篇:https://zhuanlan.zhihu.com/p/139220925
Sparse Attention
Longformer: The Long-Document Transformer
论文链接:https://arxiv.org/abs/2004.05150
代码链接:https://github.com/allenai/longformergithub.com
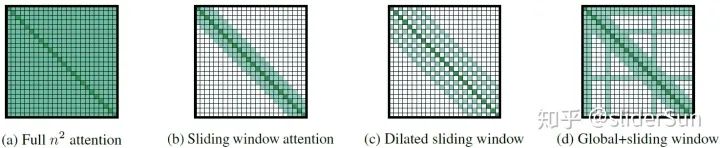
图1是原版自注意力(每个字符都能关注其他所有字符),图2是基于CNN的局部自注意力(以窗口的形式移动,每个窗口内的字符可以互相关注),图3是基于Dilated CNN的局部自注意力(跨越式滑动窗口),图4是结合局部自注意力和全局自注意力的稀疏自注意力。其中,“全局”的意思是,让小部分字符既能关注其他。
Sliding window attention
滑动窗口attention就是围绕每一个token采用固定大小的窗口计算局部注意力。假设窗口大小是w,序列长度是n,那么计算复杂度就是O(n*w),其中w远小于n。
Dilated Sliding Window attention
空洞滑动窗口,窗口的缝隙大小是d,假设窗口大小是w,transformer的层数是l,那么窗口能覆盖到的范围就是l*d*w。这种做法与CNN里头的空洞卷积类似。
Global + Sliding attention
图中有大量的“白色方块”,表示不需要关注,而随着文本长度的增加,这种白色方块的数量会呈平方级增加,所以实际上“绿色方块”数量是很少的。
作者在一些预先选择的位置上添加了全局注意力。在这些位置上,会对整个序列做attention。根据具体任务决定选择位置:
分类任务,global attention就使用[CLS]标签上。 QA任务,整个句子上计算global attention。
详细介绍参考:https://zhuanlan.zhihu.com/p/133491514
Synthesizer: Rethinking Self-Attention in Transformer Models
论文链接:https://arxiv.org/abs/2005.00743
Random Synthesized Attention
Factorized Random Synthesized Attention
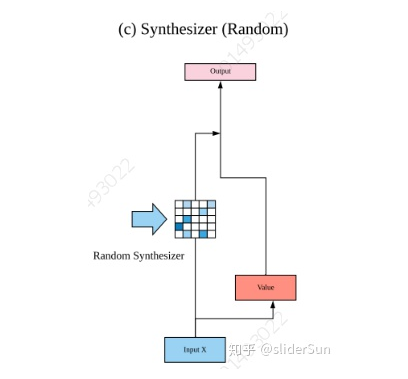
Dense Synthesized Attention
Factorized Dense Synthesized Attention
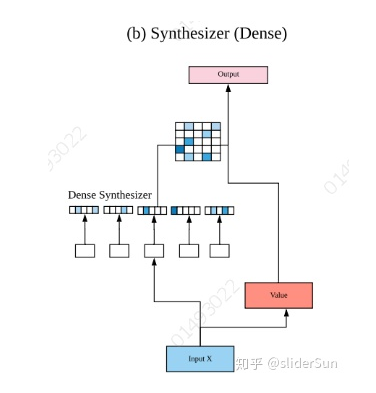
详细介绍参见:https://spaces.ac.cn/archives/7430
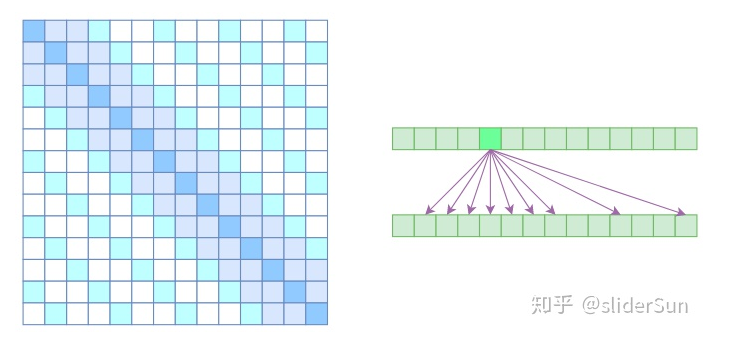
Sparse Attention
Generating Long Sequences with Sparse Transformers
论文链接:https://arxiv.org/abs/1904.10509
代码链接:https://github.com/openai/sparse_attentiongithub.com
苏剑林之前介绍过OpenAI的Sparse Attention,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。
详细介绍参见:https://spaces.ac.cn/archives/6853
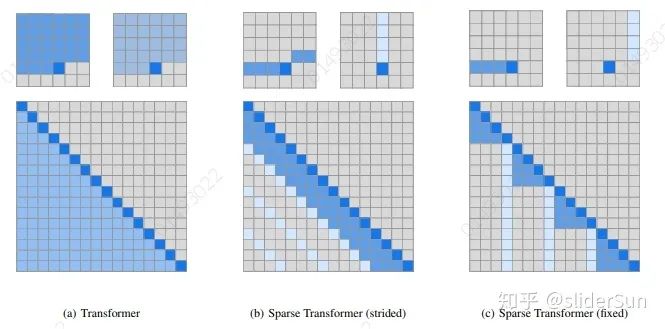
Strided Attention 和 Fixed Factorized Attention

论文链接:https://openreview.net/pdf?id=Hye87grYDH
Sparse Transformer仍然是基于Transformer的框架。不同之处在于self attention的实现。通过top-k选择,将注意退化为稀疏注意。这样,保留最有助于引起注意的部分,并删除其他无关的信息。这种选择性方法在保存重要信息和消除噪声方面是有效的。注意力可以更多地集中在最有贡献的价值因素上。
