
10分钟带你玩转Kafka基于Controller的领导选举!

导语 | Controller作为Apache Kafka的核心组件,本文将从背景、原理以及源码与监控等方面来深入剖析Kafka Controller,希望带领大家去了解Controller在整个Kafka集群中的作用。
一、背景
Controller,是Apache Kafka的核心组件非常重要。它的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群。
在整个Kafka集群中,如果Controller故障异常,有可能会影响到生产和消费。所以,我们需要对其状态、选举、日志等做全面的监控。
二、Controller是什么
Controller,是Apache Kafka的核心组件。它的主要作用是在Apache Zookeeper的帮助下管理和协调控制整个Kafka集群。
集群中的任意一台Broker都能充当Controller的角色,但是,在整个集群运行过程中,只能有一个Broker成为Controller。也就是说,每个正常运行的Kafka集群,在任何时刻都有且只有一个Controller。
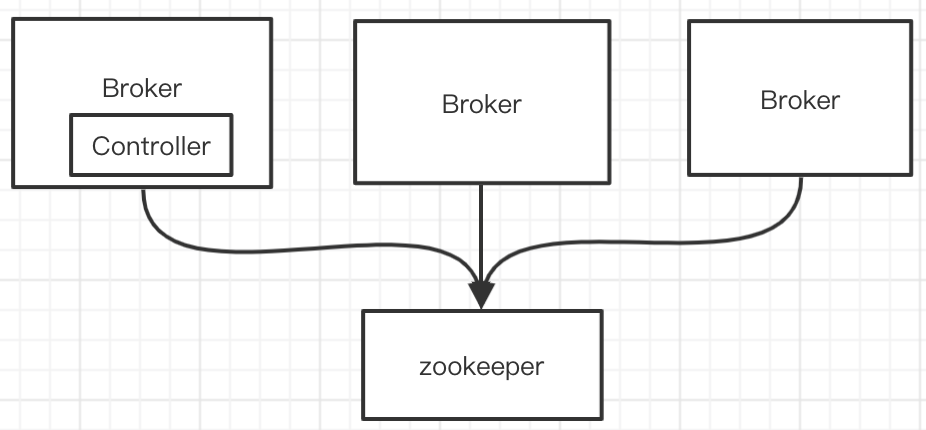
三、Controller保存的数据
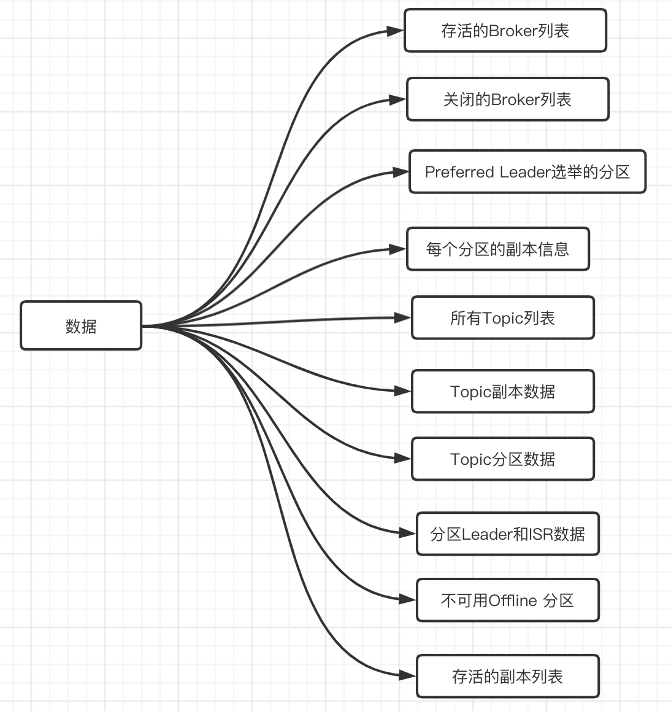
其中比较重要的数据有:
所有主题信息。包括具体的分区信息,比如领导者副本是谁,ISR集合中有哪些副本等。
所有Broker信息。包括当前都有哪些运行中的Broker,哪些正在关闭中的Broker等。
所有涉及运维任务的分区。包括当前正在进行Preferred领导者选举以及分区重分配的分区列表。
这些数据其实在ZooKeeper中也保存了一份。每当控制器初始化时,它都会从ZooKeeper上读取对应的元数据并填充到自己的缓存中。
而Broker上元数据的更新都是由Controller通知完成的,Broker并不从Zookeeper获取元数据信息。
四、Controller职责
Controller职责大致分为5种:
主题管理,分区重分配,Preferred leader选举,集群成员管理(Broker上下线),数据服务(向其他Broker提供数据服务) 。
它们分别是:
UpdateMetadataRequest:更新元数据请求。topic分区状态经常会发生变更(比如leader重新选举了或副本集合变化了等)。由于当前clients只能与分区的leader Broker进行交互,那么一旦发生变更,controller会将最新的元数据广播给所有存活的Broker。具体方式就是给所有Broker发送UpdateMetadataRequest请求。
CreateTopics: 创建topic请求。当前不管是通过API方式、脚本方式抑或是CreateTopics请求方式来创建topic,做法几乎都是在Zookeeper的/brokers/topics下创建znode来触发创建逻辑,而controller会监听该path下的变更来执行真正的“创建topic”逻辑。
DeleteTopics:删除topic请求。和CreateTopics类似,也是通过创建Zookeeper下的/admin/delete_topics/
节点来触发删除topic, controller执行真正的逻辑。分区重分配:即kafka-reassign-partitions脚本做的事情。同样是与Zookeeper结合使用,脚本写入/admin/reassign_partitions节点来触 发,controller负责按照方案分配分区。
Preferred leader分配:preferred leader选举当前有两种触发方式:自动触发(auto.leader.rebalance.enable=true)和kafka-preferred-replica-election脚本触发。两者“玩法”相同,向Zookeeper的/admin/preferred_replica_election写数据,controller提取数据执行preferred leader分配。
分区扩展:即增加topic分区数。标准做法也是通过kafka-reassign-partitions脚本完成,不过用户可直接往Zookeeper中写数据来实现,比如直接把新增分区的副本集合写入到/brokers/topics/
下,然后controller会为你自动地选出leader并增加分区。 集群扩展:新增broker时Zookeeper中/brokers/ids下会新增znode,controller自动完成服务发现的工作。
broker崩溃:同样地,controller通过Zookeeper可实时侦测broker状态。一旦有broker挂掉了,controller可立即感知并为受影响分区选举新的leader。
ControlledShutdown:broker除了崩溃,还能“优雅”地退出。broker一旦自行终止,controller会接收到一个 ControlledShudownRequest请求,然后controller会妥善处理该请求并执行各种收尾工作。
Controller leader选举:controller必然要提供自己的leader选举以防这个全局唯一的组件崩溃宕机导致服务中断。这个功能也是通过 Zookeeper的帮助实现的。
源码位置可以看后面段落9源码的说明。
五、Broker如何成为Controller
和解决可能的脑裂问题
(一)Broker如何成为Controller
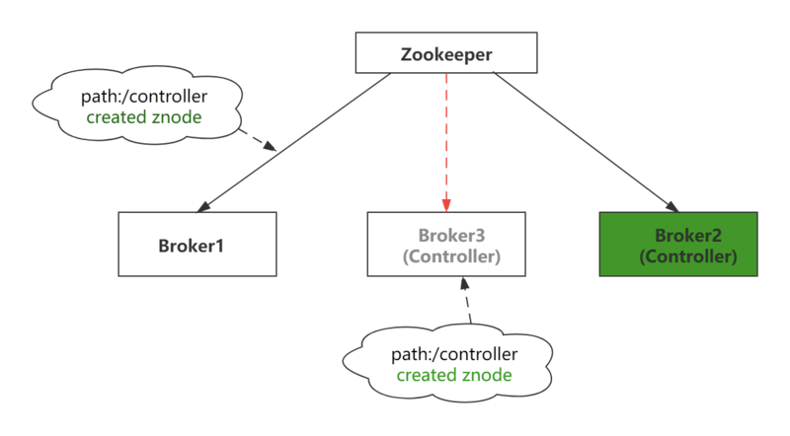
最先在Zookeeper上创建临时节点/controller成功的Broker就是Controller。
源码路径(Kafka2.2):
Kafka#main->KafkaServerStartable#startup()->KafkaServer#startup()->KafkaController#startup()->eventManager.put(Startup)->elect()-> zkClient.registerControllerAndIncrementControllerEpoch
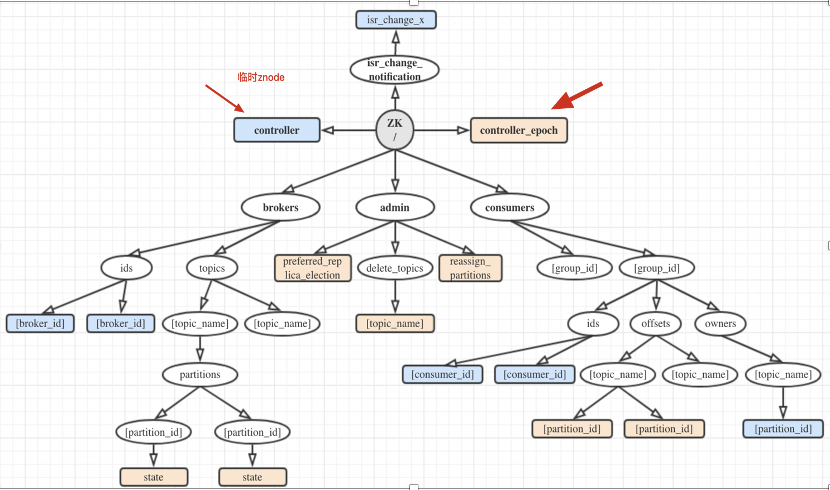
Controller重度依赖Zookeeper,依赖zookeepr保存元数据,依赖zookeeper进行服务发现。Controller大量使用Watch功能实现对集群的协调管理。
