
京东热key探测中间件太火了!竟然单机qps能从2万提升至35万
京东hotkey框架(JD-hotkey)是京东app后台研发的一款高性能热数据探测中间件,用来实时探测出系统的热数据,并将热数据毫秒内推送至系统的业务集群服务器的JVM内存。以下统称为"热key"。
该框架主要用于对任意突发性的无法预先感知的热key,包括并不限于热点数据(如突发大量请求同一个商品)、热用户(如恶意爬虫刷子)、热接口(突发海量请求同一个接口)等,进行毫秒级精准探测到。然后对这些热key,推送到所有服务端JVM内存中,以大幅减轻对后端数据存储层的冲击,并可以由使用者决定如何分配、使用这些热key(譬如对热商品做本地缓存、对热用户进行拒绝访问、对热接口进行熔断或返回默认值)。这些热数据在整个服务端集群内保持一致性,并且业务隔离,worker端性能强悍。
之前在发布过该框架架构设计的文章,详细讲述了框架的工作原理。目前该框架已在京东App后台、数据中台、白条、金融、商家等多十余个业务部门接入运行,目前应用最广泛的场景是刷子(爬虫)用户实时探测和redis热key实时探测。
由于框架自身核心点在于实时(准实时,可配置1-500ms内)探测系统运行中产生的热key,而且还要面临随时可能突发的暴增流量(如突发抢购某商品),还要在探测出热key后在毫秒时间内推送到该业务组的几百、数千到上万台服务器JVM内存中,所以对于它的单机性能要求非常高。
我们知道框架的计算单元worker端,它的工作流程是:启动一个netty server,和业务服务器(数百——上万)建立长连接,业务服务器批量定时(1——500ms一次)上传自己的待测key给worker,worker对发来的key进行滑动窗口累加计算,达到用户设置的阈值(如某个类型的key,pin_xxxx达到2秒20次),则将该key推送至整个业务服务器集群内,从而业务服务器可以在内存中使用这些热key,到达设置的过期时间后会自动过期删除。
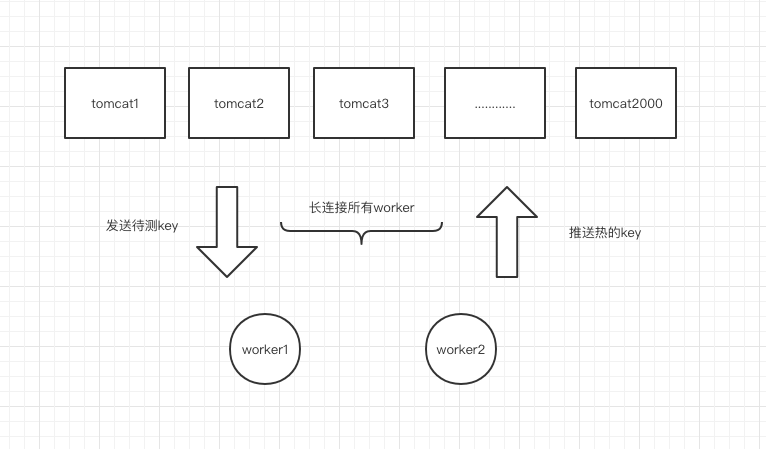
截止目前,该框架0.4版本的性能表现如下(硬件配置为随机机房创建的16核docker容器):
1、key探测计算:每秒可接收N台服务器发来的40多万个待测key,并计算完毕其中的35万左右。实测可每秒稳定计算30万,极限计算37万,超过的量会进入队列等待。
2、热key推送:当热key产生后,对该业务集群所有长连接的服务器进行key推送,每秒可稳定推送10-12万次(毫秒内送达)。譬如1千台服务器,每秒该worker可以支撑产生100个热key,即推送100*1000次。当每秒产生200个热key,即每秒需要推送20万次时,会出现有1s左右的延迟送达。强度压测当每秒要推送50万次时,出现了极其明显的延迟,推送至client端的时间已不可控。在所有积压的key推送完毕后,可继续正常工作。
