
Redis 突然变慢了如何排查并解决?
Redis 通常是我们业务系统中一个重要的组件,比如:缓存、账号登录信息、排行榜等。
一旦 Redis 请求延迟增加,可能就会导致业务系统“雪崩”。
我在单身红娘婚恋类型互联网公司工作,在双十一推出下单就送女朋友的活动。
谁曾想,凌晨 12 点之后,用户量暴增,出现了一个技术故障,用户无法下单,当时老大火冒三丈!
经过查找发现 Redis 报 Could not get a resource from the pool。
获取不到连接资源,并且集群中的单台 Redis 连接量很高。
大量的流量没了 Redis 的缓存响应,直接打到了 MySQL,最后数据库也宕机了……
于是各种更改最大连接数、连接等待数,虽然报错信息频率有所缓解,但还是持续报错。
后来经过线下测试,发现存放 Redis 中的字符数据很大,平均 1s 返回数据。
可以发现,一旦 Redis 延迟过高,会引发各种问题。
今天跟大家一起来分析下如何确定 Redis 有性能问题和解决方案。
目录
延迟基线测量 慢指令监控 慢日志功能 Latency Monitoring 网络通信导致的延迟 慢指令导致的延迟 Fork 生成 RDB 导致的延迟 内存大页(transparent huge pages) swap:操作系统分页 获取 Redis 实例 pid 解决方案 AOF 和磁盘 I/O 导致的延迟 expires 淘汰过期数据 解决方案 bigkey 查找 bigkey 解决方案
Redis 性能出问题了么?
延迟基线测量
–intrinsic-latency 选项,用来监测和统计测试期间内的最大延迟(以毫秒为单位),这个延迟可以作为 Redis 的基线性能。redis-cli --latency -h `host` -p `port`
redis-cli --intrinsic-latency 100
Max latency so far: 4 microseconds.
Max latency so far: 18 microseconds.
Max latency so far: 41 microseconds.
Max latency so far: 57 microseconds.
Max latency so far: 78 microseconds.
Max latency so far: 170 microseconds.
Max latency so far: 342 microseconds.
Max latency so far: 3079 microseconds.
45026981 total runs (avg latency: 2.2209 microseconds / 2220.89 nanoseconds per run).
Worst run took 1386x longer than the average latency.
100是测试将执行的秒数。我们运行测试的时间越长,我们就越有可能发现延迟峰值。-h host -p port 来连接服务端,如果想监测网络对 Redis 的性能影响,可以使用 Iperf 测量客户端到服务端的网络延迟。慢指令监控
O(N)。官方文档对每个命令的复杂度都有介绍,尽可能使用O(1) 和 O(log N)命令。O(N),比如集合全量查询HGETALL、SMEMBERS,以及集合的聚合操作:SORT、LREM、 SUNION等。使用 Redis 慢日志功能查出慢命令; latency-monitor(延迟监控)工具。
慢日志功能
redis-cli CONFIG SET slowlog-log-slower-than 6000
示例:获取最近2个慢查询命令
127.0.0.1:6381> SLOWLOG get 2
1) 1) (integer) 6
2) (integer) 1458734263
3) (integer) 74372
4) 1) "hgetall"
2) "max.dsp.blacklist"
2) 1) (integer) 5
2) (integer) 1458734258
3) (integer) 5411075
4) 1) "keys"
2) "max.dsp.blacklist"
字段 1:1 个整数,表示这个 slowlog 出现的序号,server 启动后递增,当前为 6。 字段 2:表示查询执行时的 Unix 时间戳。 字段 3:表示查询执行微秒数,当前是 74372 微秒,约 74ms。 字段 4: 表示查询的命令和参数,如果参数很多或很大,只会显示部分参数个数。当前命令是 hgetall max.dsp.blacklist。
Latency Monitoring
CONFIG SET latency-monitor-threshold 9
127.0.0.1:6379> debug sleep 2
OK
(2.00s)
127.0.0.1:6379> latency latest
1) 1) "command"
2) (integer) 1645330616
3) (integer) 2003
4) (integer) 2003
事件的名称; 事件发生的最新延迟的 Unix 时间戳; 毫秒为单位的时间延迟; 该事件的最大延迟。
如何解决 Redis 变慢?