当broker节点因故障离开Kafka集群时,broker中存在的leader分区将不可用(因为客户端只对leader分区进行读写)。
为了最大限度地减少停机时间,需要快速找到替代的领导分区。Controller可以从zookeeper watch获取通知信息。Zookeeper给了客户端监听znode变化的能力,也就是所谓的watch通知功能。一旦znode节点创建、删除、子节点数量发生变化,或者znode中存储的数据本身发生变化,Zookeeper会通过节点变化处理程序显式通知客户端。
当Broker宕机或主动关闭时,Broker与Zookeeper的会话结束,znode会被自动删除。同样的,Zookeeper的watch机制把这个变化推送给Controller,让Controller知道有Broker down或者up,这样Controller就可以进行后续的协调操作。
Controller将收到通知并对其采取行动,以确定Broker上的哪些分区将成为Leader partition。然后,它会通知每个相关的Broker,或者Broker上的topic partition将成为leader partition,或者LeaderAndIsrRequest从新的leader分区复制数据。
(二)如何避免Controller出现裂脑
如果Controller所在的Broker故障,Kafka集群必须有新的Controller,否则集群将无法正常工作。这儿存在一个问题。很难确定Broker是宕机还是只是暂时的故障。但是,为了使集群正常运行,必须选择新的Controller。如果之前更换的Controller又正常了,不知道自己已经更换了,那么集群中就会出现两个Controller。
其实这种情况是很容易发生的。例如,由于垃圾回收(GC),一个Controller被认为是死的,并选择了一个新的控制器。在GC的情况下,在原Controller眼里没有任何变化,Broker甚至不知道自己已经被暂停了。因此,它将继续充当当前Controller,这在分布式系统中很常见,称为裂脑。
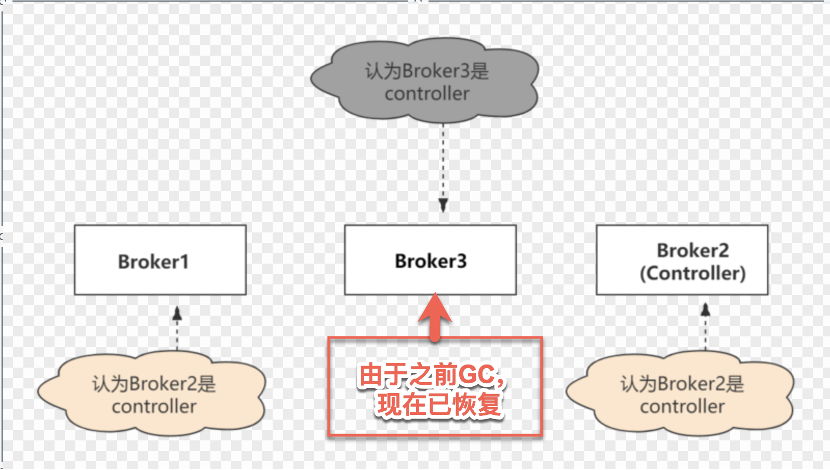
现在,集群中有两个Controller,可能会一起发出相互冲突的事件,这会导致脑裂。可能会导致严重的不一致。所以需要一种方法来区分谁是集群的最新Controller。
Kafka是通过使用epoch number来处理,epoch number只是一个单调递增的数。第一次选择控制器时,epoch number值为1。如果再次选择新控制器,epoch number为2,依次单调递增。
每个新选择的Controller通过zookeeper的条件递增操作获得一个新的更大的epoch number。当其他Broker知道当前的epoch number时,如果他们从Controller收到包含旧(较小)epoch number的消息,则它们将被忽略。即Broker根据最大的epoch number来区分最新的Controller。
epoch number记录在Zookeepr的一个永久节点controller_epoch。
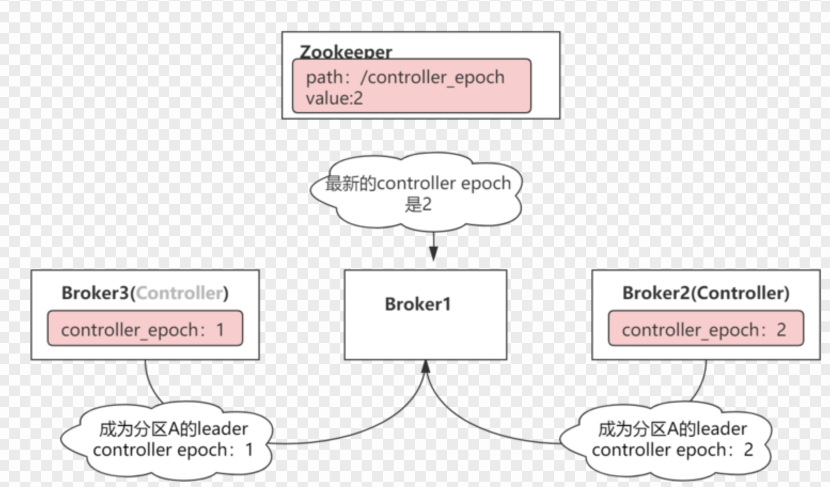
上图中,Broker3向Broker1下发命令:将Broker1上的partitionA做为leader,消息的epoch number值为1,同时Broker2也向Broker1发送同样的命令。不同的是,消息的epoch number值为2,此时broker1只监听broker2的命令(由于其epoch号大),而会忽略broker3的命令,以免发生脑裂。
六、Controller在版本上的改进
在Kafka2.2之前
网络处理模型:Kafka Server在启动时会初始化SocketServer、KafkaApis和KafkaRequestHandlerPool对象,这也是Server网络处理模型的主要组成部分。Kafka Server的网络处理模型也是基于Java NIO机制实现的,实现模式与Reactor模式类似。
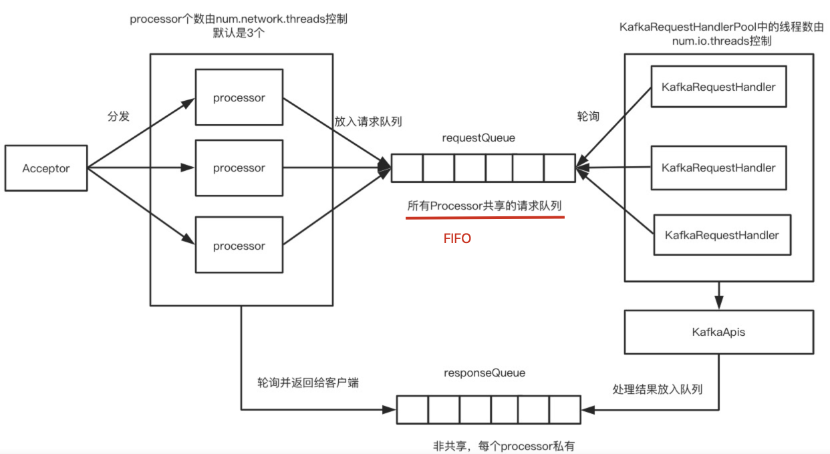
如上图,所有请求共享一个requestQueue队列。
问题:当前Broker对入站请求类型不做任何优先级处理。
不论是PRODUCE请求、FETCH请求还是Controller类的请求。对Controller发送的消息非常不公平,因为这个类请求应该优先级更高。
这就可能造成一个问题:即clients发送的数据类请求积压导致controller推迟了管理类请求的处理。设想这样的场景。假设controller向broker广播了leader发生变更。于是新leader开始接收clients端请求,而同时老leader所在的broker由于出现了数据类请求的积压使得它一直忙于处理这些请求而无法处理controller发来的LeaderAndIsrRequest请求,因此这是就会出现“双主”的情况——也就是所谓的脑裂。
在Kafka 2.2
将控制器发送的请求与普通数据类请求分开处理,源码SocketServer.scala#startup()->KafkaServer.scala。

在0.11版本上也做了大的改进,会在后面段落8中说明。
七、Controller的监控
在整个集群运行过程中,只能有一个Broker成为Controller。所以要监控Controller的数量以及Controller的变更史。
可以用Kafka的JMXTool,进行轻量级的监控。
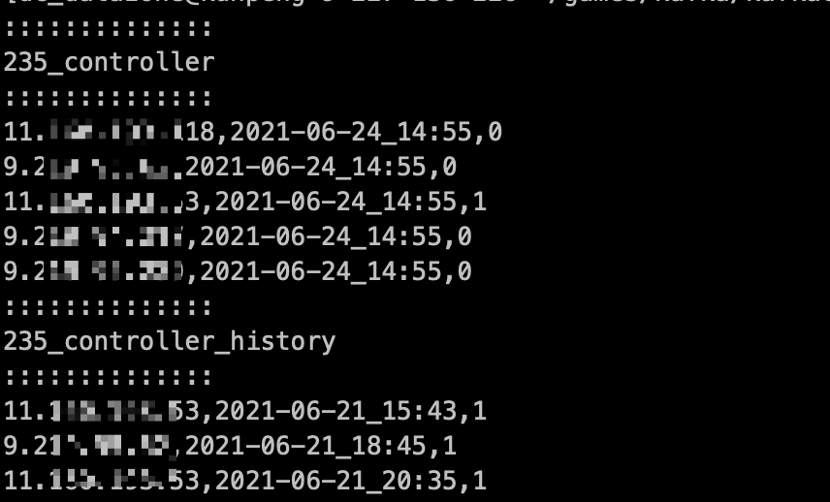
${KAFKA_PATH}/bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://"${BrokerIP}":"${JMXPort}"/jmxrmi --object-name kafka.controller:type=KafkaController,name=ActiveControllerCount --date-format "YYYY-MM-dd_HH:mm" --reporting-interval -1 | grep -v type记录Controller变更历:
function inter_controller_history(){#第一次检测集群Controllerif [ ! -f "${clusterID}"_controller_history ]; thenawk '/,1$/ {print $0}' "${clusterID}"_controller >> "${clusterID}"_controller_history#记录Controller变更历史elsenowController=$(awk '/,1$/ {print $0}' "${clusterID}"_controller | awk -F ',' '{print $1}')LastTimeController=$(tail -n 1 "${clusterID}"_controller_history | awk '/,1$/ {print $0}' | awk -F ',' '{print $1}')if [ "${nowController}_X" != "${LastTimeController}_X" ];thenawk '/,1$/ {print $0}' "${clusterID}"_controller >> "${clusterID}"_controller_historymsg="${msg_tmp} clusterID:${clusterID} ${ClusterNameCN} Controller From ${LastTimeController} to ${nowController}"echo "$msg" >> $log_file_namesend_warningfifi}
监控效果:
通过JMXTool,还可以拉取Kafka的其他指标进行监控。
例如:
under_replicated_partitions有非同步副本监控。
OfflinePartitionsCount分区丢失leader监控。
${KAFKA_PATH}/bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://${BrokerIP}:"${JMXPort}"/jmxrmi --object-name kafka.controller:type=KafkaController,name=OfflinePartitionsCount --date-format "YYYY-MM-dd_HH:mm" --reporting-interval -1ZooKeeper_SessionState Broker与Zookeeper断开连接监控。
MessagesInPerSec,进入Broker消费数量监控。
${KAFKA_PATH}/bin/kafka-run-class.sh kafka.tools.JmxTool --jmx-url service:jmx:rmi:///jndi/rmi://"${BrokerIP}":"${JMXPort}"/jmxrmi --object-name kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec --date-format "YYYY-MM-dd HH:mm" --attributes Count --reporting-interval -1ISR扩缩容率等。
监控可以有很多方式,这样做主要是简单方便,不需要依赖太多监控系统,同时监控程序可以快速部署到海外或者合作伙伴机房。
八、关于Controller的架构改进
Kafka中的一台Broker充当Controller的角色,此台Broker不仅对生产者消费者提供服务,还要协调整个集群的管理工作。如果使用0.11版本之前的Kafka而且分区很多时,建议将几台机器配置为只能成为Controller(当然这里需要修改源码,编译)。
0.11版本之前
同步操作Zookeeper使用同步的API,性能差。当Broker宕机,大量主题分区发生变更时,自动恢复时间长。Controller是一个分区一个分区进行写入的,对于分区数很多的集群来说,这无疑是个巨大的性能瓶颈。
0.11 版本
异步操作Zookeeper使用async API,写入提升了10倍。

如果机器性能较好,可以将Zookeeper和Controller部署在相同的机器。Kafka对Zookeeper写请求比较少。
注意:消费方式有基于Zookeeper消费和基于Broker消息。基于Zookeeper消费,就是将消费位移提交到Zookeeper上,这种方式对Zookeeper有大量写操作。不要将Zookeeper和其他机器共用。
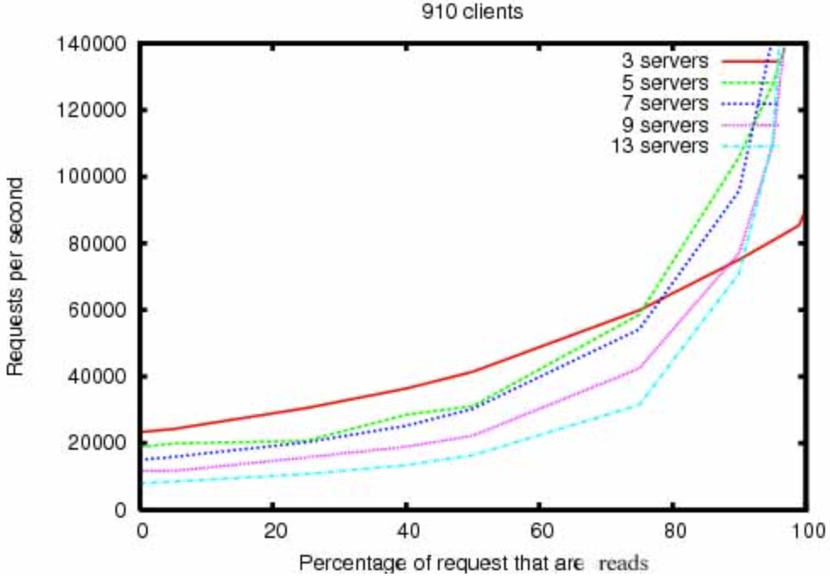
Zookeeper官网上有对读写占比的压测说明:
九、Controller的源码
源码(基于kafka 2.2)的内容较多:
(一)Controller启动流程【主要看写的源码注释】
/*** KafkaController#startup中为每一个server都会启动一个eventManager** 集群首次启动时,Controller 尚未被选举出来。* 于是,Broker 启动后,首先将 Startup 这 个 ControllerEvent 写入到事件队列中,然后启动对应的事件处理线程和 ControllerChangeHandler ZooKeeper 监听器,* 最后依赖事件处理线程进行 Controller 的选举。* 在源码中,KafkaController 类的 startup 方法就是做这些事情的。* 当Broker 启动时,它 会调用这个方法启动 ControllerEventThread 线程。值得注意的是,每个 Broker 都需要 做这些事情,* 不是说只有 Controller 所在的 Broker 才需要执行这些逻辑。** 首先,startup 方法会注册 ZooKeeper 状态变更监听器,用于监听 Broker 与 ZooKeeper 之间的会话是否过期。* 接着,写入 Startup 事件到事件队列,然后启动 ControllerEventThread 线程,开始处理事件队列中的 Startup 事件。