
惊!不可以貌取 SQL

图 | Lenis
生活中,我们被很多好看的皮囊骗过。
看着宝强在《唐探》系列中的表现,不禁替他悲伤。如此撇下面子,卖力为家的男人,也会在皮相上受尽耻辱。
回头想想,我们 SQL Boy/Girl 也曾被优雅的 SQL 表象迷倒!
在追求格式好看,逻辑简单的句法下,却忘记对系统的怜悯。格式简单易懂的 SQL,杀起资源来,毫不手软。
落落曾写过这样一则案例:
SQL> select * from
(
select
GRDL_ID qyid,
KHMC nsrmc,
KHBM nsrsbh,
KHBM six_nsrsbh,
'' six_dssh,
gjc,
fzgs_dm,
'2' khlx
from
khgl_grdlxx
union all
select
dwkh_id qyid,
khmc nsrmc,
nvl(nsrsbh, dssh) nsrsbh,
nvl(six_nsrsbh, six_dssh) six_nsrsbh,
six_dssh,
gjc,
fzgs_dm,
'0' khlx
from
KHGL_DWKH_COREINFO
union all
select
DLS_BM qyid,
DLS_MC nsrmc,
DLS_BM nsrsbh,
DLS_BM six_nsrsbh,
'' six_dssh,
gjc,
fzgs_dm,
'1' khlx
from
KHGL_DLSJBXX
)
where (six_nsrsbh = '706773' or six_dssh = '706773') and rownum<11
QYID NSRMC
a4af925f2a224bc4a8ac42dc87bb5192 农一师塔里木广告信息公司
b59f82aa67ae4b88b331a4042e1ced43 保定市丽景园林绿化有限公司
6db2f2cc8d8446a2b80f190fffd1ff72 保定市绿景园林绿化有限公司
本是简单的三段 UNION ALL, 句式清晰,逻辑易懂,就像现在活跃在荧幕上的少年,干干净净,楚楚动人。
谁能想到,这样的 SQL 却把数据库跑垮?
本例出自落总的书《SQL优化核心思想》,第7章,谓词推入(Pushing Predicate)。若不注意,根本不会留意, 落总在这一章,埋下这样一个例子,来解释为什么我们要注意谓词推入的技巧。
首先,解释下谓词推入的前提。
请看下面这段 SQL:
select
e.first_name,
e.last_name,
dept_locs_v.street_address,
dept_locs_v.postal_code
from
employees e,
(
select
d.department_id,
d.department_name,
l.street_address,
l.postal_code
from
departments d,
locations l
where
d.location_id = l.location_id
) dept_locs_v
where
dept_locs_v.department_id = e.department_id
and e.last_name = 'Smith';
如果你对执行计划好奇,又或者了解些,那么请你来猜一下,下面哪个才是上面这段 SQL 的执行计划?
A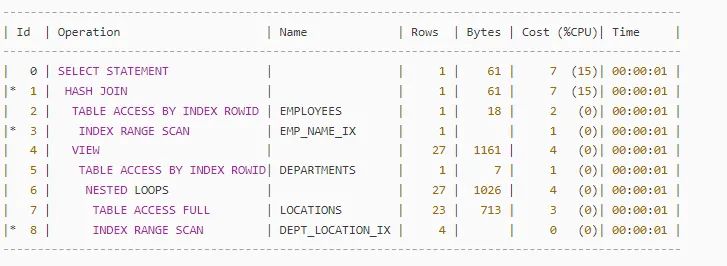
B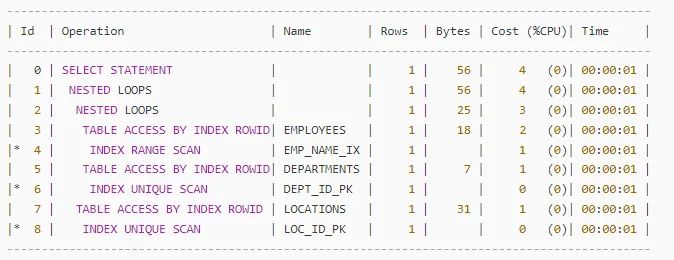
A 计划,从 SQL 格式看,似乎更符合逻辑。把 locations, departments 通过 Nested Loop 连接到一起,最后和 employees 做 Hash Join.
而 B 计划,把 employees 和 departments 通过 Nested Loop 连接到一起,似乎是不符合逻辑,怎么优化器还能拆表呢?
但,答案是 B.
