
奇思妙想的SQL|兼顾性能的数据倾斜处理新姿势

阿里妹导读
本篇为系列第2篇,分享在支付宝支付数据链路改造升级过程中,针对数据倾斜的优化实践新方法,在解决数据倾斜问题的同时,还能兼顾更优的计算性能!
文章导读
SQL作为目前最通用的数据库查询语言,其功能和特性复杂度远不止大家常用的“SELECT * FROM tbl”这样简单,一段好的SQL和差的SQL,其性能可能有几十乃至上千倍的差距。而写出一个好的能兼顾性能和易用性的SQL,考验的不仅仅是了解到多少新特性新写法,而是要深入理解数据的处理过程,然后设计好数据的处理过程。
因此想推出本系列文章,并取名为《奇思妙想的SQL》,希望能以实际案例出发,和大家分享一些SQL处理数据的新方案新思路,并在过程中融入对问题本质的理解,希望大家能喜欢~
本篇为系列第2篇,分享下在支付宝支付数据链路改造升级过程中,针对数据倾斜的优化实践新方法,在解决数据倾斜问题的同时,还能兼顾更优的计算性能!
一、场景描述
数据倾斜的处理,作为校招/社招最经典的一道面试题,相信作为一名数据研发同学,多少都有些了解。数据倾斜可能发生在join、group by、Count Distinct等环节,但本质上其实都类似,即因为数据重分发或重分布等原因,导致大部分数据分发至少数几个计算节点上,闲着大伙儿,累死少数几个兄弟。问题表象也好识别,以ODPS场景为例,少数几个Fuxi Instance处理的数据量,远大于同一环节的其他Instance处理的数据量,并伴有明显的长尾现象。
典型的案例就是淘宝双十一场景中,交易订单明细大表需要关联商家信息维表以补全商家信息,在数据关联处理中,同一个商家对应的交易订单和维表对应商家信息,将根据卖家ID shuffle至同一个数据处理节点上。由于TOP商家在大促中产生的交易单量远大于普通商家,从而导致大量的数据集中到一台或者几台机器上计算,这些数据的计算速度将远远低于平均计算速度,导致整个计算过程被拖慢。
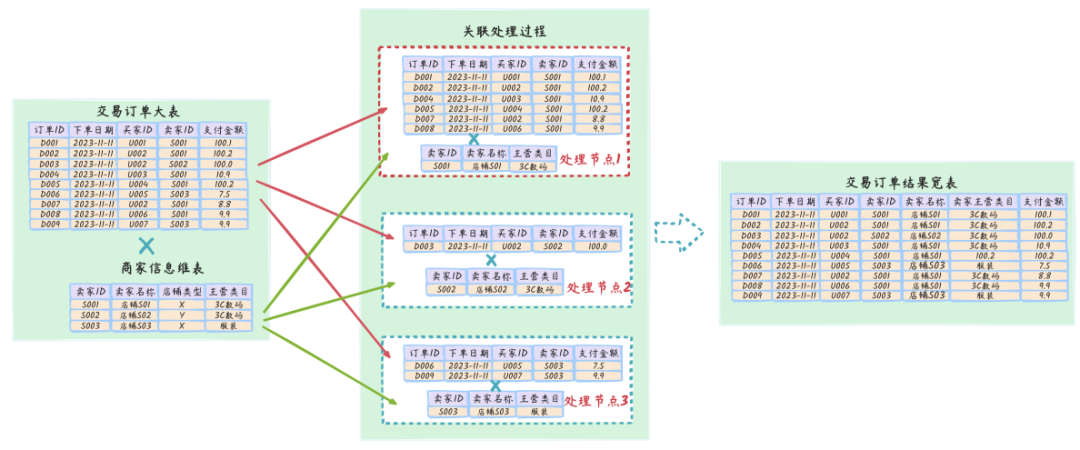
如上图所示,数据重分发过程中,按照Join Key(即卖家ID)进行Shuffle,大部分交易数据记录分发至处理节点1,导致三个并发处理节点中,处理节点1需要处理的数据量远大于其他两个处理节点,从而造成数据处理的不均匀,即数据倾斜。
二、常见的优化方法
2.1.Mapjoin
Mapjoin的好处自不必多言,通过把小表广播到大表所在计算节点上,有效避免了大表的Shuffle,自然也就避免了数据重分布导致的数据倾斜。若大表数据的原始分布本身就有不均匀的情况,此时也可以通过增加随机重分布的临时打散方式,将数据打得散一些,再通过Mapjoin实现数据关联。
SELECT /*+MAPJOIN(dim)*/ *FROM (SELECT * FROM dwd_tbl) baseLEFT OUTER JOIN (SELECT * FROM dim_tbl) dimON base.dim_key = dim.dim_key
2.2.特殊值/空值打散
特殊值/空值场景也比较普遍,比如主表中有个属性字段在某些场景下为空或为一些无业务含义的特殊字符串(如DEFAULT),然后此属性字段本身对应了一张数据量较大的维表,需要关联打宽补全。此时做数据关联,由于两张表需要按照关联key进行shuffle,就会导致主表中该字段为空/相同特殊字符串的数据记录shuffle到同一节点上,从而导致数据倾斜。
此类场景也好解决,对特殊值/空值在关联时转为随机值就行。
SELECT *FROM (SELECT * FROM dwd_tbl) baseLEFT OUTER JOIN (SELECT * FROM dim_tbl) dimON IF(COALESCE(base.dim_key,'')='',CONCAT('HIVE_',RAND()),base.dim_key) = dim.dim_key