*/def startup() = {/*** controller组件启动监听器的方式是在zk上面注册一个stateChangeHandler* 在KafkaController.startup()方法中首先通过zk注册监听事件,监听StateChangeHandler* registerStateChangeHandler用于session过期后触发重新选举** 第1步:注册Zookeeper状态变更监听器,它是用于监听Zookeeper和broker会话过期的,*/zkClient.registerStateChangeHandler(new StateChangeHandler {override val name: String = StateChangeHandlers.ControllerHandleroverride def afterInitializingSession(): Unit = {eventManager.put(RegisterBrokerAndReelect)}override def beforeInitializingSession(): Unit = {val expireEvent = new ExpireeventManager.clearAndPut(expireEvent)// Block initialization of the new session until the expiration event is being handled,// which ensures that all pending events have been processed before creating the new session/*** 阻塞等待时间被处理结束,session过期触发重新选举,必须等待选举这个时间完成Controller才能正常工作*/expireEvent.waitUntilProcessingStarted()}})/** Startup是一个ControllerEvent,ControllerEventThread会执行它的process方法* Startup 类型的 ControllerEvent 被放入到 eventmanager中,被 KafkaController#process 方法调用,在下面有定义* 在Startup的回调方法process()中,首先在zk中监听/controller路径。并且调用elect()进行选举过程。** case object Startup extends ControllerEvent {* def state = ControllerState.ControllerChange* override def process(): Unit = {* zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)* // elect就是尝试竞选controller* elect()* }* }** 调用elect(),进行选举,在onControllerFailover()中* 放入Startup并启动eventManager后台线程开始选举, Startup 是个事件** put 方法 在 core/src/main/scala/kafka/controller/ControllerEventManager.scala#def put(event: ControllerEvent): Unit = inLock(putLock) {* 第2步:写入Startup事件到事件队列*/eventManager.put(Startup)/** 启动了ControllerEventManager* KafkaController#startup 中为每一个 server 都会启动一个 eventManage* 启动eventManager来处理event queue中的任务** ControllerEventThread在* core/src/main/scala/kafka/controller/ControllerEventManager.scala中定义** 第3步:内部启动ControllerEventThread线程,开始处理事件队列中的ControllerEvent*/eventManager.start()}
(二)Controller选举流程【主要看写的源码注释】
/*** elect方法是关于Controller选举的核心方法* elect就是尝试竞选controller,如果我们当前节点真的被选为controller(onControllerFailover()–故障转移)* */private def elect(): Unit = {/** 获取zk /controller节点中的brokerId,没有返回-1* 第1步:获取当前Controller所在Broker的序列号,如果Controller不存在,显式标记为-1*/activeControllerId = zkClient.getControllerId.getOrElse(-1)/*** 开始创建临时节点前检查,如果/controller节点已经存在,说明已经有broker成为controller,* 因此本broker直接退出controller选举* 第2步:如果当前Controller已经选出来了,直接返回即可*/if (activeControllerId != -1) {/** 在初始化的时候可能会走到这里,如果当前controller不空,则退出选举* [2020-11-06 13:27:50,200] INFO [ControllerEventThread controllerId=19] Starting (kafka.controller.ControllerEventManager$ControllerEventThread)* [2020-11-06 13:27:50,208] DEBUG [Controller id=19(当前机器的Broker ID)] Broker 13 has been elected as the controller, so stopping the election process. (kafka.controller.KafkaController)*/debug(s"Broker $activeControllerId has been elected as the controller, so stopping the election process.")return}try {/*** //所谓选举,就是抢占zk上面一个节点,如果抛异常说明未能选举上* registerControllerAndIncrementControllerEpoch在zk/KafkaZkClient.scala* 创建临时节点,声明本broker成为controller* 主要是创建/controller节点* 