
Redis突然报错,今晚又不能回家了...
今天在容器环境发布服务,我发誓我就加了一行日志,在点击发布按钮后,我悠闲地掏出泡着枸杞的保温杯,准备来一口老年人大保健......

图片来自 Pexels
正当我一边喝,一边沉思今晚吃点啥的问题时,还没等我想明白,报警系统把我的黄粱美梦震碎成一地鸡毛。
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool

内心激动的我无以言表,但是外表还是得表现镇定,此时我必须的做出选择:回滚or重启。
我也不知道是从哪里来的蜜汁自信,我坚信这跟我没关系,我不管,我就要重启。
时间每一秒对于等待重启过程中的我来说变得无比的慢,就像小时候犯了错,在老师办公室等待父母到来那种感觉。

什么鬼,谁打日志打成这样?当我点开准备看看是哪位大侠打的日志的时候,我惊奇的发现:
***************************
APPLICATION FAILED TO START
***************************
......
......
java.lang.IllegalStateException: Pool not open
Jedis 线程池未初始化。项目既然能去执行定时任务,为什么不去初始化 Redis 相关配置呢?想想都头疼。这里可以给大家留个坑尽管猜。
我们今天的重点不是项目为啥没起来,而是 Redis 那些年都报过哪些错,让你夜不能寐。以下错误都基于 Jedis 客户端。
忘记添加白名单
无法从连接池获取到连接
如果连接池没有可用 Jedis 连接,会等待 maxWaitMillis(毫秒),依然没有获取到可用 Jedis 连接,会抛出如下异常:
redis.clients.jedis.exceptions.JedisException: Could not get a resource from the pool
at redis.clients.util.Pool.getResource(Pool.java:51)
at redis.clients.jedis.JedisPool.getResource(JedisPool.java:226)