2.3.热点值打散,副表呈倍数扩散
此类方法使用较少,核心在于对于主表附加一个随机值(比如1~10)字段,记为ext_a字段,然后对应被关联维表数据按照对应倍数进行复制膨胀,并依次赋予1~10的编号,记为ext_b字段,然后在关联两张表时把ext_a、ext_b两个字段也作为关联字段之一。
此方法适用于被关联表远比主表小,但又因数据大小超过内存容量而无法使用Mapjoin,且主表的数据倾斜程度不大(即极值对应的数据行数相较于值平均对应行数,倍数差距不太大)的情况下可以使用,但整体上此方案只能对数据热点成倍数的削弱一些。
SELECT *FROM (SELECT *,CAST(RAND()*10 AS BIGINT) AS ext_aFROM dwd_tbl) baseLEFT OUTER JOIN (SELECT *FROM dim_tblLATERAL VIEW EXPLODE(SPLIT('0;1;2;3;4;5;6;7;8;9',';')) tt AS ext_b-- 或者Join一个用于倍数膨胀的小表) dimON base.dim_key = dim.dim_keyAND base.ext_a = dim.ext_b
2.4.热点数据单独处理/SkewJoin
使用此方法通常也意味着被关联的维表数据大小较大,无法使用Mapjoin,只能走普通shuffle模式的join方案。此类场景最典型的案例就是双十一淘系交易大表关联商家维表,此时的商家维表因记录数和数据大小都较大而无法放入内存,再加上部分商家的交易单量远超大盘平均,此时的数据倾斜就得使用热点数据单独处理的方案了。
具体操作主要分三个部分:基于主表统计获得Top热点的属性值;用热点属性值将被关联维表拆成热点小表和非热点表,同时也将主表拆成热点主表和非热点主表;热点小表通过Mapjoin与热点主表join,非热点表与非热点主表join,最终两部分再Union到一起,完成数据关联。
-- Step01:热点数据记录提取INSERT OVERWRITE TABLE tmp_hot_list PARTITION (dt = '${bizdate}')SELECT dim_shop_id AS hot_idFROM main_tableWHERE dt = '${bizdate}'GROUP BY dim_shop_idHAVING COUNT(1) > 10000;INSERT OVERWRITE TABLE final_result_table PARTITION (dt = '${bizdate}')-- Step02:热点数据处理,使用MapJoin完成处理SELECT /*+MAPJOIN(a2,a3)*/a1.trade_no AS trade_no,a1.dim_shop_id AS shop_id,a3.shop_name AS shop_name,a3.shop_type AS shop_typeFROM (SELECT * FROM main_table WHERE dt = '${bizdate}') a1-- Step02-1:主表用JOIN关联热点表进行热点记录筛选JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') a2 -- 热点数据清单ON a1.dim_shop_id = a2.dim_shop_id-- Step02-2:热点维度数据处理LEFT OUTER JOIN (SELECT /*+MAPJOIN(b2)*/ b1.