
大型前端项目架构优化探索之路-腾讯文档表格
腾讯文档表格是一个非常复杂的业务,它实现了传统 excel 的大部分核心功能,包括函数计算、条件格式、图表、智能分列等;除此之外还支持高效的多人协同编辑;它的代码量百万级别,启动也流程多达十几步。在前端领域,能达到这种规模的项目应该还是比较少的。
腾讯文档表格业务不仅代码规模庞大,模块间依赖关系也很复杂;由于业务的特殊性导致模块间天然有较强的依赖关系;比如改动一个单元格的内容,可能触发包括函数计算、图表渲染等多个模块的逻辑执行。
由于大部分前端项目相对较小,我们日常开发中可能意识不到大量模块耦合带来的问题;往往是直接在代码里硬编码依赖关系;比如我使用 A、B、C 三个模块完成一个功能,只需要手动 new 三个模块就行了,看起来很简单。
logic(){const a = new A();const b = new B();const c = new C();a.do();b.do();c.do();}
项目的规模比较小,代码量很少时,我们的代码或许整体上看起来还很干净。就像一个小型机房,只有几交换机,每台交换机用网线互相连接;即便我们不对它们进行额外的管理,也不会显得混乱。

但如果我们管理的是一个大型数据中心呢,还是不对机器之间的连接进行额外的治理,会是怎么样?对于大型的项目而言,随着功能模块的增加,整个代码库看起来就像这个数据中心一样:

针对这种混乱的局面,如果让我们排查两个机器之间的连接问题是非常困难的。对于大型项目,我们往往会进行一些初步的梳理。
1. 初步梳理
大型项目的模块过多时,我们往往会考虑根据功能进行分层;就比如在线表格项目中,我们把模块分为渲染层、数据层、网络层、以及 feature 层,当然还包括 worker 里的模块:
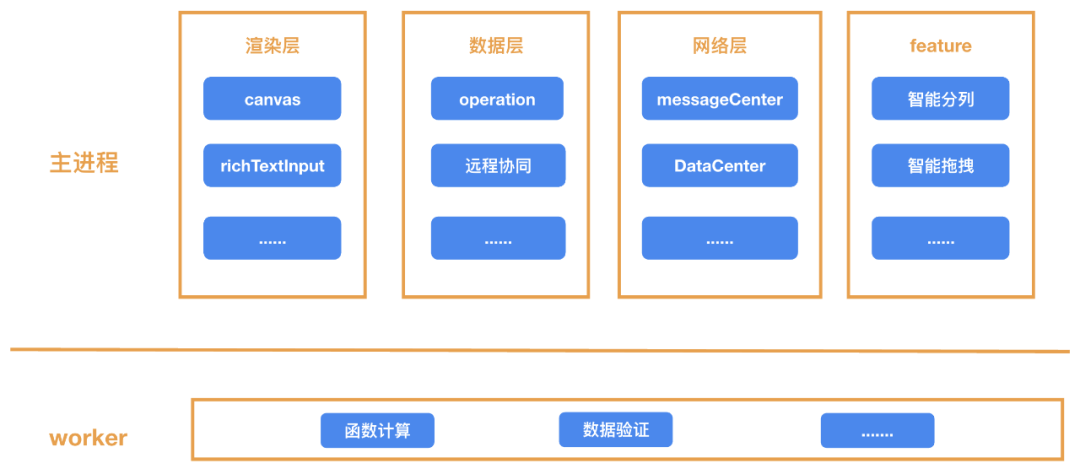
然后对每一个层级,都新建一个单独的目录:
+ src+ dataLayersubModule...+ netLayer+ renderLayer+ feature+ worker
对模块进行分层后,再引入全局变量 globalApp,将各个模块分层次挂载后,
const globalApp = {dataLayer: { subModule... },netLayer: { subModule... },renderLayer: { subModule... },feature: { subModule... },worker: { subModule... }}
就可以直接通过全局变量引用模块,就像 node 里的 global超级对象一样:
logic(){// 调用数据层子模块globalApp.dataLayer.a.doSomething();// 调用网络层子模块globalApp.netLayer.b.doSomething();// 调用渲染层子模块globalApp.renderLayer.c.doSomething();}
这样看,模块的组织貌似还算有条理,很多大型项目都止步于此;在线表格业务在很长一段时间也是这么做的。
但是通过全局 globalApp引用子模块,隐藏了实际的依赖关系,本来应该直接依赖 subModule,现在变成间接通过 globalApp 依赖了 subModule 了;在不了解系统的全貌的情况下,在改模块代码、写模块单测时都变得更困难了。我们必须认真的读代码逻辑,才知道这段代码具体依赖于哪个子模块。除此之外,有些模块是异步模块,通过全局 APP 调用异步模块时,异步模块可能还没初始化好,很容易导致时序问题。
2. 依赖注入/控制反转
为了解决这些问题,我们引入了依赖注入框架来管理依赖。依赖注入的思想在软件设计领域已经非常成熟,但受限于前端项目规模,可能不少前端开发还没有在前端项目中实际使用过。
可以这样理解依赖注入/控制反转:一个模块本来需要接受各种参数来构造一个对象,现在只接受一个参数——已经实例化的对象。对模块来说对对象的『依赖』是注入进来的,而和它的构造方式解耦了。而“构造它”这个『控制』操作也交给了第三方框架,也就是控制反转。
引入依赖注入框架后,模块间没有直接联系。模块就像一个个独立的零部件,放在一个容器里等待装配。一段代码声明了它需要哪些类型(接口)的模块。然后由框架将模块装配起来实现功能。可以将我们声明的依赖关系理解为一份配置,模块容器根据这份配置,为我们装配出各个模块的实际关系,形成一个系统功能。
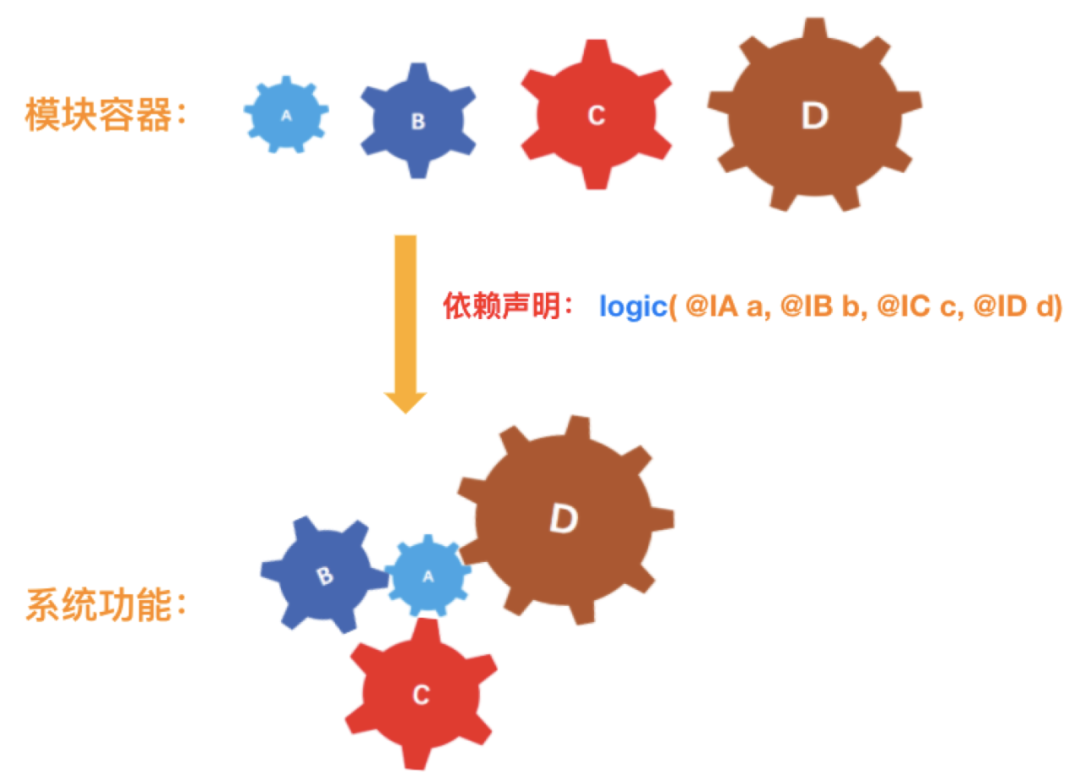
通过这种思路,我们即避免了模块直接强耦合,也解决了手动管理复杂依赖的困境。为了便于理解架构的演进,接下来我们来简要了解一下依赖注入框架的技术细节。
(1) 依赖声明与解析
首先我们将所有的模块放入一个列表中(借鉴至 vscode),每个模块都有一个 ID 和构造器:
模块列表 = [{ IA, A },{ IB, B },];
然后使用 Typescript 的参数装饰器声明依赖的关系:
class X{construction( a, b){}}
参数装饰器为构造函数添加一个元数据属性,用来保存依赖关系:
X.$$DEPS =通过构造函数元数据中保存的依赖关系,查找模块列表就能解析出一个模块的依赖关系图:
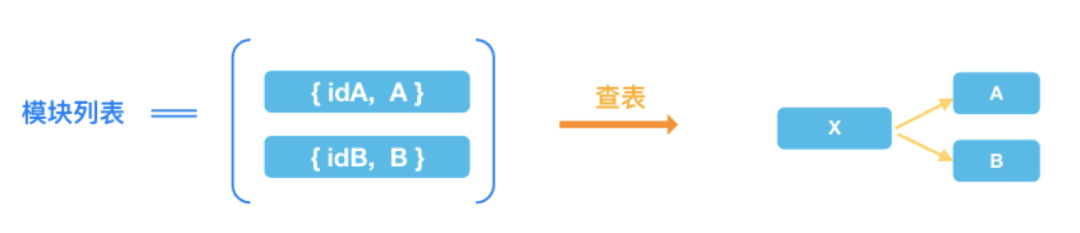
根据模块间声明的依赖关系,进行多次查表,我们就能解析出整个系统的依赖关系图。而依赖图解析完成后,按深度优先遍历的顺序实例化,就能保证初始化时序的正确性。
通过声明式依赖,保证了依赖关系的清晰;框架负责注入依赖实例,保证了模块的解耦,提高可测性和可维护性;框架按依赖图初始化,避免了时序问题。
(2) 延迟初始化模块实例
当模块所依赖的对象实例都是由框架注入,我们还可以做一些有趣的优化:延迟初始化。对于腾讯文档在线表格业务来说,无论有无编辑权限,大部用户打开表格都是为了查看表格,而不会进行编辑。如果大部分用户不编辑表格,我们可以利用依赖注入框架将与编辑功能有关的模块,统一延迟到真正使用时再初始化。比如在线表格业务中的 undoredo 栈,在用户没编辑时就不会初始化,从而达到一定的内存治理的效果。

延迟初始化是如何实现的呢?undoredo 模块的实例是由依赖注入框架提供的,我们可以先注入一个 Proxy 占位:

然后通过 Proxy 拦截实例的属性查找、函数调用,这样就能做到在真正获取属性实例或调用实例的方法时再初始化实例。
const undeoProxy = new Proxy(Object.create(null), {get(target, key) {// 没有实例时,先创建实例if (!this.instance) {this.instance = di.create(Ctor);}// 返回已经缓存的实例return this.instance[key];},});
这套延迟初始化方案,对模块本身是透明的,完全由依赖注入框架通过参数配置有选择的开启。
(3) 异步依赖管理
在线表格代码量在百万级别,模块有上千个;而要在单个页面中加载一百万行代码,我们必须对模块进行异步分批加载。上文提到的依赖注入思路只能支持同步模块,显然无法满足我们的业务需求。举一个我们业务场景中实际的例子:页面在执行到某个生命周期阶段时,需要加载插件系统,而插件系统会加载 workbench 模块,workbench 上的文件导出模块可能在用户正在点击时才触发加载。
 针对这种多层嵌套的异步依赖关系,我们该如何有效的管理呢?为此框架提供了一个通用 loader,通过 loader 就能将一个同步模块包装成异步模块。loader 负责两件事:
针对这种多层嵌套的异步依赖关系,我们该如何有效的管理呢?为此框架提供了一个通用 loader,通过 loader 就能将一个同步模块包装成异步模块。loader 负责两件事:
加载异步模块
解析异步模块的依赖并初始化
假设一个系统中,C 模块异步的依赖于 D 模块,那我们只需要声明 C 对 dLoader 的依赖:
class C {constructor( d: dLoader){} //C模块声明对dLoader的依赖test(){const d = dLoader.getInstance(); //加载并初始化D模块}}
则依赖关系图如下:
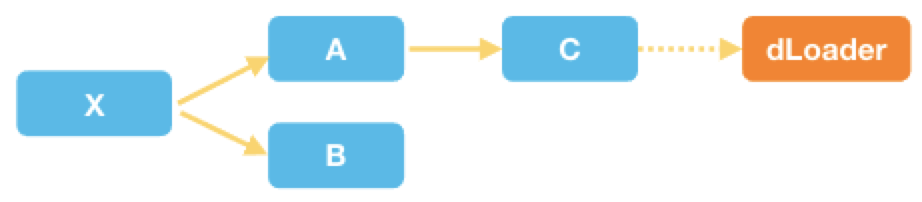
在调用 dLoader.getInstance时会触发对 D 模块的加载,同时解析 D 模块本身的依赖关系,然后再初始化 D 模块。假设 D 模块本身又依赖于 E 模块,则解析出的 D 模块依赖关系图如下:

以 X 为根节点的依赖图包含了 dLoader,但对 D 的依赖图无感知;只有 dLoader 知道 D 模块的依赖图;可以通过 dLoader 作为桥梁,将两部分依赖图链接起来,形成包含同步模块和异步模块的复杂的依赖关系图:

通过引入 Loader,我们屏蔽了同步和异步模块的实现细节;一个模块是同步还是异步,只需要在声明依赖和注册模块时稍有差异。多个 Loader 就可以组装成任意多层嵌套的异步依赖关系图;通过支持同步和异步模块的随意组合,我们就能驾驭真实的复杂场景,而如果要硬编码维护这样复杂的多层嵌套异步依赖关系,是非常容易出问题的。
至此,我们已经探索出一条有效的模块依赖关系治理之路。但架构的优化不会止步于此,业务对架构又提出了新的诉求。
3. 模块分层
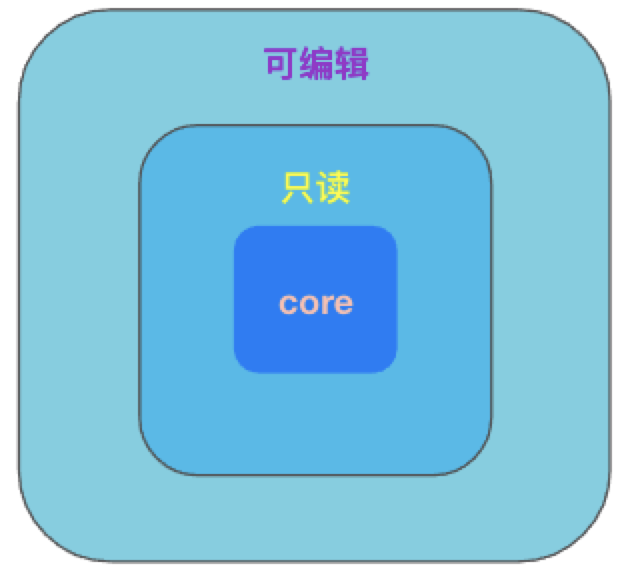
什么是模块分层呢?对在线表格来说,我们将系统分为几个层级:
Core 层提供核心的能力;只读层调用 Core 层的能力实现只读功能;相应的,可编辑层调用只读层和 Core 层的能力,实现可编辑功能
分层的好处是:理想情况下,我们可以随意的替换掉外层,来提供不同的产品能力;而要随意的替换外层,必须保证外层模块不影响内层模块的功能,这就需要做到:
外层模块单向依赖于内层模块,内层模块不能依赖外层模块
因为内层模块如果依赖于外层模块,替换外层就会破坏内层的功能。保证模块分层单向依赖后,假设一个第三方的 APP 只需要在线表格的只读功能,那么我们只需要拿掉可编辑层,封装一个 SDK 提供给第三方 APP 就行了。

为了应对这种诉求,框架也支持多层容器,可以将模块放在不同层级的容器中。比如模块 C 放在可编辑层容器,模块 B 放在只读层容器,模块 A 放在 core 层容器。