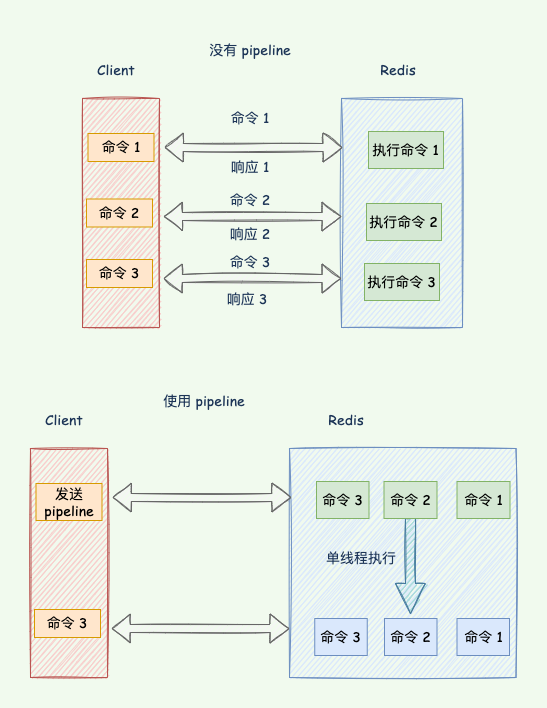
网络通信导致的延迟
慢指令导致的延迟
比如在 Cluster 集群中,将聚合运算等 O(N) 操作运行在 slave 上,或者在客户端完成。 使用高效的命令代替。使用增量迭代的方式,避免一次查询大量数据,具体请查看SCAN、SSCAN、HSCAN和ZSCAN命令。
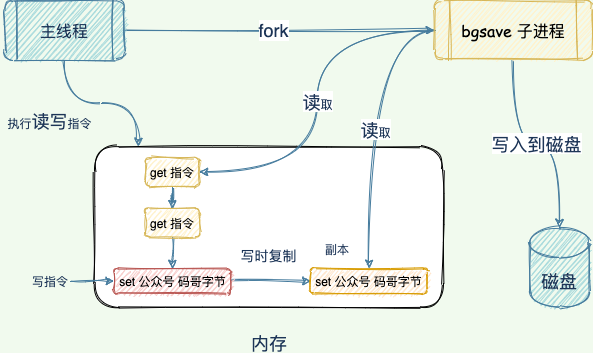
Fork 生成 RDB 导致的延迟
内存大页(transparent huge pages)
echo never > /sys/kernel/mm/transparent_hugepage/enabled
swap:操作系统分页
Redis 使用了比可用内存更多的内存; 与 Redis 在同一机器运行的其他进程在执行大量的文件读写 I/O 操作(包括生成大文件的 RDB 文件和 AOF 后台线程),文件读写占用内存,导致 Redis 获得的内存减少,触发了 swap。
获取 Redis 实例 pid
$ redis-cli info | grep process_id
process_id:13160
cd /proc/13160
$ cat smaps | egrep '^(Swap|Size)'
Size: 316 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 8 kB
Swap: 0 kB
Size: 40 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 720896 kB
Swap: 12 kB
解决方案
增加机器内存; 将 Redis 放在单独的机器上运行,避免在同一机器上运行需要大量内存的进程,从而满足 Redis 的内存需求; 增加 Cluster 集群的数量分担数据量,减少每个实例所需的内存。
AOF 和磁盘 I/O 导致的延迟
redis-cli CONFIG SET appendfsync no)。no:Redis 不执行 fsync,唯一的延迟来自于 write 调用,write 只需要把日志记录写到内核缓冲区就可以返回。 everysec:Redis 每秒执行一次 fsync。使用后台子线程异步完成 fsync 操作。最多丢失 1s 的数据。 always:每次写入操作都会执行 fsync,然后用 OK 代码回复客户端(实际上 Redis 会尝试将同时执行的许多命令聚集到单个 fsync 中),没有数据丢失。在这种模式下,性能通常非常低,强烈建议使用快速磁盘和可以在短时间内执行 fsync 的文件系统实现。
no-appendfsync-on-rewrite设置为 yes,表示在 AOF 重写时,不进行 fsync 操作。expires 淘汰过期数据
惰性删除:当接收请求的时候发现 key 已经过期,才执行删除; 定时删除:每 100 毫秒删除一些过期的 key。
随机采样 A CTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP个数的 key,删除所有过期的 key;如果发现还有超过 25% 的 key 已过期,则执行步骤一。
ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP默认设置为 20,每秒执行 10 次,删除 200 个 key 问题不大。解决方案
EXPIREAT 和 EXPIRE 的过期时间参数上,加上一个一定大小范围内的随机数,这样,既保证了 key 在一个邻近时间范围内被删除,又避免了同时过期造成的压力。bigkey
一个 STRING 类型的 Key,它的值为 5MB(数据过大) 一个 LIST 类型的 Key,它的列表数量为 10000 个(列表数量过多) 一个 ZSET 类型的 Key,它的成员数量为 10000 个(成员数量过多) 一个 HASH 格式的 Key,它的成员数量虽然只有 1000 个但这些成员的 value 总大小为 10MB(成员体积过大)
Redis 内存不断变大引发 OOM,或者达到 maxmemory 设 置值引发写阻塞或重要 Key 被逐出; Redis Cluster 中的某个 node 内存远超其余 node,但因 Redis Cluster 的数据迁移最小粒度为 Key 而无法将 node 上的内存均衡化; bigkey 的读请求占用过大带宽,自身变慢的同时影响到该服务器上的其它服务; 删除一个 bigkey 造成主库较长时间的阻塞并引发同步中断或主从切换;
查找 bigkey
解决方案
对大 key 拆分
异步清理大 key
总结
获取当前 Redis 的基线性能; 开启慢指令监控,定位慢指令导致的问题; 找到慢指令,使用 scan 的方式; 将实例的数据大小控制在 2-4GB,避免主从复制加载过大 RDB 文件而阻塞; 禁用内存大页,采用了内存大页,生成 RDB 期间,即使客户端修改的数据只有 50B 的数据,Redis 需要复制 2MB 的大页。当写的指令比较多的时候就会导致大量的拷贝,导致性能变慢。 Redis 使用的内存是否过大导致 swap; AOF 配置是否合理,可以将配置项 no-appendfsync-on-rewrite 设置为 yes,避免 AOF 重写和 fsync 竞争磁盘 IO 资源,导致 Redis 延迟增加。 bigkey 会带来一系列问题,我们需要进行拆分防止出现 bigkey,并通过 UNLINK 异步删除。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️