*FROM (SELECT * FROM dim_table_info WHERE dt = '${bizdate}') b1JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') b2 -- 热点数据清单ON b1.dim_shop_id = b2.dim_shop_id) a3ON a1.dim_shop_id = a3.dim_shop_idUNION ALL-- Step03:非热点数据处理,使用普通Join完成处理,两张表均需要进行ShuffleSELECT /*+MAPJOIN(a12)*/a11.trade_no AS trade_no,a11.dim_shop_id AS shop_id,a13.shop_name AS shop_name,a13.shop_type AS shop_typeFROM (SELECT * FROM main_table WHERE dt = '${bizdate}') a11-- Step03-1:主表用ANTI JOIN关联热点表进行剔除LEFT ANTI JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') a12ON a11.dim_shop_id = a12.dim_shop_id-- Step03-2:非热点维度数据处理LEFT OUTER JOIN (SELECT /*+MAPJOIN(b12)*/ b11.*FROM (SELECT * FROM dim_table_info WHERE dt = '${bizdate}') b11LEFT ANTI JOIN (SELECT * FROM tmp_hot_list WHERE dt = '${bizdate}') b12ON b11.dim_shop_id = b12.dim_shop_id) a13ON a11.dim_shop_id = a13.dim_shop_id;
整个步骤稍有些复杂,这里也可以直接用平台的skewjoin参数完成倾斜处理,skew的核心思路就是上面提到的热点数据单独处理,只是做了平台级别的集成,方便用户一键解决数据倾斜问题。详细用法和详细原理可参考
《阿里云-SKEWJOIN HINT》[1]
。
INSERT OVERWRITE TABLE final_result_table PARTITION (dt = '${bizdate}')SELECT /*+SKEWJOIN(a1)*/a1.trade_no AS trade_no,a1.dim_shop_id AS shop_id,a2.shop_name AS shop_name,a2.shop_type AS shop_typeFROM (SELECT * FROM main_table WHERE dt = '${bizdate}') a1LEFT JOIN (SELECT * FROM dim_table_info WHERE dt = '${bizdate}') a2ON a1.dim_shop_id = a2.dim_shop_id;

2.5.方案总结
不难发现,上面几种方案核心都是在围绕解决数据重分发(即shuffle)导致的热点问题,一种是想方设法采用Mapjoin的方式避免热点数据重分发,一种是让数据重分发过程中尽可能得均匀。
不管是哪种思路,问题核心都还是在解决shuffle导致的数据分布不均匀的问题。所以,一切的“罪魁祸首”就是
shuffle
、
shuffle
、
shuffle
~
三、一种新的思路 WithDistmapjoin~
3.1.核心思路
