揭开KPI异常检测顶级AI模型面纱(2)
团队名称:sh
01
赛题介绍
这里存在几个难点:
1
异常发生的频率很低,网元数据很少发生故障,因此可供分析的异常数据很少。
2
异常种类多,核心网网元数据多,故障发生的类型也多种多样,导致了异常种类也多种多样。
3
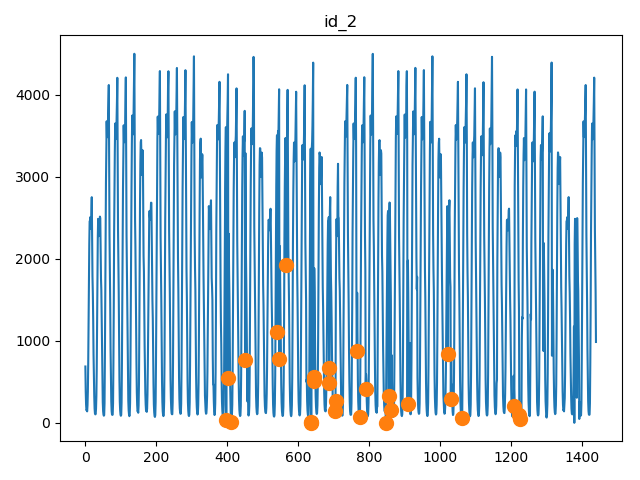
KPI曲线的多样性,KPI曲线表现为周期型的,有稳定型的,也有不稳定型的
02
数据理解
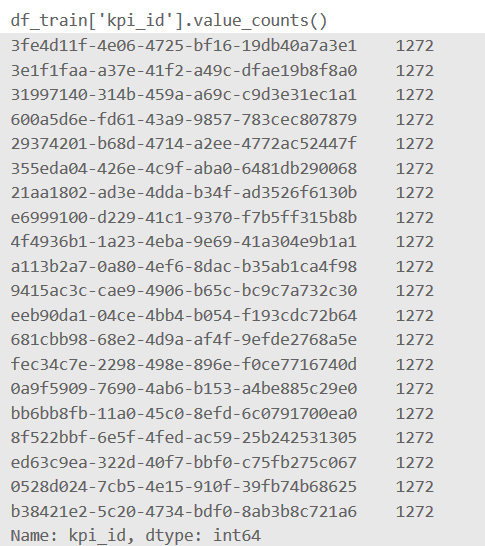
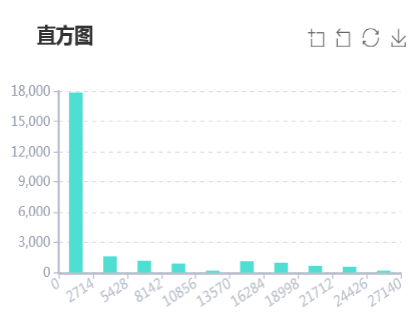
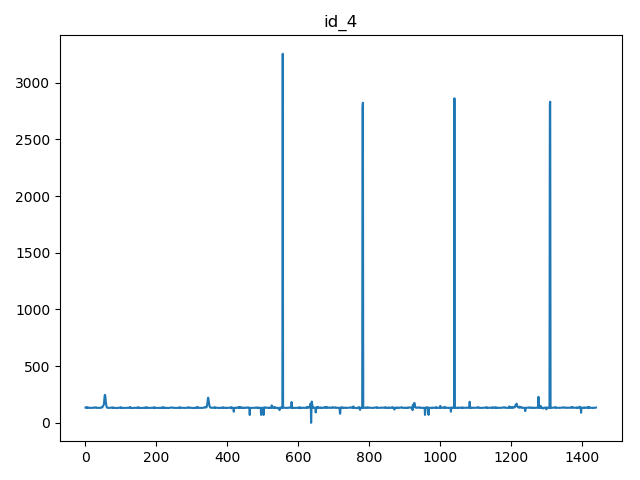
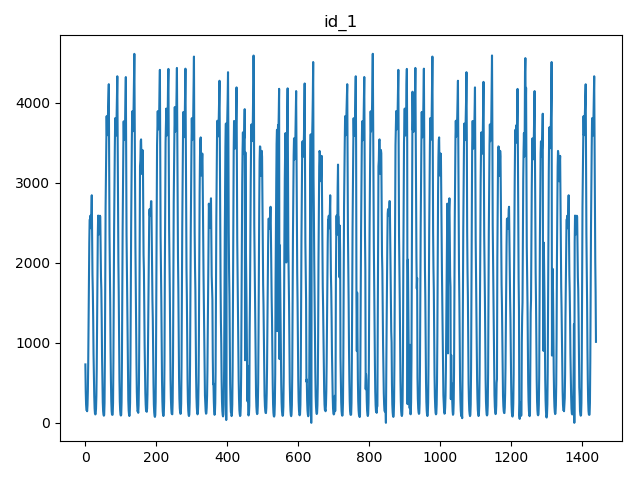
给定的数据一共包含20种不同的kpi_id:
03