at com.yy.cs.base.redis.RedisClient.zrangeByScoreWithScores(RedisClient.java:2258)
......
java.util.NoSuchElementException: Timeout waiting for idle object
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:448)
at org.apache.commons.pool2.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:362)
at redis.clients.util.Pool.getResource(Pool.java:49)
at redis.clients.jedis.JedisPool.getResource(JedisPool.java:226)
......
连接池配置有问题
连接池没问题,使用有问题
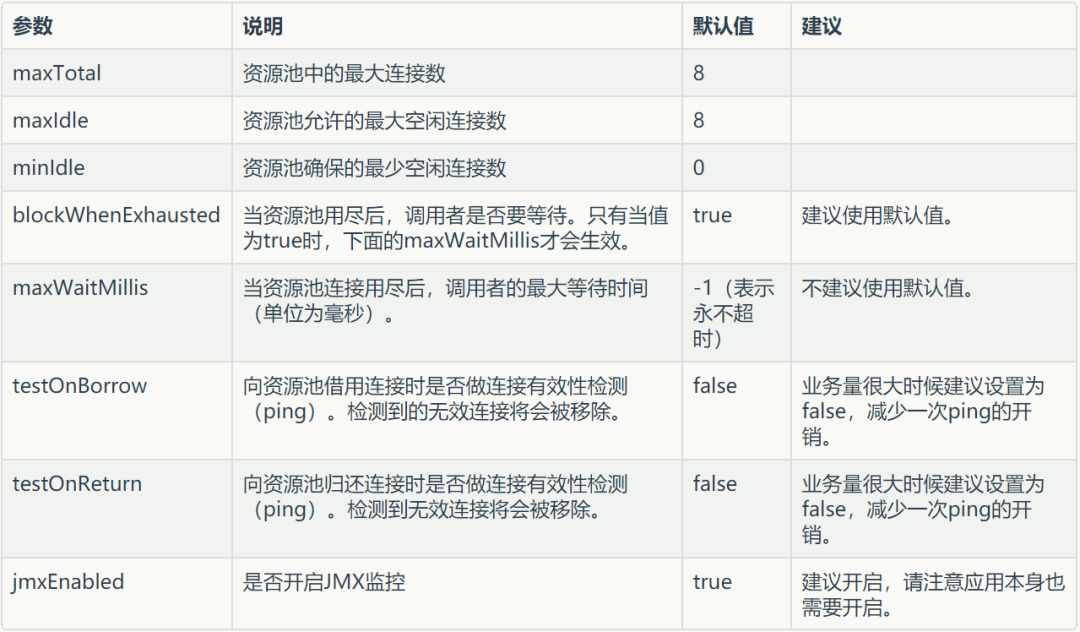
连接池配置
Jedis Pool 有如下参数可以配置:
使用有问题
比如有这么一段代码:
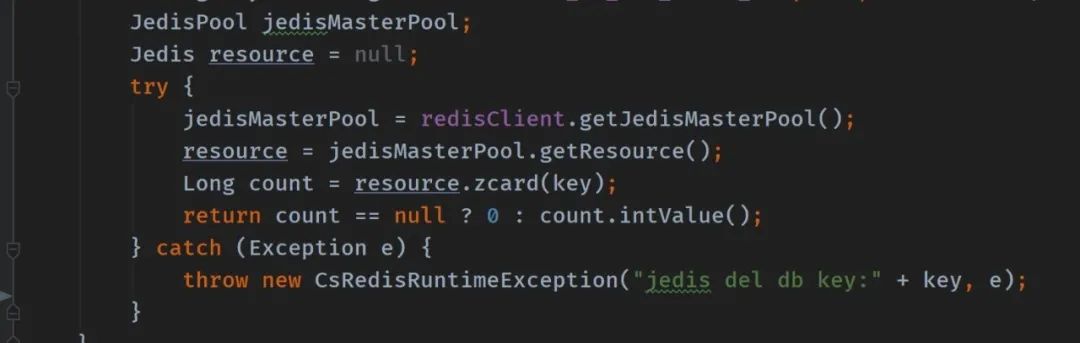
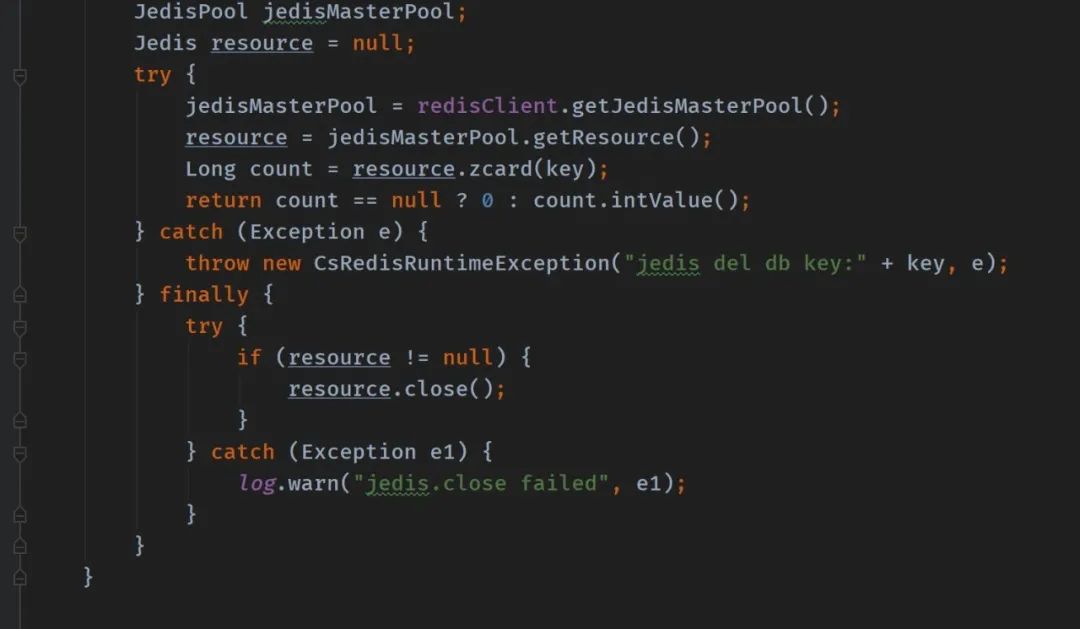
多个线程使用同一个 Jedis 连接
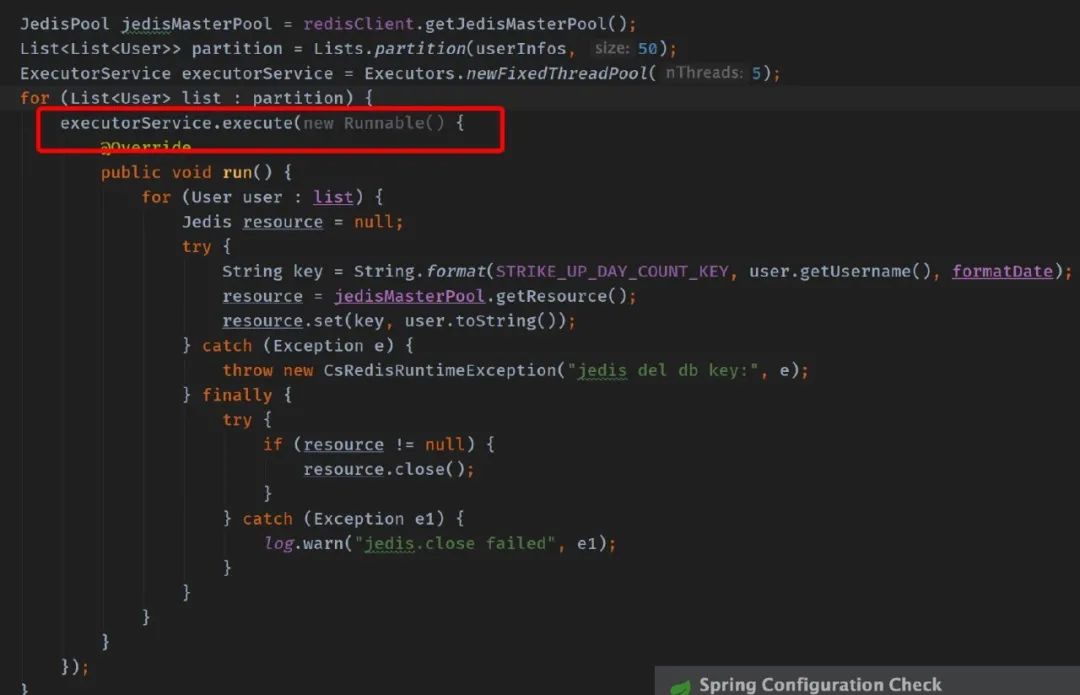
这段代码乍看是不是感觉良好,不过你跑起来了之后就知道有多痛苦:
redis.clients.jedis.exceptions.JedisConnectionException: Unexpected end of stream.
at redis.clients.util.RedisInputStream.ensureFill(RedisInputStream.java:199)
at redis.clients.util.RedisInputStream.readByte(RedisInputStream.java:40)