看似不符合逻辑的事情,其实是 Oracle 做的视图合并( View Merging). 属于优化常用策略。
那和谓词下推有什么关系呢?有!视图合并,有时会失效。
把上面的 SQL 改写如下:
select
e.first_name,
e.last_name,
dept_locs_v.street_address,
dept_locs_v.postal_code
from
employees e,
(
select
rownum,
d.department_id,
d.department_name,
l.street_address,
l.postal_code
from
departments d,
locations l
where
d.location_id = l.location_id
order by 2
) dept_locs_v
where
dept_locs_v.department_id = e.department_id
and e.last_name = 'Smith';
这段SQL中,使用 rownum,导致视图合并优化失效:
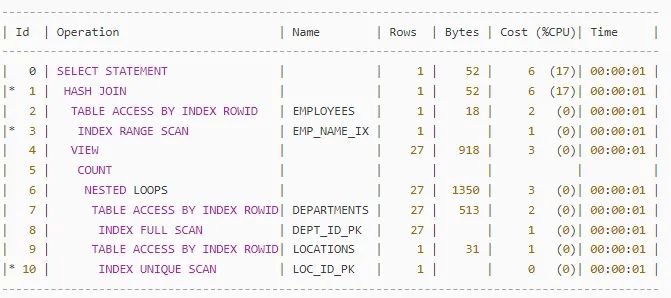
明明只需要查找1条数据,却需要花费查询27条数据的时间。
经查看 Oracle 文档,当子查询使用下面这些操作符,不能进行视图合并:
SET 集合操作,如:union, union all, intersact, minus Aggregation 聚合: avg, sum, count, max, min Rownum Connect by Group by (修改 _complex_view_merging 为true, 可能有机会合并) Distinct (修改 _complex_view_merging 为true, 可能有机会合并)
当优化器不能做视图合并时,谓词下推(Predicate Pushing) 就上场了
比如下面这条 SQL :
select
/*+ no_merge(v) */
d.loc,
v.avg_sal
from
dept d,
(
select
e.deptno,
avg(e.sal) avg_sal,
min(e.sal) min_sal,
max(e.sal) max_sal
from
emp e
group by
e.deptno
) v
where
d.deptno = v.deptno
and v.deptno = 20;
使用 /*+ no_merge(v) */ Hint告诉优化器,不能合并试图。
让我们猜想下,优化器会做什么?参考上面的例子,子查询使用了 Aggregation 操作:avg, min, max,优化器肯定不能进行视图合并。
也就是,v.deptno = 20 不能传递给 emp 去做过滤条件。由此导致的结果一定是,先对 emp 做全表扫描,按照 deptno 做分组,最后再选出 deptno = 20 的聚合记录。白白浪费全表扫表的时间。
但,事实出乎你的意料。
在合并试图失败后,优化器选择了谓词推入。同样使得 emp 也优先在 Group by 之前做了过滤。
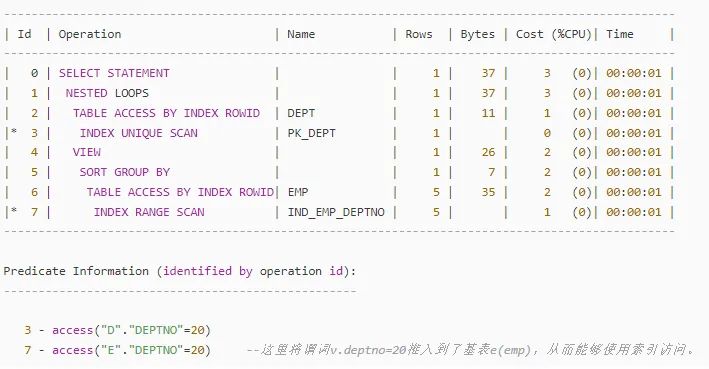
由此,回到开头的那段 SQL,该怎么做优化呢?
该多写的部分一点儿,都逃不得。既然优化器不能识别谓词下推的情况,我们可以帮它补足。
select
*
from
(
select
GRDL_ID qyid,
KHMC nsrmc,
KHBM nsrsbh,
KHBM six_nsrsbh,
'' six_dssh,
gjc,
fzgs_dm,
'2' khlx
from
khgl_grdlxx
where
KHBM = '706773'
union
all
select
dwkh_id qyid,
khmc nsrmc,
nvl(nsrsbh, dssh) nsrsbh,
nvl(six_nsrsbh, six_dssh) six_nsrsbh,
six_dssh,
gjc,
fzgs_dm,
'0' khlx
from
KHGL_DWKH_COREINFO
where
(
six_nsrsbh = '706773'
or six_dssh = '706773'
)
union
all
select
DLS_BM qyid,
DLS_MC nsrmc,
DLS_BM nsrsbh,
DLS_BM six_nsrsbh,
'' six_dssh,
gjc,
fzgs_dm,
'1' khlx
from
KHGL_DLSJBXX
where
DLS_BM = '706773'
) t
where
rownum < 11;
虽然看着冗繁,但性能杠杠滴~
参考:
- https://blog.csdn.net/aqszhuaihuai/article/details/7798076
- https://blog.csdn.net/robinson1988/article/details/6613851

推荐阅读
欢迎长按扫码关注「数据管道」