数据倾斜的核心在于数据处理不均匀,而数据处理的不均匀往往又来自数据重分发,也就是shuffle。因此如果能解决好shuffle不均匀问题,或者在不需要对大表进行shuffle的同时就能完成数据关联计算的操作,就能避免数据倾斜问题。在此我们联想到了Distmapjoin的能力,通过对中小规模的表(为便于理解,后文用维表进行替代)构建远程分布式查询节点,大表再通过网络远程查询相关维表数据,从而实现了类似于Mapjoin的方式,大表无须shuffle即能完成Join操作。
在此,预估Distmapjoin可以非常好的解决大表shuffle导致的数据倾斜问题。但我们忽略了一个问题,热点问题其实还没消失,只是转移成了远程网络查询的IO热点问题。当然在技术实现细节上可以通过同一key的多次查询合并为一次等方案进一步削弱热点问题,但热点问题并没有完全消除。在此,我们可以返回去参考skewjoin的方案,将维表的热点记录和非热点记录分而治之,只不过此时我们使用的不是“热点Mapjoin+非热点shuffle”的方案,而是采用“热点Mapjoin+非热点Distmapjoin”的方案。Distmapjoin的方案及原理详见
《阿里云-DISTRIBUTED MAPJOIN》[2]
Mapjoin用于处理热点数据,将维表热点记录广播至大表所在计算节点;Distmapjoin用于处理非热点数据,用于通过构建远程分布式查询节点,实现大表在无需移动的情况下完成数据关联操作。
当前方案还额外实现了提效的收益,大表在全流程中均无需shuffle,躺着不动就能实现join操作~
3.2.代码实现
WITH-- STEP01:热点Key采集tmp_hot_pid AS (SELECT dim_shop_id,'Y' AS is_hotFROM main_table_detailWHERE dt = '${bizdate}'GROUP BY dim_shop_idHAVING COUNT(1) > 100000)-- STEP02:维表热点数据打标,tmp_dim_tbl AS (SELECT /*+MAPJOIN(hot)*/dim.*,COALESCE(hot.is_hot,'N') AS is_hotFROM (SELECT *FROM dim_table_infoWHERE dt = '${bizdate}') dimLEFT OUTER JOIN tmp_hot_pid hotON dim.dim_shop_id = hot.dim_shop_id)-- STEP03:明细热点数据打标,tmp_dwd_tbl AS (SELECT /*+MAPJOIN(hot)*/base.*,COALESCE(hot.is_hot,'N') AS is_hotFROM (SELECT *FROM main_table_detailWHERE dt = '${bizdate}') baseLEFT OUTER JOIN tmp_hot_pid hotON base.dim_shop_id = hot.dim_shop_id)-- STEP04:数据合并处理,热点数据用Mapjoin,非热点数据用DISTMAPJOININSERT OVERWRITE TABLE final_result_table PARTITION (dt = '${bizdate}')SELECT *FROM (-- STEP04-1:非热点数据用DISTMAPJOINSELECT /*+ DISTMAPJOIN(dim(shard_count=77)) */dwd_tbl.trade_no AS trade_no,dwd_tbl.trade_date AS trade_date,dwd_tbl.shop_id AS shop_id,dim.shop_name AS shop_name,dim.shop_type