Single-Headed Attention
Single Headed Attention RNN: Stop Thinking With Your Head
论文链接:https://paperswithcode.com/paper/single-headed-attention-rnn-stop-thinking
代码链接:Smerity/sha-rnngithub.com
模型是由几个部分组成的:一个可训练的嵌入层,一层或者多层堆叠的单头注意力RNN (SHA-RNN) ,再加一个softmax分类器。
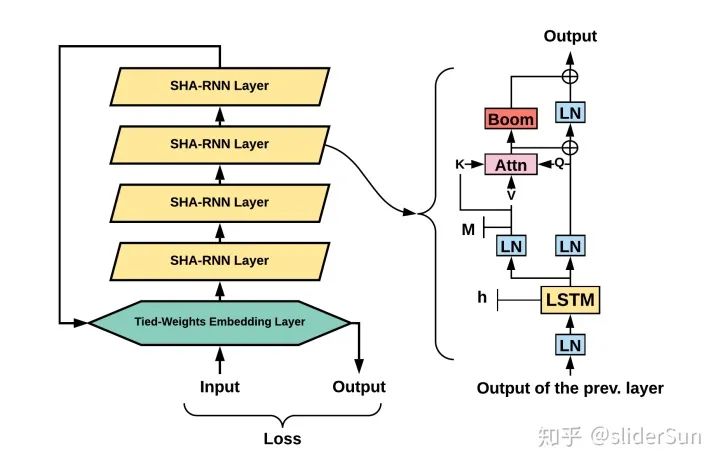
SHA-RNN用的是单头的、基于指针的注意力 (Pointer Based Attention) ,借鉴了2017年作者本人领衔的研究;还包含一个改造过的前馈层,名叫“Boom”,带有层归一化。
SHA-RNN模型的注意力是简化的,只留一个头,唯一的矩阵乘法出现在query (下图Q) 那里,A是缩放点乘注意力 (Scaled Dot-Product Attention) ,是向量之间的运算。

前馈层 (“Boom” Layer) 。用了一个v∈ℝH向量,又用矩阵乘法 (GeLU激活) 得到另一个向量 。然后,把u向量分解成N个向量,再求和,得到 向量。
Low-Rank Factorization-based Multi-Head Attention
论文链接:https://arxiv.org/pdf/1912.00835.pdf
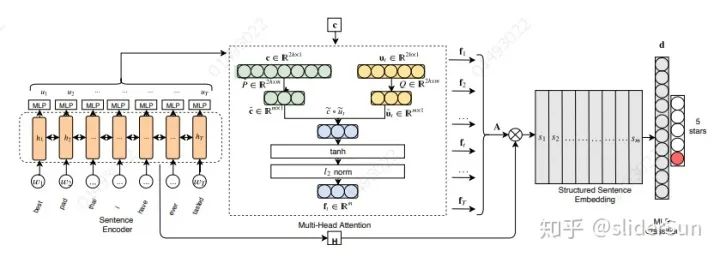
图1描述了模型的架构示意图及其主要组成部分,包括句子提出了多线程注意机制LAMA,结构化句子嵌入,最后提出了MLP分类器。对单个单词的注意力计算进行了演示。
基于低秩分解的多头注意力机制(LAMA)是一种注意模块,它使用低秩分解来降低计算复杂性。它使用低秩双线性池来构造涉及句子多个方面的结构化句子表示。
Convolutional Block Attention Module
代码链接:
https://github.com/Jongchan/attention-modulegithub.com
https://kobiso/CBAM-kerasgithub.com
https://github.com/kobiso/CBAM-tensorflow-slimgithub.com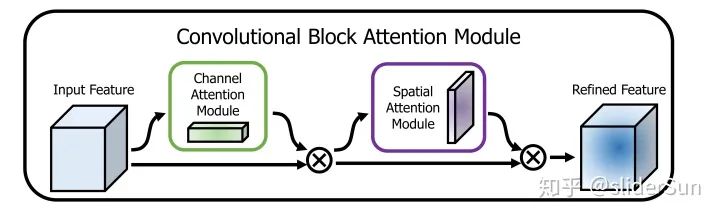
详细介绍参见:https://zhuanlan.zhihu.com/p/65529934
Attention Is All You Need
1、Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention
2、Linformer: Self-Attention with Linear Complexity
3、Reformer: The Efficient Transformer
4、Longformer: The Long-Document Transformer
5、Synthesizer: Rethinking Self-Attention in Transformer Models
6、Sparse Transformer
7、Generating Long Sequences with Sparse Transformers
8、Single Headed Attention RNN: Stop Thinking With Your Head
9、Low Rank Factorization for Compact Multi-Head Self-Attention
10、Convolutional Block Attention Module
11、[Attention Is All You Need(https://arxiv.org/pdf/1706.03762.pdf)