尝试去创建/controller节点,如果创建失败了(已存在),会在catch里处理** registerControllerAndIncrementControllerEpoch 方法在 zk/KafkaZkClient.scala*/val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)controllerContext.epoch = epochcontrollerContext.epochZkVersion = epochZkVersion/** ControllerId就是当前主机的 brokerId */activeControllerId = config.brokerId/** 未抛异常说明写入创建成功,本broker荣升为controller */info(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} " +s"and epoch zk version is now ${controllerContext.epochZkVersion}")/** 成为Controller后,主要做的工作* 第4步:执行当选Controller的后续逻辑*/onControllerFailover()} catch {case e: ControllerMovedException =>maybeResign()/** 如果/controller已存在, brokerid就不会是-1* {"version":1,"brokerid":0,"timestamp":"1582610063256"}*/if (activeControllerId != -1)debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)else/** 上一届controller刚下台,节点还没删除的情况 */warn("A controller has been elected but just resigned, this will result in another round of election", e)case t: Throwable =>error(s"Error while electing or becoming controller on broker ${config.brokerId}. " +s"Trigger controller movement immediately", t)/** 遇到不可知错误,取消zk相关节点的监听注册,并调用删除/controller的zk的node */triggerControllerMove()}}
(三)成为Controller后的初始化工作【主要看写的源码注释】
/*** 真正复杂的是broker在成为Controller之后,在onControllerFailover方法中进行的一系列初始化动作** .启动controller的channel manager用于接收请求* 3.启动replica的状态机,监测replica是OnlineReplica还是OfflineReplica的状态。这里的offline是指该replica的broker已经挂掉。* 4.启动partition的状态机,监测partition是OnlinePartition还是OfflinePartition。这里的offline是指该partion的leader已经挂掉。* 5.启动自动的leader分配rebalance(如果启动设置)*/private def onControllerFailover() {info("Registering handlers")// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacks/*** 在读取zk之前注册brokerchange, topicchange, topicdeletion, logDirEventNoti,isrChange事件,* 从这行及下面事件注册也看出control在集群中的作用* 注册一组childrenChangeHandler,在NodeChildrenChange事件触发后,会分发给这些handler* handler 监听的zk节点 事件 ControllerEvent 功能*--------------------------------------------------*brokerChangeHandler /brokers/ids childChange BrokerChange*topicChangeHandler /brokers/topics childChange TopicChange*topicDeletionHandler /admin/delete_topics childChange TopicDeletion*logDirEventNotificationHandler /log_dir_event_notification childChange LogDirEventNotification*isrChangeNotificationHandler /isr_change_notification childChange IsrChangeNotification*partitionReassignmentHandler /admin/reassign_partitions create PartitionReassignment 执行副本重分配*preferredReplicaElectionHandler /admin/preferred_replica_election create PreferredReplicaLeaderElection Preferred leader副本选举** 其中brokerChangeHandler(new BrokerChangeHandler(this,eventManager)为Broker数据量zookeeper监听器 )*//** 注册各种监听器 */val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,isrChangeNotificationHandler)/** 注册对broker数据量监听器 */childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)/*** 注册/admin/preferred_replica_election, /admin/reassign_partitions节点事件处理* 