
大数据SQL数据倾斜与数据膨胀的优化与经验总结

背景
目前市面上大数据查询分析引擎层出不穷,如Spark,Hive,Presto等,因其友好的SQL语法,被广泛应用于各领域分析,公司内部也有优秀的ODPS SQL供用户使用。笔者所在团队的项目也借用ODPS SQL去检测业务中潜在的安全风险。在给业务方使用与答疑过程中,我们发现大多含有性能瓶颈的SQL,主要集中在数据倾斜与数据膨胀问题中。因此,本文主要基于团队实际开发经验与积累,并结合业界对大数据SQL的使用与优化,尝试给出相对系统性的解决方案。
本文主要涉及业务SQL执行层面的优化,暂不涉及参数优化。若设置参数,首先确定执行层面哪个阶段(Map/Reduce/Join)任务执行时间较长,从而设置对应参数。
本文主要分为以下三个部分:
一、会引入数据倾斜与数据膨胀问题
二、介绍当数据倾斜与数据膨胀发生时,如何排查与定位
三、会从系统层面给出常见优化思路。
一、问题篇
数据倾斜
数据倾斜是指在分布式计算时,大量相同的key被分发到同一个reduce节点中。针对某个key值的数据量比较多,会导致该节点的任务数据量远大于其他节点的平均数据量,运行时间远高于其他节点的平均运行时间,拖累了整体SQL执行时间。
其主要原因是key值分布不均导致的Reduce处理数据不均匀。本文将从Map端优化,Reduce端优化和Join端优化三方面给出相应解决方案。
数据膨胀
数据膨胀是指任务的输出条数/数据量级比输入条数/数据量级大很多,如100M的数据作为任务输入,最后输出1T的数据。这种情况不仅运行效率会降低,部分任务节点在运行key值量级过大时,有可能发生资源不足或失败情况。
二、排查定位篇
本节主要关注于业务SQL本身引起的长时间运行或者失败,对于集群资源情况,平台故障本身暂不考虑在内。
首先检查输入数据量级。与其他天相比有无明显量级变化,是否因为数据量级的问题天然引起任务运行时间过长,如双11,双十二等大促节点。 观察执行任务拆分后各个阶段运行时间。与其他天相比有无明显量级变化;在整个执行任务中时间耗时占比情况。 最耗时阶段中,观察各个Task的运行情况。Task列表中,观察是否存在某几个Task实例耗时明显比平均耗时更长,是否存在某几个Task实例处理输入/输出数据量级比平均数据量级消费产出更多。 根据步骤3中定位代码行数,定位问题业务处理逻辑。
三、优化篇
数据倾斜
1. Map端优化
1.1 读取数据合并
在数据源读取查询时,动态分区数过多可能造成小文件数过多,每个小文件至少都会作为一个块启动一个Map任务来完成。对于文件数量而言,等于 map数量 * 分区数。对于一个Map任务而言,其初始化的时间可能远远大于逻辑处理时间,因此通过调整Map参数把小文件合并成大文件进行处理,避免造成很大的资源浪费。
1.2 列裁剪
减少使用select * from table语句,过多选择无用列会增加数据在集群上传输的IO开销;对于数据选择,需要加上分区过滤条件进行筛选数据。
1.3 谓词下推
在不影响结果的情况下,尽可能将过滤条件表达式靠近数据源位置,使之提前执行。通过在map端过滤减少数据输出,降低集群IO传输,从而提升任务的性能。
1.4 数据重分布
在Map阶段做聚合时,使用随机分布函数distribute by rand(),控制Map端输出结果的分发,即map端如何拆分数据给reduce端(默认hash算法),打乱数据分布,至少不会在Map端发生数据倾斜。
2. Reduce端优化
2.1 关联key空值检验
部分实例发生长尾效应,很大程度上由于null值,空值导致,使得Reduce时含有脏值的数据被分发到同一台机器中。
针对这种问题SQL,首先确认包含无效值的数据源表是否可以在Map阶段直接过滤掉这些异常数据;如果后续SQL逻辑仍然需要这些数据,可以通过将空值转变成随机值,既不影响关联也可以避免聚集。
SELECT ta.id
FROM ta
LEFT JOIN tb
ON coalesce(ta.id , rand()) = tb.id;
2.2 排序优化
Order by为全局排序,当表数据量过大时,性能可能会出现瓶颈;Sort by为局部排序,确保Reduce任务内结果有序,全局排序不保证;Distribute by按照指定字段进行Hash分片,把数据划分到不同的Reducer中;CLUSTER BY:根据指定的字段进行分桶,并在桶内进行排序,可以认为cluster by是distribute by+sort by。
对于排序而言,尝试用distribute by+sort by确保reduce中结果有序,最后在全局有序。
-- 原始脚本
select *
from user_pay_table
where dt = '20221015'
order by amt
limit 500
;
-- 改进脚本
SELECT *
FROM user_pay_table
WHERE dt = '20221015'
DISTRIBUTE BY ( CASE
WHEN amt < 100 THEN 0
WHEN amt >= 100 AND age <= 2000 THEN 1
ELSE 2
END )
SORT BY amt
LIMIT 500
;
3. Join端优化
3.1 大表join小表
通过将需要join的小表分发至map端内存中,将Join操作提前至map端执行,避免因分发key值不均匀引发的长尾效应,复杂度从(M*N)降至(M+N),从而提高执行效率。ODPS SQL与Hive SQL使用mapjoin,SPARK使用broadcast。
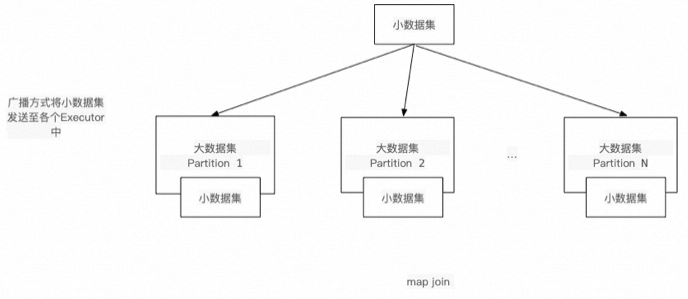
3.2 大表join大表
长尾效应由热点数据导致,可以将热点数据加入白名单中,通过对白名单数据和非白名单数据分别处理,再合并数据。
具体表现为打散倾斜key,进行两端聚合(针对聚合)或者拆分倾斜key进行打散然后再合并数据。
数据膨胀
避免笛卡尔积
Join关联条件有误,表Join进行笛卡尔积,造成数据量爆炸。
关联key区分度校验
关注JoinKey区分度,key值区分度越低(distinct数量少),越有可能造成数据爆炸情况。如用户下的性别列,交易下的省市列等。
聚合操作误用
部分聚合操作需要将中间结果记录下来,最后再生成最终结果,这使得在select操作时,按照不同维度去重Distinct、不同维度开窗计算over Partition By可能会导致数据膨胀。针对这种业务逻辑,可以将一个SQL拆分成多个SQL分别进行处理操作。
总结
大数据SQL优化是一项涉及知识面较广的工作,除了分析现有执行计划之外,还需要学习相应查询分析引擎设计原理。针对我们日常遇到的问题现总结分享给大家,供大家查阅。
