
【EMNLP2020】控制对话生成中的specificity
本文介绍一篇2020EMNLP-findings上的论文《Consistent Response Generation with Controlled Specificity》,介绍在对话生成中控制回复的specificity。
所谓specificity,我把它翻译成“具体的程度”,举个例子,我跟机器说:“今天天真冷”,机器可以以三种不同的specificity回答我:
- 是的
- 确实挺冷的
- 哎呀 心疼 喝热水,多穿 快回 外面冷,你忙 好梦 早点睡,早安 晚安 睡了没,确实冷,多喝热水注意保暖别着凉了

谁不想要一个像第3种这么贴心的聊天机器人呢?(
这篇论文其实是作者发表在2019ACL workshop上的工作《Relevant and Informative Response Generation using Pointwise Mutual Information》的延续。
这篇论文提出了一个叫做Positive Pointwise Mutual Information(PPMI)的东西,首先使用PPMI给训练集中的每个word打分,找出keywords,设计了一个loss,鼓励模型生成属于keywords的单词,做法和下面要介绍的论文大同小异。
PPMI的定义如下,为单词出现在上句中的概率,为单词出现在回复中的概率,是单词和同时分别出现在一对中的概率,这些概率P都可以通过对训练集预先的统计得到。由此可以得到PPMI矩阵,PPMI[x][y]就是PPMI(x, y)的值,预先存储好以供后面模型使用。
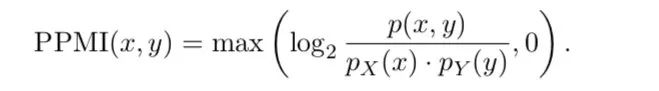
作者进一步提出一条数据的MaxPMI,定义如下
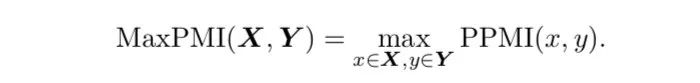
通过min-max normalization将每条数据的MaxPMI分数归一化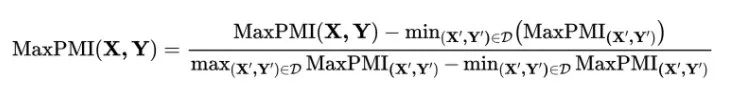
模型的整体架构如下
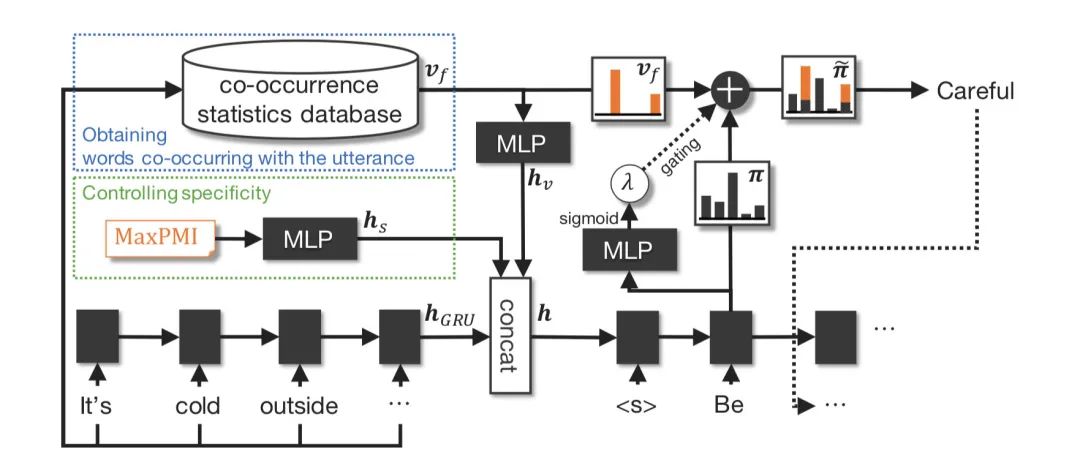 模型架构