也是注册,不过要检查节点是否存在(这里不对是否存在做处理,只是保证没有异常)*/val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)info("Deleting log dir event notifications")/*** 删除节点:/log_dir_event_notification/log_dir_event_xxx,/isr_change_notification/isr_change_xxx节点*//*** 删除log_dir_event_notification这个目录下面的子节点* 清理已存在的LogDirEventNotifications在zk上的记录*/zkClient.deleteLogDirEventNotifications(controllerContext.epochZkVersion)info("Deleting isr change notifications")/*** 删除isr_change_notification这个目录下面的子节点* 清理已存在的IsrChangeNotifications在zk上的记录*/zkClient.deleteIsrChangeNotifications(controllerContext.epochZkVersion)info("Initializing controller context")/*** 初始化controller的上下文* 在initializeControllerContext()中:* 1. 注册监听所有topic的partitionModification事件* 2. 从zk中获取所有topic的副本分配信息* 3. 在zk中监听所有broker的更新情况* 4. 从zk中读取topicPartition的leadership,更新本地缓存* 5. 初始化ControllerChannelManager,为每个broker生成一个后台通信线程用于和broker通信,并启动后台线程* 6. 从zk的/admin/reassign_partitions路径下读取partition的reassigned信息放入缓存用于后续处理** 初始化 controller 相关的变量信息:包括 alive broker 列表、partition 的详细信息等*//** 初始化集群元数据,元数据对象ControllerContext */initializeControllerContext() /** 初始化 controller 相关的变量信息 */info("Fetching topic deletions in progress")/*** 获取所有待删除的topic* 要删除的topics和删除失败的topics*/val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()info("Initializing topic deletion manager")/*** 初始化ControllerContext之后,接下来是topicDeletionManager——topic删除管理器的初始化* 注:topic删除只会在delete.topic.enable为true时才能进行,而且分阶段进行删除* 初始化通过topicDeletionManager,如果isDeleteTopicEnabled则在zk中直接删除topicsToBeDeleted** 初始化topic删除管理器*/topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)info("Sending update metadata request")/*** 同步一下live的broker列表* controller context 初始化结束之后发送请求更新metadata,这是因为需要在brokers能处理LeaderAndIsrRequests前获取哪些brokers是live的,** 在 controller contest 初始化之后,我们需要发送 UpdateMetadata 请求在状态机启动之前,这是因为 broker 需要从 UpdateMetadata 请求* 获取当前存活的 broker list, 因为它们需要处理来自副本状态机或分区状态机启动发送的 LeaderAndIsr 请求** 在处理LeaderAndIsrRequest请求之前,先更新所有broker以及所有partition的元数据* 是为后面的副本状态机,分区状态机的启动做准备,将元数据同步给其它broker,让它们可以处理LeaderAndIsrRequest请求*/sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq, Set.empty)/*** 启动副本状态机,初始化zk中所有副本的状态* 如果是online的副本则标记为OnlineReplica状态,否则标记为ReplicaDeletionIneligible* 生成LeaderAndIsrRequest请求并发送到对应brokerId** 初始化 replica 的状态信息: replica 是存活状态时是 OnlineReplica, 否则是 ReplicaDeletionIneligible*/replicaStateMachine.startup()/*** 启动分区状态机,初始化分区状态至OnlinePartition,对于那些NewPartition,OfflinePartition状态的分区进行选举并在zk中更新updateLeaderAndIsr** 初始化 partition 的状态信息:如果 leader 所在 broker 是 alive 的,那么状态为 OnlinePartition,否则为 OfflinePartition* 并状态为 OfflinePartition 的 topic 选举 leader*/partitionStateMachine.startup()info(s"Ready to serve as the new controller with epoch $epoch")/*** 判断是否需要重新分配partition* 检查是否topic的partition的副本需要重新分配(reassign),* 如果partitionsBeingReassigned缓存中的分配信息和controllerContext缓存中不一致,则需要触发重新分配** 