at redis.clients.jedis.Protocol.process(Protocol.java:151)
......
类型转换错误
这种错误虽然很低级,但是出现的几率还不低。
java.lang.ClassCastException: com.test.User cannot be cast to com.test.User
at redis.clients.jedis.Connection.getBinaryMultiBulkReply(Connection.java:199)
at redis.clients.jedis.Jedis.hgetAll(Jedis.java:851)
at redis.clients.jedis.ShardedJedis.hgetAll(ShardedJedis.java:198)
客户端读写超时
出现客户端读超时的原因很多,这种情况就要综合来判断。
redis.clients.jedis.exceptions.JedisConnectionException:
java.net.SocketTimeoutException: Read timed out
......
首先检查读写超时时间是否设置的过短,如果确定设置的很短,调大一点观察一下效果。
其次检查出现超时的命名是否本身执行较大的存储或者拉数据任务。如果数据量过大,那么就要考虑做业务拆分。
前面这两项如果还不能确定,那么就要检查一下网络问题,确定当前业务主机和 Redis 服务器主机是否在同机房,机房质量怎么样。
机房质量如果还是没问题,那能做的就是检查当前业务中 Redis 读写是否发生有可能发生阻塞,是否业务量大到这种程度,是否需要扩容。
大 Key 造成的 CPU 飙升
Too Many Cluster Redirections
这个错误信息一般在 cluster 环境中出现,主要原因还是单机出现了命令堆积。
redis.clients.jedis.exceptions.JedisClusterMaxRedirectionsException: Too many Cluster redirections?