外层容器通过 parent 指向内层容器。
editableCollection.parent = readonlyCollection;readonlyCollection.parent = coreCollection;
而在依赖解析时,递归查找父容器
function inCollection(collection, id) {if (colleciton.has(id)) {return true;} else if (colleciton.parent) {//递归的查询入容器return inCollection(colleciton.parent);}return false;}
通过这种单向的递归依赖解析,我们就做到了层级间模块单向可见:
inCollection(editableCollection, A) === true;inCollection(coreCollection, B) === false;
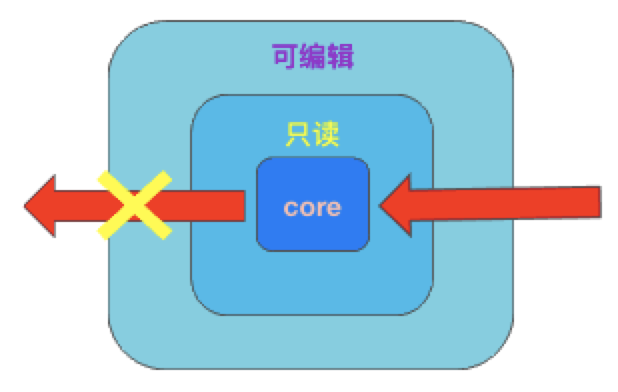
预先将模块放入不同层级的容器中,对于违背单向依赖规则的模块则抛出异常
比如我们的 A 模块是负责图表绘制的核心模块,而 B 模块是负责错误上报的非核心模块(与具体的日志平台耦合)。理论上来说,为了保证 A 模块的高可用性,A 模块不应该依赖于特殊的业务模块,即错误上报模块 B。而在一个代码库中的模块,如何防止这种情况出现呢?传统的方法是 CodeReview,而最好的办法就是利用容器分层单向依赖关系,在运行时抛出异常,强制业务开发不能这么使用。
4. 模块生命周期管理
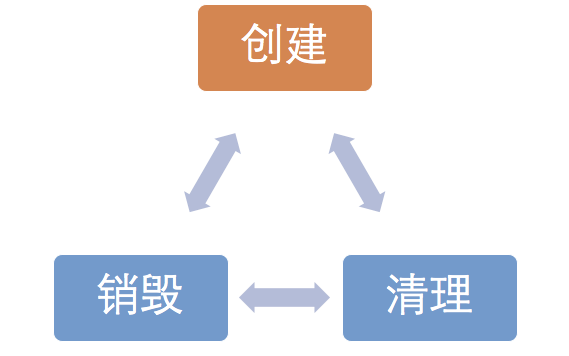
模块的生命周期包括创建、销毁、清理。大部分其他架构只考虑根据依赖关系创建模块,极少考虑到模块的清理、销毁、以及销毁后的重建。接下来我们继续探索一下我们的框架是如何管理模块的销毁和清理的。
为什么需要管理模块的生命周期呢?对应我们的要业务来说:比如删除子表时,对应子表的实例就应该可靠的销毁,否则会有内存泄露的问题。
(1)模块实例的销毁
模块的销毁就是直接删除模块的实例。我们首先考虑模块的销毁难在哪里?假设一个模块依赖图,包括了复杂的同步、异步依赖组成的关系网。
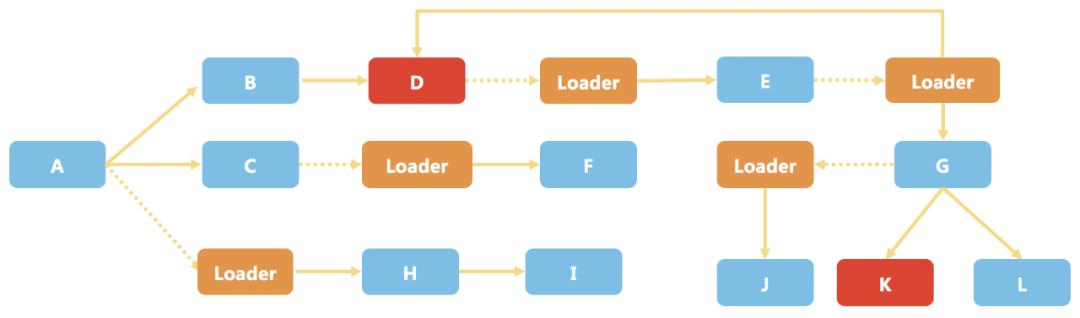
我们要保证销毁部分模块后,还能重建整个依赖关系网,系统功能还是正常的。比如标红的 D 和 K 模块,它们都是要被销毁的模块,但是它们都被其他模块引用了。模块被引用,如何可靠的销毁呢?