分区副本重分配的方法入口是maybeTriggerPartitionReassignment方法,* 该方法会在Controller初始化和PartitionReassignment事件处理器中调用*/maybeTriggerPartitionReassignment(controllerContext.partitionsBeingReassigned.keySet)topicDeletionManager.tryTopicDeletion()/** Preferred leader副本选举* 首先是通过fetchPendingPreferredReplicaElections获取要进行Preferred leader副本选举的分区* */val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()/*** onPreferredReplicaElection方法通过分区状态机,将分区转换为OnlinePartition状态,* 并根据PreferredReplicaPartitionLeaderElectionStrategy选举leader,*/onPreferredReplicaElection(pendingPreferredReplicaElections, ZkTriggered)info("Starting the controller scheduler")/** 定时任务 */kafkaScheduler.startup()if (config.autoLeaderRebalanceEnable) {scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS)}if (config.tokenAuthEnabled) {info("starting the token expiry check scheduler")tokenCleanScheduler.startup()tokenCleanScheduler.schedule(name = "delete-expired-tokens",fun = () => tokenManager.expireTokens,period = config.delegationTokenExpiryCheckIntervalMs,unit = TimeUnit.MILLISECONDS)}}
(四)从KafkaController类看Controller的主要工作【主要看写的源码注释】
/** config: Kafka配置信息* zkClient:Zk客户端,Controller与zookeeper交互使用该属性* Time, 时间戳工具类* initialBrokerInfo: Broker 节点信息,hostname,port等* initialBrokerEpoch: Controller所在Broker的Epoch值 *//*** KafkaController#startup之前,需要说明下KafkaController中有很多成员变量,主要分为* zk事件处理器(ZNodeChangeHandler,ZNodeChildChangeHandler)* StateMachine(有限状态机): 副本的状态机,分区的状态机,主要负责状态的维护及转换时的处理* ControllerContext:broker,topic,partition,replica相关的数据缓存* ControllerEventManager: zk事件管理器,*/class KafkaController(val config: KafkaConfig, zkClient: KafkaZkClient, time: Time, metrics: Metrics,initialBrokerInfo: BrokerInfo, initialBrokerEpoch: Long, tokenManager: DelegationTokenManager,threadNamePrefix: Option[String] = None) extends Logging with KafkaMetricsGroup {this.logIdent = s"[Controller id=${config.brokerId}] "private var brokerInfo = initialBrokerInfoprivate var _brokerEpoch = initialBrokerEpochprivate val stateChangeLogger = new StateChangeLogger(config.brokerId, inControllerContext = true, None)/*** 实例化上下文* broker,topic,partition,replica相关的数据缓存* 维护上下文信息,缓存 ZK 中记录的整个集群的元数据信息*/val controllerContext = new ControllerContext// have a separate scheduler for the controller to be able to start and stop independently of the kafka server// visible for testingprivate[controller] val kafkaScheduler = new KafkaScheduler(1)// visible for testing ,/** ControllerEventManager: zk事件管理器* ControllerEventManager 在core/src/main/scala/kafka/controller/ControllerEventManager.scala* 初始化eventManager,对ControllerEvent事件进行管理** KafkaController重要属性* activeControllerId:获取controller的主broker的id* eventManager: ControllerEventManager实例,负责处理事件** */private[controller] val eventManager = new ControllerEventManager(config.brokerId,controllerContext.stats.rateAndTimeMetrics, _ => updateMetrics(), () => maybeResign())/** topic 删除管理*/val topicDeletionManager = new TopicDeletionManager(this, eventManager, zkClient)/** Controller 给 其他broker 发送批量请求 , 这里有一个比较重要的对象,就是 ControllerBrokerRequestBatch 对象,* 在ControllerChannelManager.scala中定义* */private val brokerRequestBatch = new ControllerBrokerRequestBatch(this, stateChangeLogger)/** StateMachine(有限状态机): 副本的状态机,分区的状态机,主要负责状态的维护及转换时的处理 *//** 管理集群中所有副本状态的状态机 */val replicaStateMachine = new ReplicaStateMachine(config, stateChangeLogger, controllerContext, topicDeletionManager, zkClient, mutable.Map.empty, new ControllerBrokerRequestBatch(this, stateChangeLogger))/** 管理集群中所有分区状态的状态机 */ffval partitionStateMachine = new PartitionStateMachine(config, stateChangeLogger, controllerContext, zkClient, mutable.Map.empty, new ControllerBrokerRequestBatch(this, stateChangeLogger))partitionStateMachine.setTopicDeletionManager(topicDeletionManager)/** Controller 控制的 事件 *//** Controller 节点 zookeeper 监听器*/private val controllerChangeHandler = new ControllerChangeHandler(this, eventManager)/** Broker zookeeper 监听器*/private val brokerChangeHandler = new BrokerChangeHandler(this, eventManager)/** Broker 节点信息变更 zookeeper 监听器 */private val brokerModificationsHandlers: mutable.Map[Int, BrokerModificationsHandler] = mutable.Map.empty/** 主题数量 zookeeper 监听器 */private val topicChangeHandler = new TopicChangeHandler(this, eventManager)/** 主题删除 zookeeper 监听器 */private val topicDeletionHandler = new TopicDeletionHandler(this, eventManager)/** 主题分区变更 zookeeper 监听器 */private val partitionModificationsHandlers: mutable.Map[String, PartitionModificationsHandler] = mutable.Map.empty/** 主题分区重分配 zookeeper 监听器* 分区副本重分配主要由/admin/reassign_partitions节点的create事件触发,该事件的处理器为partitionReassignmentHandler,* */private val partitionReassignmentHandler = new PartitionReassignmentHandler(this, eventManager)/** Preferred Leader 选举zookeeper 监听器*/private val preferredReplicaElectionHandler = new PreferredReplicaElectionHandler(this, eventManager)/** ISR副本集群变更 zookeeper 监听器 */private val isrChangeNotificationHandler = new IsrChangeNotificationHandler(this, eventManager)/** 日志路径变更 zookeeper 监听器*/private val logDirEventNotificationHandler = new LogDirEventNotificationHandler(this, eventManager)
(五)其他源码部分
Controller还有几个重要部分的源码:
Controller 发送模型NetWork
ControllerChannelManager
Controller-Partition状态机
Controller-Replica状态机
Controller-分区副本重分配(PartitionReassignment)与Preferred leader副本选举
Controller-Broker的上线与下线
Controller-LeaderAndIsr请求
Topic 的新建/扩容/删除
由于代码和注释比较多,在此略过。
参考资料:
1.Kafka运维填坑
2.Matt's Blog
3.What is Kafka’s controller broker
4.ZooKeeper:A Distributed Coordination Service for Distributed Applications
作者简介

袁吉
腾讯运营规划工程师
腾讯运营规划工程师,目前负责腾讯游戏万亿级实时数仓、BG数据中台的运营工作。有丰富的消息中间件,分布式大数据处理引擎的运营管理经验。
推荐阅读
如何在C++20中实现Coroutine及相关任务调度器?(实例教学)
