
Meta「世界模型」遭质疑:10年前就有了!LeCun:关键在于构建和训练

新智元报道
新智元报道
编辑:好困 拉燕
【新智元导读】LeCun刚刚发表完自己以AI为基构建「世界模型」的设想,随即就引发了大量的讨论。众多网友表示,这个概念早就提出过了。

始于20世纪60年代?





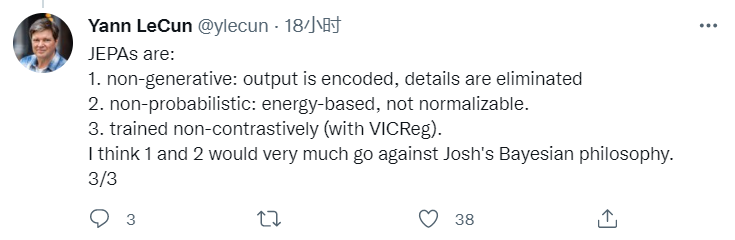
非生成性——输出是被加密的,细节都被省掉。
非概率性——是基于能量的,不是可规范化的。
非对比训练(用VICR)
「世界模型」是什么?

早期工作
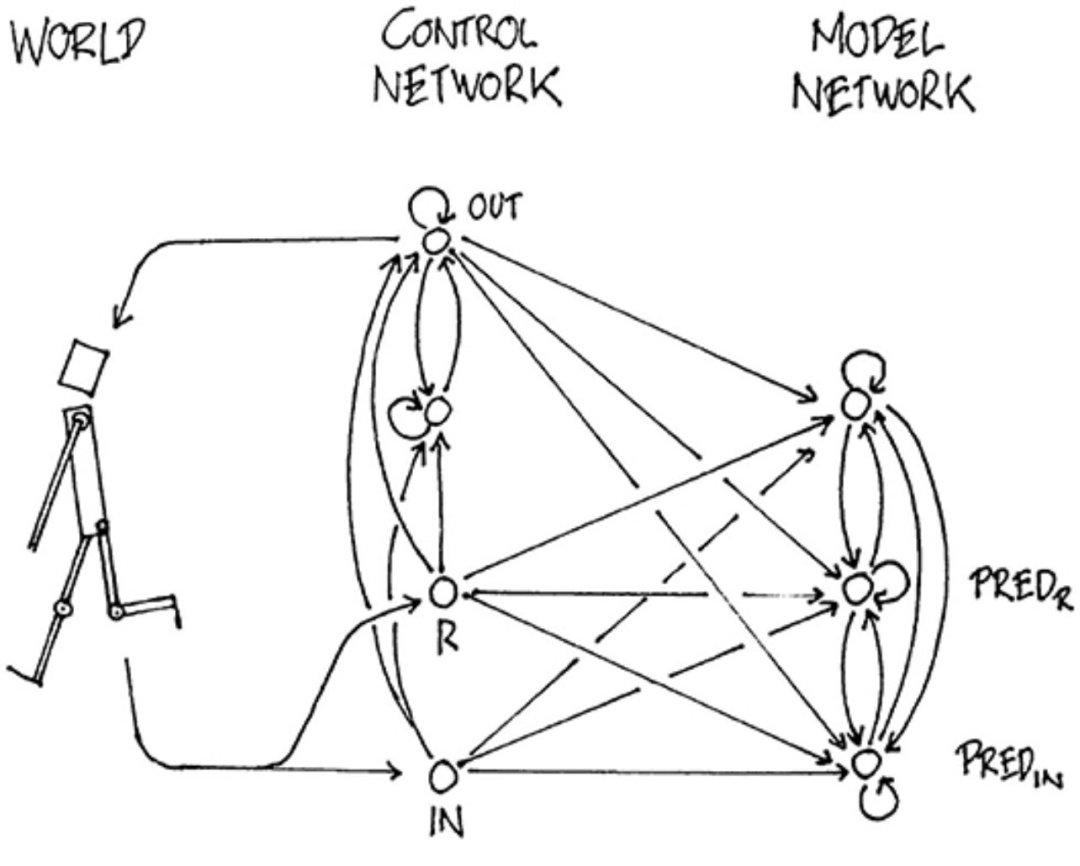
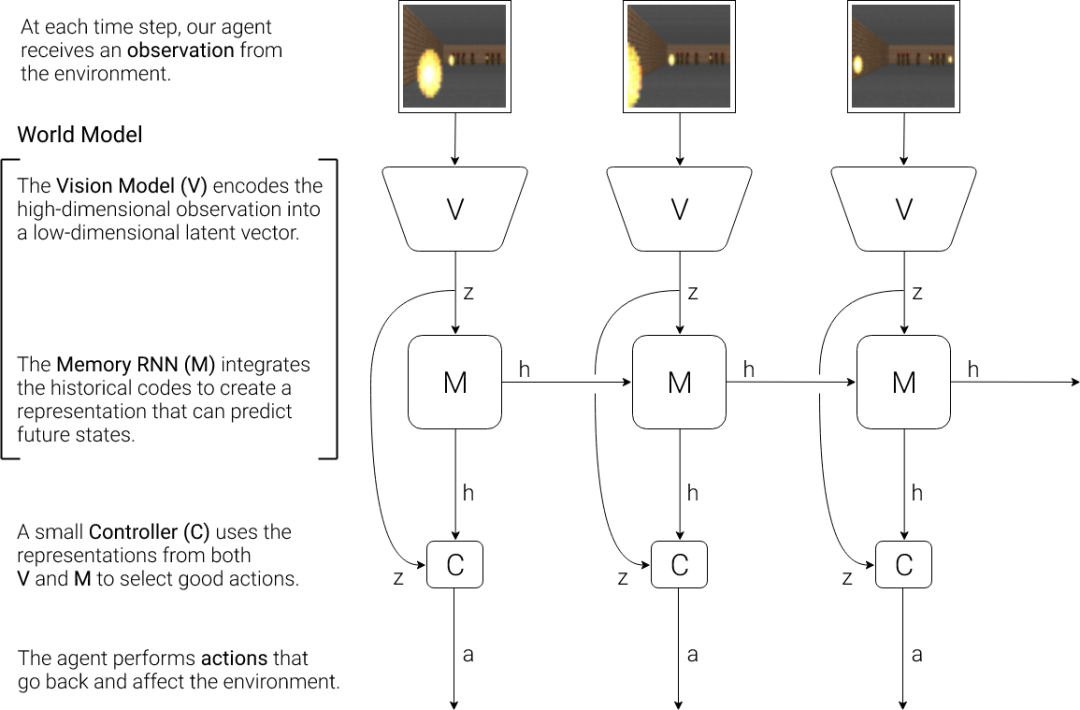
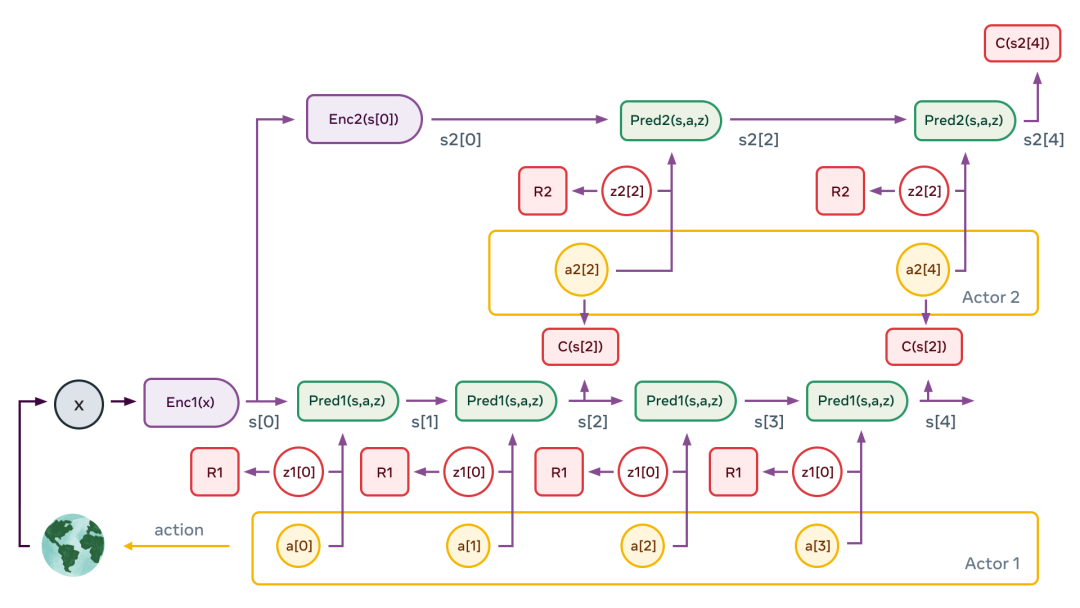
自主智能架构
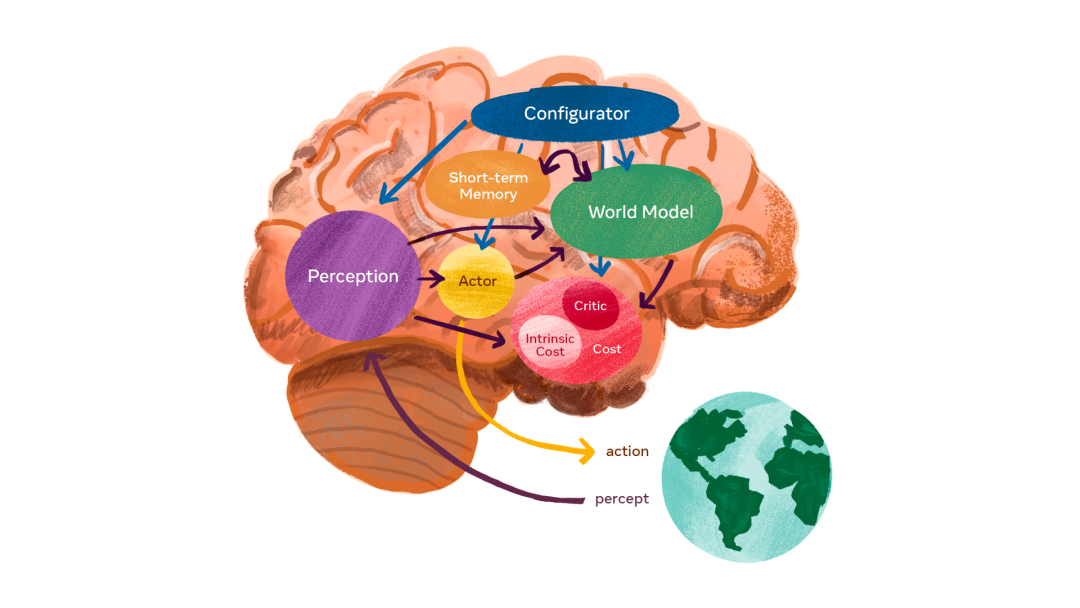
配置器模块负责控制任务的分配和调参。
感知模块负责接收来自传感器的信号并估计世界的当前状态。
世界模型模块的作用有两点:(1)补全感知模块没有提供的信息;(2)预测合理的未来状态。