一种解决思路是:对于需要销毁的模块,我们生成一个 Scoped Wrapper,其他模块通过 Wrapper 引用该模块,保证模块的真实实例没有被外部直接引用,这样就能安全的销毁掉模块实例。销毁后,其他模块通过 Wrapper 调用该模块的方法时,会触发通过 DI 框架重新初始化该模块,从而达到安全的重新初始化。
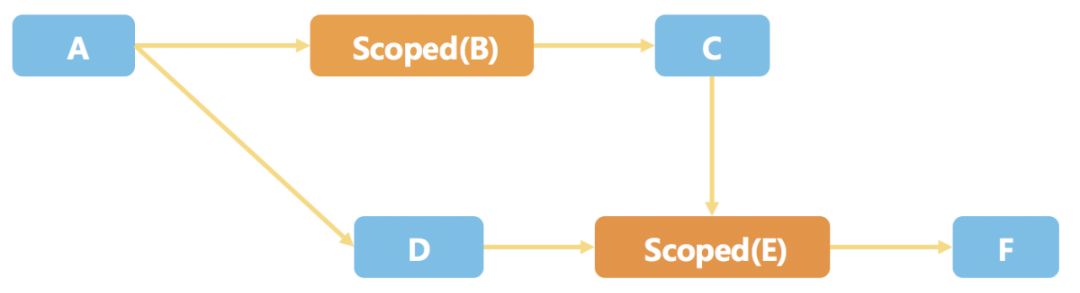
这样就做到了:
只销毁掉依赖关系图中的部分模块的实例,同时保留了其他模块的实例。
(2)模块实例的清理
模块实例的清理往往是为了清理实例的状态,这些状态包括:设置的 timer、pending 状态的 Promise、插入的 DOM 节点、自定义的事件等。
假设我们有 a、b、c、d、e、f、g 六个模块实例需要清理。
一种常见方法是:各个模块是平级关系,全局抛出一个事件(dispose),各个模块都监听这个事件,执行自己的清理工作,各人自扫门前雪。
onDispose(()=>{a.dispose();});...onDispose(()=>{f.dispose();});
这种方式对业务模块入侵较大,每个实现模块的都必须监听一个全局事件;此外,清理工作分散在各个模块中,很容易因为疏忽导致泄露。
另外一种方案是:各个模块实现统一的清理接口,负责自身状态的清理;同时把自己的清理接口的调用委托给父节点,形成一个清理树:
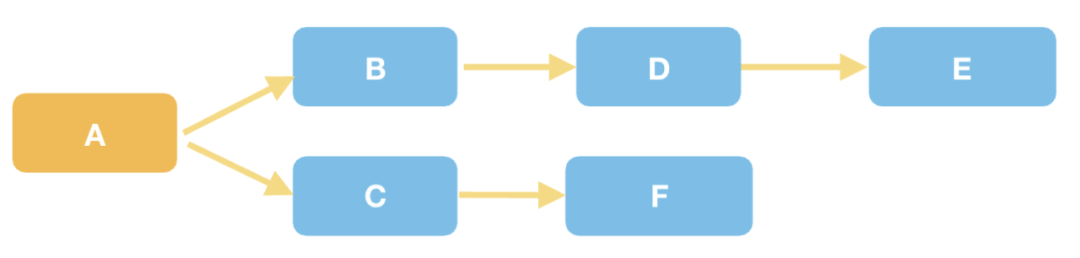
这样只需要根节点调用一次清理方法,就能完成整个子树的清理工作。这种方案使得清理工作更加结构化,但需要我们手动编码维护这种清理树;框架提供了基类,只需要简单的调用就能维护这棵清树。
无论框架提供多么高的便利性,还是需要我们手动编码组织起这块清理树。如果某些节点没有将自身清理工作委托给父节点,就会导致子树的泄露。
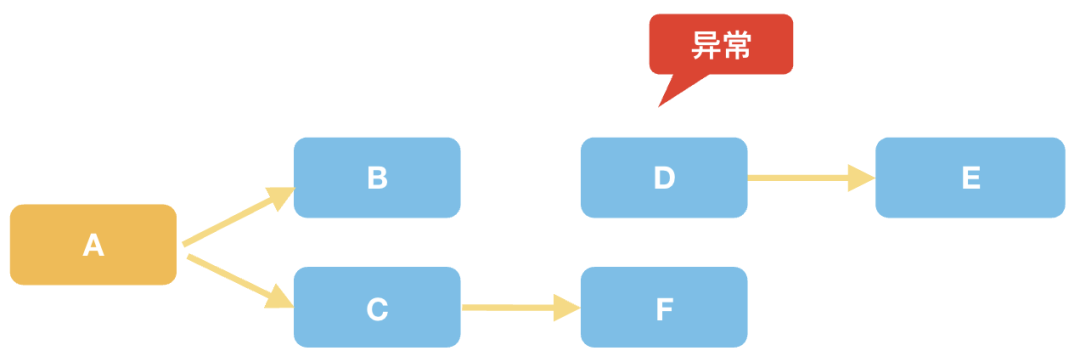
为此,框架提供了一种简单的开发阶段的泄露检查机制,判断发生泄露时,会触发异常;进而提醒开发关注,而通过异常堆栈就可以快速定位到具体那里的代码存在泄露问题。结构化清理机制支持 trace 日志,可以清晰的看出销毁树的层级,方便开发调试。