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:97)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:152)
at redis.clients.jedis.JedisClusterCommand.runWithRetries(JedisClusterCommand.java:131)
at redis.clients.jedis.JedisClusterCommand.run(JedisClusterCommand.java:30)
at redis.clients.jedis.JedisCluster.get(JedisCluster.java:81)
集群环境中 client 先通过key 计算 slot,然后查询 slot 对应到哪个服务器,假设这个 slot 对应到 server1,那么就去请求 server1。
此时如果 server1 整由于执行慢命令而被阻塞且 TCP 队列也已满,那么新来的请求就会直接被拒绝。
client 以为是 server1不可用,随即请求另一个服务器 server2。server2 检查到该 slot 由 server1 负责且 server1 心跳检查正常,所以告诉 client 你还是去找 server1 吧。
client 又来请求 server1,但是 server1 此时还是阻塞中,又回到 3。当请求的次数超过拒绝服务次数之后,就会抛出异常。
再次说明,大命令要不得。对于这种错误,最首要的就是要优化存储结构或者获取数据方式。其次,增加 TCP 队列长度。再次,扩容也是可以解决的。
集群扩容之后找不到 Key
redis-master001~redis-master006
redis-slave001~redis-slave006
之前 Redis 集群的 16384 个槽均匀分配在 6 台主节点中,每个节点 2730 个槽。
为保证扩容后,槽依然均匀分布,需要将之前 6 台的每台机器上迁移出 910 个槽,方案如下:
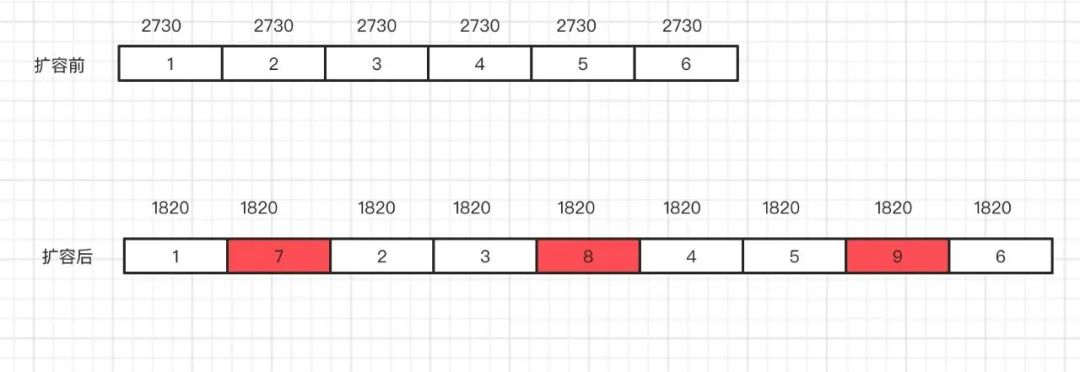
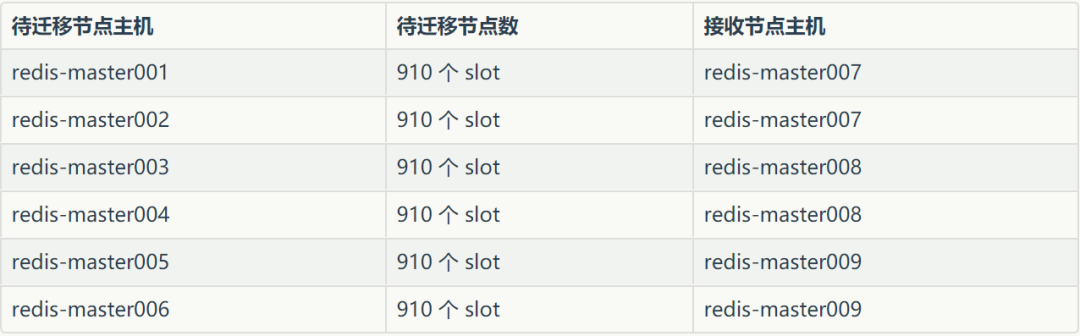
分配完之后,每台节点 1820 个 slot。迁移完数据之后,开始报如下异常:
Exception in thread "main" redis.clients.jedis.exceptions.JedisMovedDataException: MOVED 1539 34.55.8.12:6379
at redis.clients.jedis.Protocol.processError(Protocol.java:93)
at redis.clients.jedis.Protocol.process(Protocol.java:122)
at redis.clients.jedis.Protocol.read(Protocol.java:191)
at redis.clients.jedis.Connection.getOne(Connection.java:258)
at redis.clients.jedis.ShardedJedisPipeline.sync(ShardedJedisPipeline.java:44)
at org.hu.e63.MovieLens21MPipeline.push(MovieLens21MPipeline.java:47)
at org.hu.e63.MovieLens21MPipeline.main(MovieLens21MPipeline.java:53
我们看一下代码:
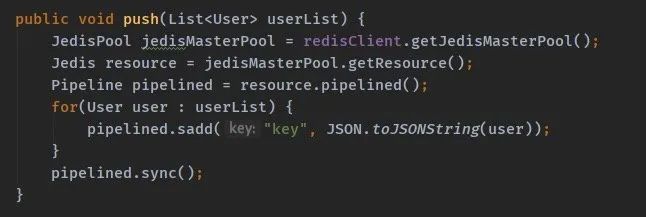
所以我们用错了 API。如果在集群模式下要使用 JedisCluster API,示例代码如下:
JedisPoolConfig config = new JedisPoolConfig();
//可用连接实例的最大数目,默认为8;
//如果赋值为-1,则表示不限制,如果pool已经分配了maxActive个jedis实例,则此时pool的状态为exhausted(耗尽)
private Integer MAX_TOTAL = 1024;
//控制一个pool最多有多少个状态为idle(空闲)的jedis实例,默认值是8
private Integer MAX_IDLE = 200;
//等待可用连接的最大时间,单位是毫秒,默认值为-1,表示永不超时。
//如果超过等待时间,则直接抛出JedisConnectionException
private Integer MAX_WAIT_MILLIS = 10000;
