近日,根据复旦大学报道,学校信息科学与工程学院博士生李小康使用OCR和正则表达式帮助学院几分钟核查完数百人核酸完成截图,大大提高了核查效率和精度。
相关话题在知乎上也引起了众多讨论,目前该话题已经得到了300多万次浏览。
OCR,英文全称Optical Character Recognition,即光学字符识别,也可简单地称为文字识别,这是文字自动输入的一种方法。
OCR主要是通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征可以将票据、报刊、书籍、文稿及其它印刷品转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。
李小康表示,“OCR可以把图像中的文字识别出来,转换为文本信息,就方便用来核查了。而且因为核酸截图是打印字体,识别率非常高,几乎可以做到100%准确”。
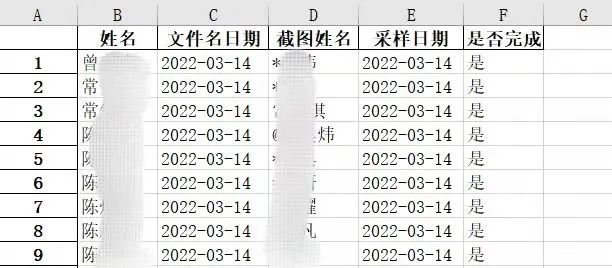
一张截图中的文本信息很多,包括脱敏处理的姓名、证件类型、证件号码、采样时间、组织机构等内容,但不是所有信息都有用。其中姓名、采样时间、是否已采样最为关键,是需要检索筛选出的内容。
在此基础上,李小康想到了Python语言中的正则表达式。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串,在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
“使用正则表达式就可以把想要的信息从OCR识别的文本中筛选出来。最后,确认好每张截图里的姓名、检测时间和是否已采样等信息后,再把所有人的结果输出到Excel文件中,方便人工确认。”
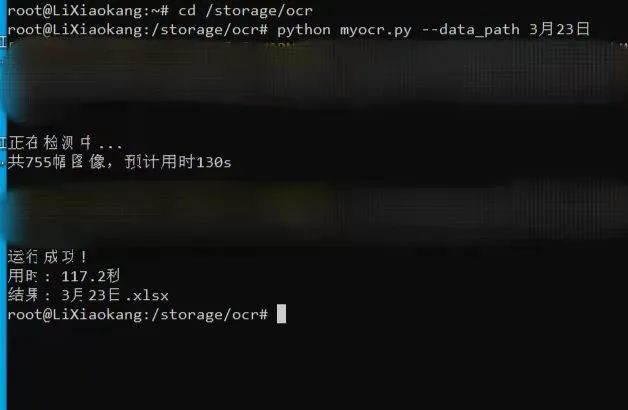
3月15日晚,李小康花了一个多小时就写出了初始代码,共130行,发现确实能够跑通,且运行效率很高。利用自己班上的核酸截图数据上进行验证后发现,程序不仅准确率高、运行时间短,80多张图只用了20多秒就完成了,还发现了此前人工核查没有发现的问题。
三月初以来,复旦启动了常态化核酸筛查工作,班级辅导员必须核查,“不漏一人”。作为生物医学工程专业博士生,研究方向是医学影像与人工智能,李小康平常会接触很多图像处理方法,他表示,自己开发这个程序的初衷是为了减少自己和身边老师的工作量。
“虽然原理也很简单,只要是会写代码的人第一时间就会明白是怎么回事,但是不做相关工作的感受不到这件事情的费时费力,自然也不会想出办法。我只是用我学到的知识解决实际工作中的困难。”李小康把这件事发到朋友圈之后,不少学工的同事表示很感兴趣,他也把代码分享了出去,让有需求的老师们都能及时使用。“因为程序使用Python语言编写,代码注释也写得很完整,只要会使用Python,就可以很快上手。”为了方便不会编程的老师使用,李小康最后还把程序进行了封装。“大家需要用的时候,只要在命令行输入一行代码就可以运行,非常简单。”目前,程序已在该学院开始服务。李小康曾让别的老师试用自己的程序进行核查。800幅截图,原来要几个人核对一个多小时,现在只需等2分钟就拿到结果。
比如知乎用户@AimiBritni就表示,这个产品本身并没有特别出彩的地方,但是“这种洞察问题并解决问题的能力和意识”十分值得我们学习。
同时,也有不少网友在这基础之上,贡献了自己针对防疫和抗疫的想法。比如知乎用户@第一大明白就写到:如果流调人员有一个专业的应用程序,用该应用程序扫一下阳性病例的健康码,便可自动识别阳性病例的个人信息,与此同时,该程序调用公安、工信、支付等各系统掌握的有关阳性病例在各场所行动轨迹的数据,先按照已被各部门掌握的数据生成一个半成品的行动轨迹,该轨迹内容不为流调人员所见,之后在应用程序前端按照时间、地点等要素生成表单,流调人员可以通过询问阳性病例来填写大数据中没有的信息,填写时,地点都自动联系国家地名库中的标准地名,之后一键生成初级流调信息报告,流调人员再通过目前采用的验证方式完成流调信息的确认,生成最终的流调报告。
https://www.zhihu.com/question/526681561/answer/2431023725
但是在这背后,我们仍然不能忽略了一些基本的事实。那就是防疫几年,核酸数据仍然没有一个全国统一公开的API接口,一个技术上没有任何难度的小功能,却没有一个健康码系统率先开发并提供。
防疫固然重要,但如何将信息化进程与防疫结合,让志愿者从事更有意义的工作与服务,也是需要思考的问题。https://mp.weixin.qq.com/s/l8u9JifKDlRDoz32-jZWQg
https://mp.weixin.qq.com/s/RogQcUAsZszW5HkYwYcV-w