dispose IInstantiationServicedispose -> ICdispose -> IInstantiationServicedispose -> IBdispose -> IAdispose -> Ainstance
(3)模块重用的综合效果
我们希望在切换不同的表格时,能够复用 webview 和已经加载的模块,而不是每次都重新加载整个页面。可以将页面理解为一个容器,同一个容器,清理状态,就能承载不同的表格数据。 容器化重用的核心就是销毁和清理模块。
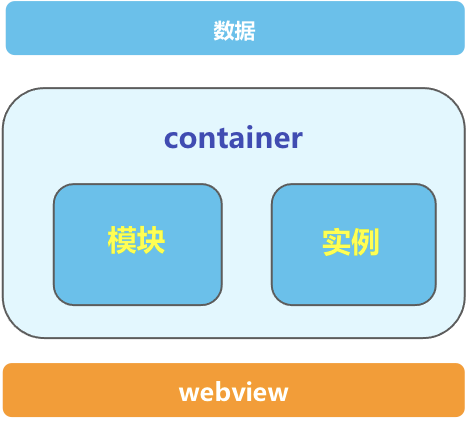
清理 container 的状态就是指:清理模块实例的状态、销毁模块实例、并重用模块
通过架构对模块全生命周期的管理,我们可以对模块进行可靠的复用,从而达到非常好的优化效果,在模块复用的情况下进行切换表格,可以快速展示表格内容。
总结一下业务驱动的架构探索之路:
管理复杂的依赖关系
支持异步依赖关系管理
支持模块分层单向依赖
支持模块全生命周期管理
架构的探索最终都反应在依赖注入框架的演进上。我们也已经将这套依赖注入框架部分核心能力从业务中抽离出来,形成 npm 包,目前团队中的其他项目也在尝试接入中。
关于AlloyTeam
AlloyTeam 是国内影响力最大的前端团队之一,核心成员来自前 WebQQ 前端团队。 AlloyTeam负责过WebQQ、QQ群、兴趣部落、腾讯文档等大型Web项目,积累了许多丰富宝贵的Web开发经验。 这里技术氛围好,领导nice、钱景好,无论你是身经百战的资深工程师,还是即将从学校步入社会的新人,只要你热爱挑战,希望前端技术和我们飞速提高,这里将是最适合你的地方。 加入我们,请将简历发送至 alloyteam@qq.com,或直接在公众号留言~ 期待您的回复😁
最后
面试题交流群持续开放,已经分享了近 许多 个面经。
加我微信: DayDay2021,备注面试,拉你进群~
我是 TianTianUp,我们下篇见~
往期推荐