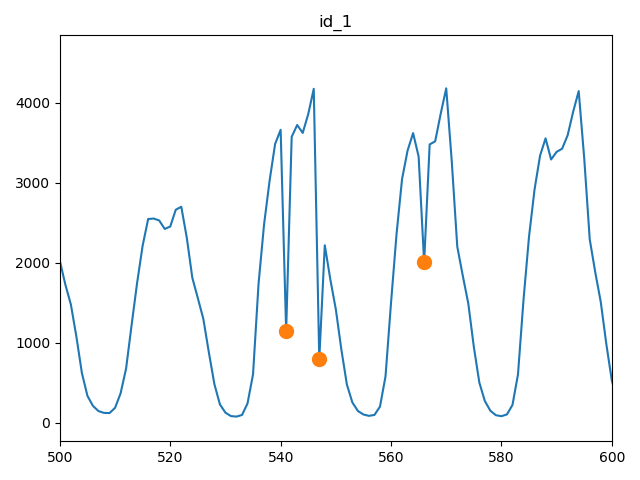
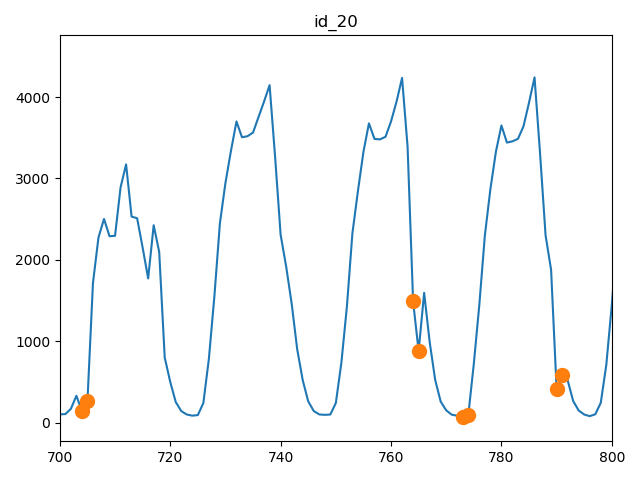
特征工程

04
模型和方案选择
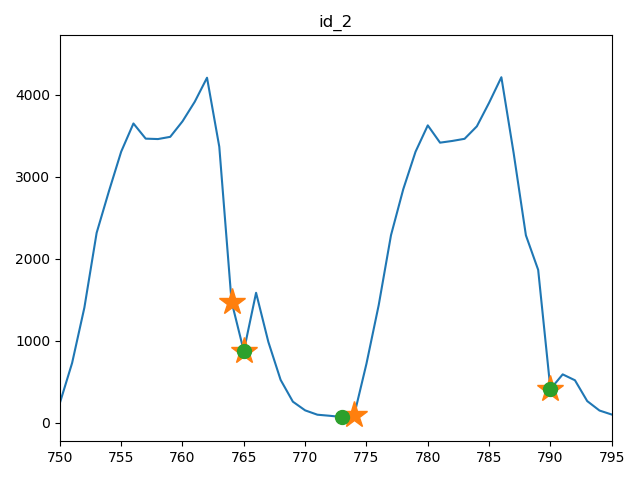
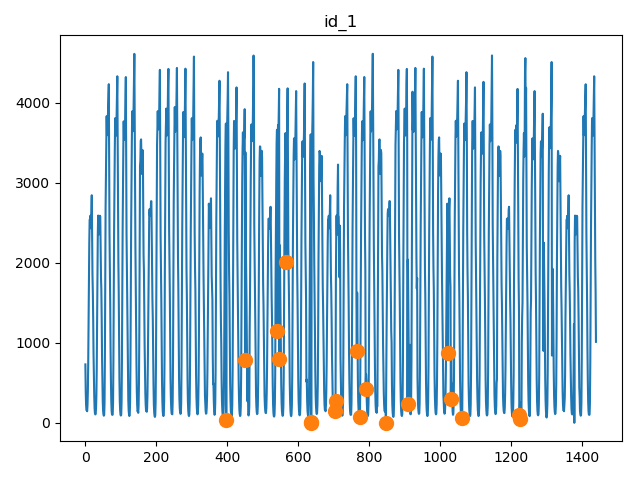
05
总结和鸣谢
加群交流学习
评论
 下载APP
下载APP团队名称:sh
01
赛题介绍
这里存在几个难点:
1
异常发生的频率很低,网元数据很少发生故障,因此可供分析的异常数据很少。
2
异常种类多,核心网网元数据多,故障发生的类型也多种多样,导致了异常种类也多种多样。
3
KPI曲线的多样性,KPI曲线表现为周期型的,有稳定型的,也有不稳定型的
02
数据理解
给定的数据一共包含20种不同的kpi_id:
03
特征工程
04
模型和方案选择
05
总结和鸣谢
加群交流学习