代价模块负责计算和预测智能体的不合适程度。由两个部分组成:(1)内在代价,直接计算「不适」:对智能体的损害、违反硬编码的行为等;(2)评价者,预测内在代价的未来值。
行为者模块负责提供动作序列的建议。
短期记忆模块负责跟踪当前和预测的世界状态,以及相关代价。
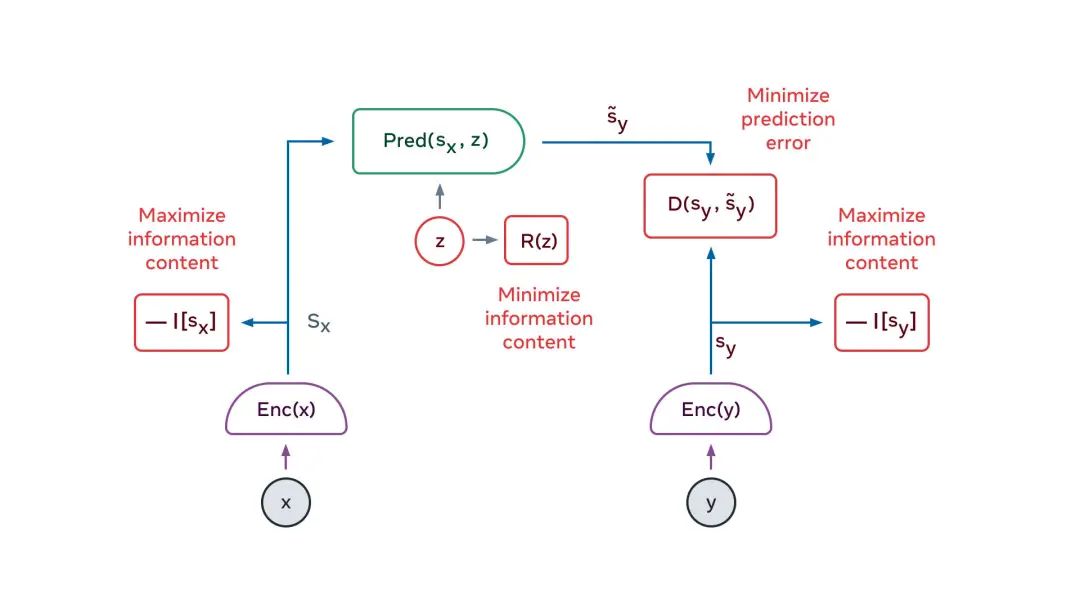
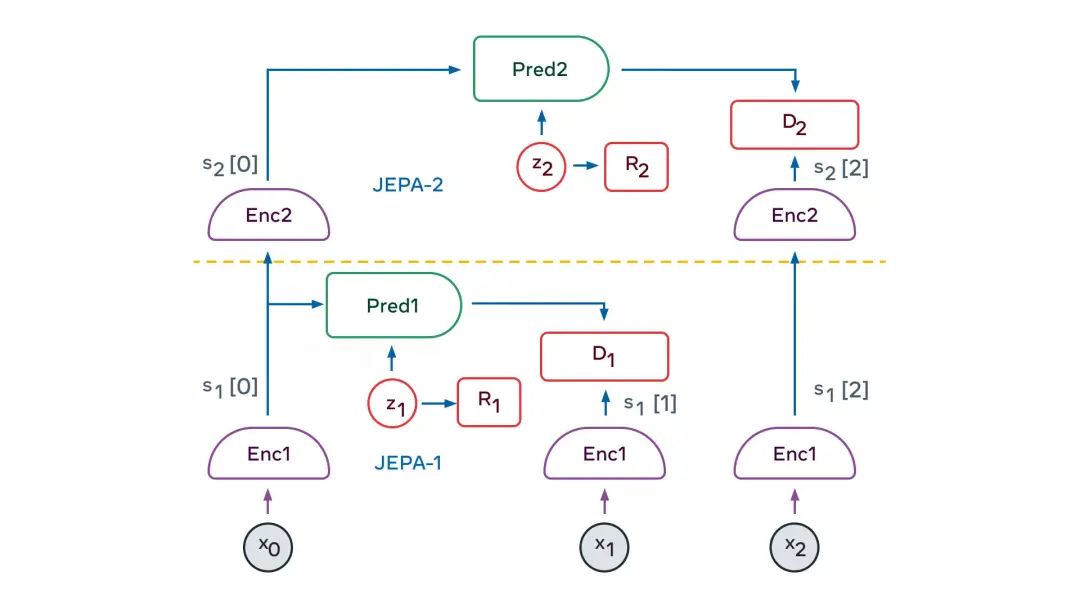
自监督训练
使关于x的表示,最大程度地提供关于x的信息 使关于y的表示,最大程度地提供关于y的信息 从关于x的表示中,最大程度地预测关于y的呈现 使预测器调用来自潜在变量的尽可能少的信息,来表示预测中的不确定性。
参考资料:
https://ai.facebook.com/blog/yann-lecun-advances-in-ai-research/
https://twitter.com/rsalakhu/status/1496677311290167302
https://twitter.com/ylecun/status/1496750102609809410

评论