//在borrow(用)一个jedis实例时,是否提前进行validate(验证)操作;
//如果为true,则得到的jedis实例均是可用的
private Boolean TEST_ON_BORROW = true;
//在空闲时检查有效性, 默认false
private Boolean TEST_WHILE_IDLE = true;
//是否进行有效性检查
private Boolean TEST_ON_RETURN = true;
config.setMaxTotal(MAX_TOTAL);
config.setMaxIdle(MAX_IDLE);
config.setMaxWaitMillis(MAX_WAIT_MILLIS);
config.setTestOnBorrow(TEST_ON_BORROW);
config.setTestWhileIdle(TEST_WHILE_IDLE);
config.setTestOnReturn(TEST_ON_RETURN);
Set jedisClusterNode = new HashSet();
jedisClusterNode.add(new HostAndPort("192.168.0.31", 6380));
jedisClusterNode.add(new HostAndPort("192.168.0.32", 6380));
jedisClusterNode.add(new HostAndPort("192.168.0.33", 6380));
jedisClusterNode.add(new HostAndPort("192.168.0.34", 6380));
jedisClusterNode.add(new HostAndPort("192.168.0.35", 6380));
JedisCluster jedis = new JedisCluster(jedisClusterNode, 1000, 1000, 5, config);
Redis 正确使用小技巧
①正确设置过期时间
如果你设置了过期时间,但是又设置了特别长,比如两个月,那么带来的问题就是极有可能你的数据不一致问题会变得特别棘手。

②批量操作使用 Pipeline 或者 Lua 脚本
③大对象尽量使用序列化或者先压缩再存储
④Redis 服务器部署尽量与业务机器同机房
Redis 服务器内存分配策略的选择:
首先我们使用 info 命令来查看一下当前内存分配中都有哪些指标:
info
$2962
# Memory
used_memory:325288168
used_memory_human:310.22M #数据使用内存
used_memory_rss:337371136
used_memory_rss_human:321.74M #总占用内存
used_memory_peak:327635032
used_memory_peak_human:312.46M #峰值内存
used_memory_peak_perc:99.28%
used_memory_overhead:293842654
used_memory_startup:765712
used_memory_dataset:31445514
used_memory_dataset_perc:9.69%
total_system_memory:67551408128
total_system_memory_human:62.91G # 操作系统内存
used_memory_lua:43008
used_memory_lua_human:42.00K
maxmemory:2147483648
maxmemory_human:2.00G
maxmemory_policy:allkeys-lru # 内存超限时的释放空间策略
mem_fragmentation_ratio:1.04 # 内存碎片率(used_memory_rss / used_memory)
mem_allocator:jemalloc-4.0.3 # 内存分配器
active_defrag_running:0
lazyfree_pending_objects:0
https://matt.sh/redis-quicklist
保存 200 个列表,每个列表有 100 万的数字,使用 jemalloc 的碎片率为 3%,共使用 12.1GB 内存,而使用 libc 时,碎片率为 33%,使用了 17.7GB 内存。
小结
作者:杨越
简介:目前就职广州欢聚时代,专注音视频服务端技术,对音视频编解码技术有深入研究。日常主要研究怎么造轮子和维护已经造过的轮子,深耕直播类 APP 多年,对垂直直播玩法和应用有广泛的应用经验,学习技术不局限于技术,欢迎大家一起交流。
编辑:陶家龙
后台回复 学习资料 领取学习视频
如有收获,点个在看,诚挚感谢