模型架构首先对于一条数据,使用GRU将utterance 编码为一个向量,然后把这条数据的MaxPMI分数丢到一个多层全连接网络里(MLP)输出一个vector ,接着把整个词表上的每一个单词和utterance 中所有的单词求PPMI分数之和,得到一个长度和词表大小一样的vector ,
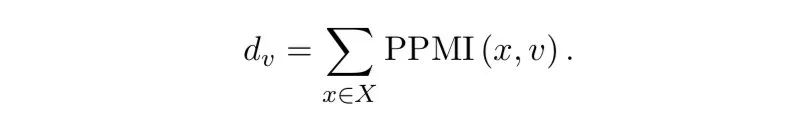
然后,同样地把丢到一个多层全连接网络中输出一个vector ,把得到的三个向量给concat起来得到,把h作为decoder的初始状态,因此decoder应该可以利用PPMI所定义的词与词之间的共现关系,来学习如何生成更具体specific的回复。
为了直接地提升decoder输出更specific的单词的概率,作者还把和decoder在每个timestep i输出的概率通过加权的方式加在了一起得到
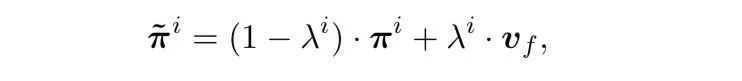
用于平衡二者,由decoder当前输出的隐状态通过一层MLP得出
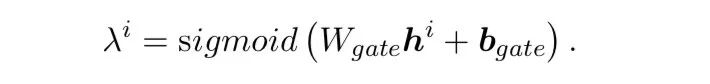
Inference阶段只需要手动定义MaxPMI的值s,就可以生成不同specificity程度的回复。同时作者还提出inference不手动提供值s的方法,可使用下式自动求出的值,是整个词表,是给出的问句
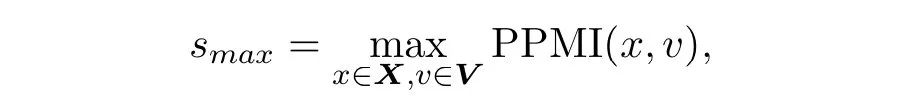
作者的实验在DailyDialog和Twitter(Japanese)上进行,对比的模型是SC-Seq2Seq,它出自ACL2018上的《Learning to Control the Specificity in Neural Response Generation》,同样是控制生成的,最大的区别可能在于本文用的是作者定义的PPMI,那篇也是作者定义了一个指标,并提前告诉decoder每个词的得分。
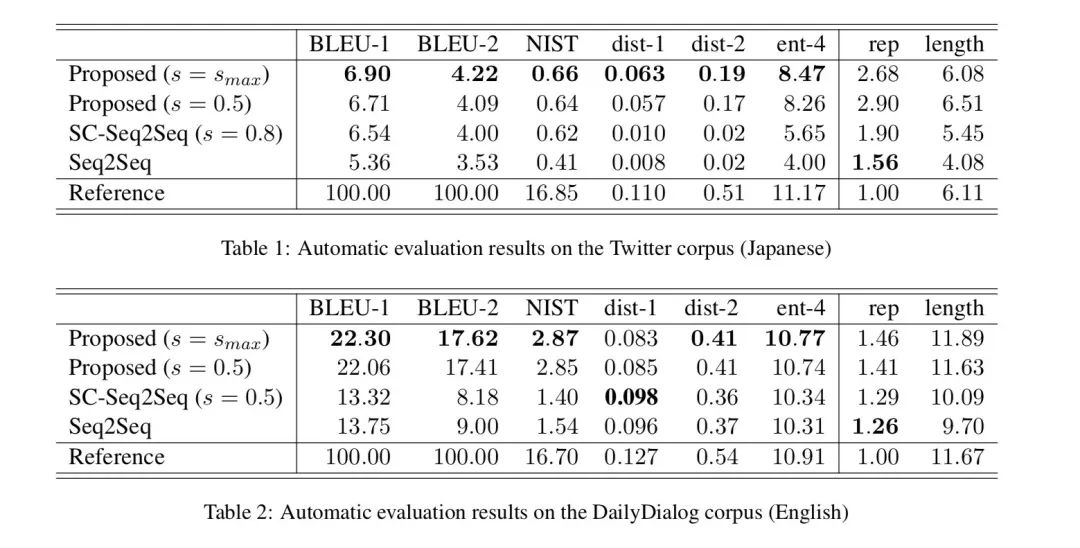
作者发现使用的效果最好
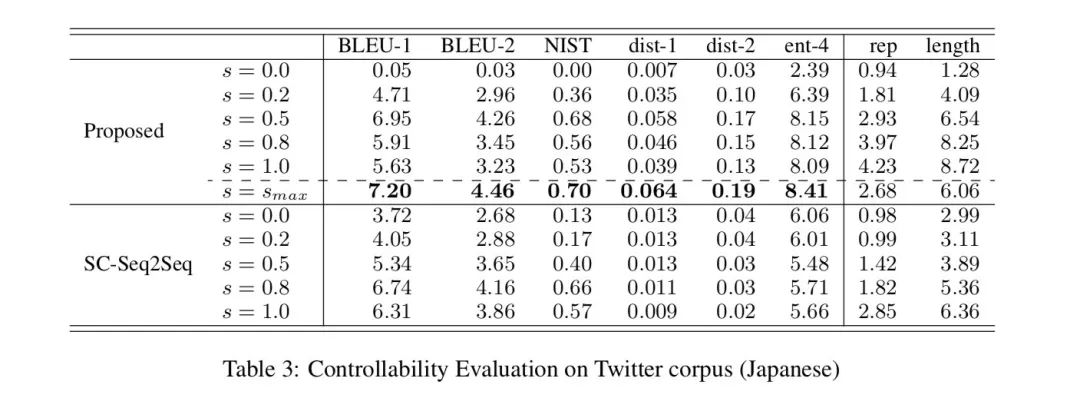
作者也举了一个生成效果的例子,通过控制s的大小可以操控回复的specificity
有什么想法欢迎在评论区讨论,扫码关注加星标以第一时间获得推送文章~