AS shop_typeFROM (SELECT * FROM tmp_dwd_tbl WHERE is_hot = 'N') dwd_tblLEFT OUTER JOIN (SELECT * FROM tmp_dim_tbl WHERE is_hot = 'N') dimON dwd_tbl.partner_id = dim.partner_idUNION ALL-- STEP04-1:热点数据用MapjoinSELECT /*+MAPJOIN(dim)*/dwd_tbl.trade_no AS trade_no,dwd_tbl.trade_date AS trade_date,dwd_tbl.shop_id AS shop_id,dim.shop_name AS shop_name,dim.shop_type AS shop_typeFROM (SELECT *FROM tmp_dwd_tbl WHERE is_hot = 'Y') dwd_tblLEFT OUTER JOIN (SELECT *FROM tmp_dim_tbl WHERE is_hot = 'Y') dimON dwd_tbl.partner_id = dim.partner_id) base;
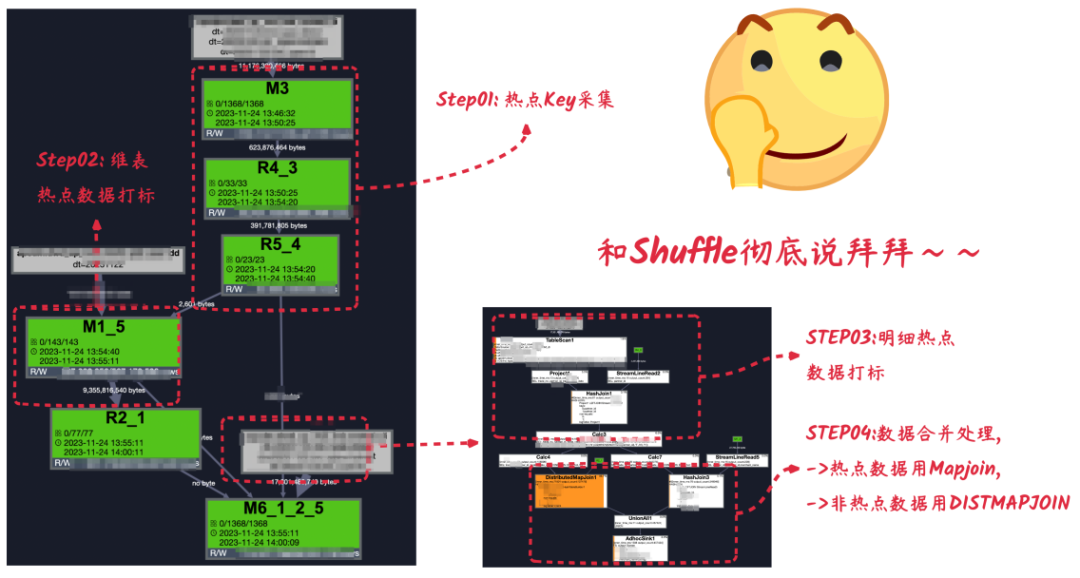
3.3.真实效果
当前新方案在支付宝核心支付数据链路上线,给相关可优化节点带来了
平均40%
的计算耗时缩减和
平均30%
的计算资源缩减。
方案主要应用于支付交易join商家维表、支付交易join合约维表等场景,方案将原本需要手动拆分热点利用“Mapjoin+shuffle进行热点数据处理”的过程,改为利用Distmapjoin或Mapjoin+Distmapjoin的方案,让支付交易大表在计算全过程中均无需移动,在解决数据倾斜问题的同时,也实现了降低计算资源和提升产出时效。
另外值得说的一点,我们对域内的支付交易数据链路进行了全链路HashCluster的处理,结合Distmapjoin的倾斜处理方案,可有效避免已经排好序的HC表再二次重分桶,全链路加工过程中都可以保持其原本已经设定好的HashCluster分桶策略~
四、方案总结
上面介绍了一种结合Mapjoin和Distmapjoin的数据倾斜处理方案,在有效解决数据倾斜问题的同时还可以避免大表的shuffle,提供了更优的性能表现。实际上如果数据倾斜情况不是特别严重(比如 热点数据行/平均单节点处理数据行 < 100),完全可以直接使用纯Distmapjoin的方案。
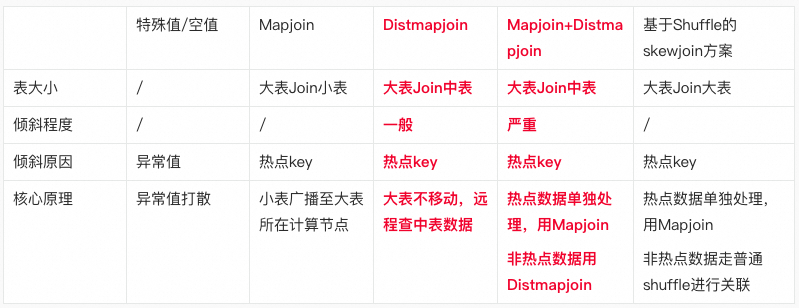
综合我们基于Distmapjoin提出的两种方案,我们结合各种方案的优劣势进行方案分级,然后根据具体场景进行更优的方案选择。
参考链接:
[1]https://help.aliyun.com/zh/maxcompute/user-guide/skewjoin-hint-1?spm=5176.28426678.J_HeJR_wZokYt378dwP-lLl.1.3a415181D3BDr0&scm=20140722.S_help@@文档@@455433.S_BB2@bl+RQW@ag0+BB1@ag0+os0.ID_455433-RL_ODPS%20SKEWJOIN-LOC_search~UND~helpdoc~UND~item-OR_ser-V_3-P0_0
[2]https://help.aliyun.com/zh/maxcompute/user-guide/distributed-mapjoin?spm=a2c4g.11186623.0.i1#concept-2197457