注意,推送是和接收30万key并行的,也就是进和出加起来吞吐量在40多万每秒。
以上为单机性能表现,通过横向扩展,可以提升对应的处理量,不存在单点问题,横向扩展中无性能瓶颈。以当前的性能表现,单机可以完成1000台业务服务器的热key探测任务。系统设计之初,期望值是单机能支撑200台业务器的日常计算,所以目前性能是高于预期的,在逐步的优化过程中,也遇到了很多问题,本文就是对这个过程中所遇到的与性能有关的问题和优化过程,做个记录。
以下所有数据,不特殊指明的话,均默认是随机机房的16核docker容器,属于共享型资源,实际配置强于8核物理机,弱于16核物理机。
# 初始版本——2万QPS
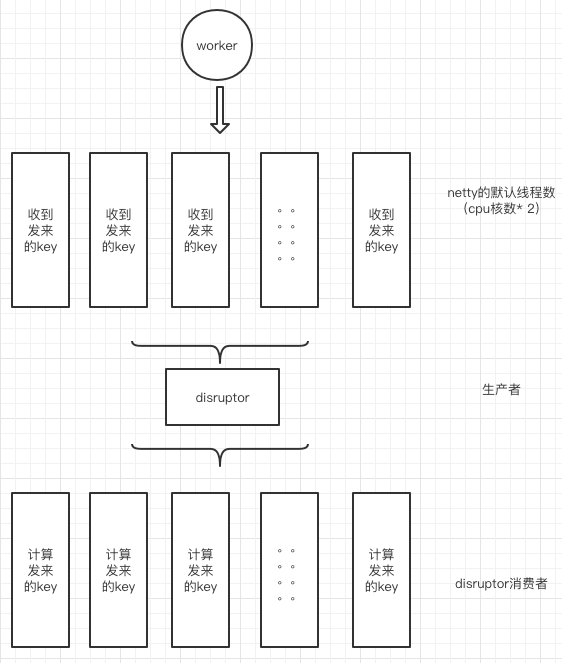
该版本采用的是jdk1.8.20(jdk的小版本影响很大),worker端采用的架构方式为netty默认参数+disruptor重复消费模式。
netty默认开启cpu核数*2个线程,作为netty的工作线程,用于接收几千台机器发来的key,接收到待测key后,全部写入到disruptor的生产者线程,生产者是单线程。之后disruptor同样是cpu核数*2个消费者线程,每个消费者都重复消费每条发来的key。
这里很明显的问题,大家都能看到,disruptor为什么要重复消费每个key?
因为当初的设想是将同一个key固定交给同一个线程进行累加计算,以避免多线程同时累加同一个key造成数量计算错误。所以每个消费者线程都全部消费所有的key,譬如8个线程,线程1只处理key的hash值为1的,其他的return不处理。
该版本上线后,长连接3千台业务服务器,单机每秒处理几千个key的情况下,cpu占用率在20%多。猛一看,貌似还可以接受的样子是吗。
其实不是的,该版本随后经历了618大促压测演练,首次压测,该版本在压测开始的一瞬间就已经生活不能自理了。
首次压测量级只有10万,我有4台worker,平均每台也就2万多秒级key写入,而cpu占用率直接飙升至100%,系统卡的连10s一次的定时任务都不走了,完全僵死状态。
那么问题在哪里?仅通过猜测我们大概考虑是disruptor负载比较重,譬如是不是因为重复消费的问题?
要寻找问题在哪里,进入容器内部,查看top的进程id,再使用top -H -p1234(1234为javaa进行pid),再使用jstack命令导出java各个线程的状态。
在top -H这一步,我们看到有巨多的线程在占用cpu,数量之多,令见者伤心、闻者落泪。
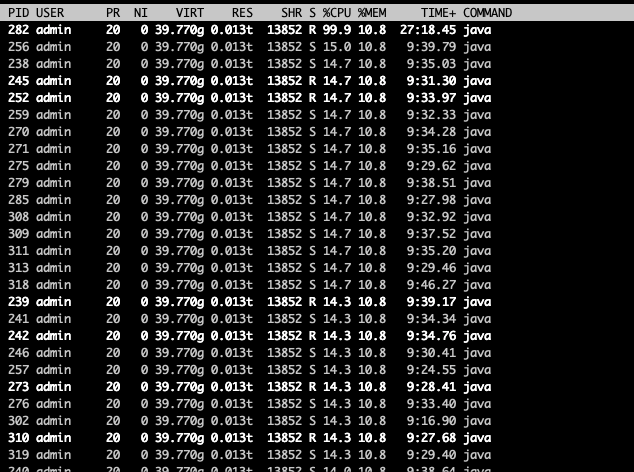
里面有大量的如下
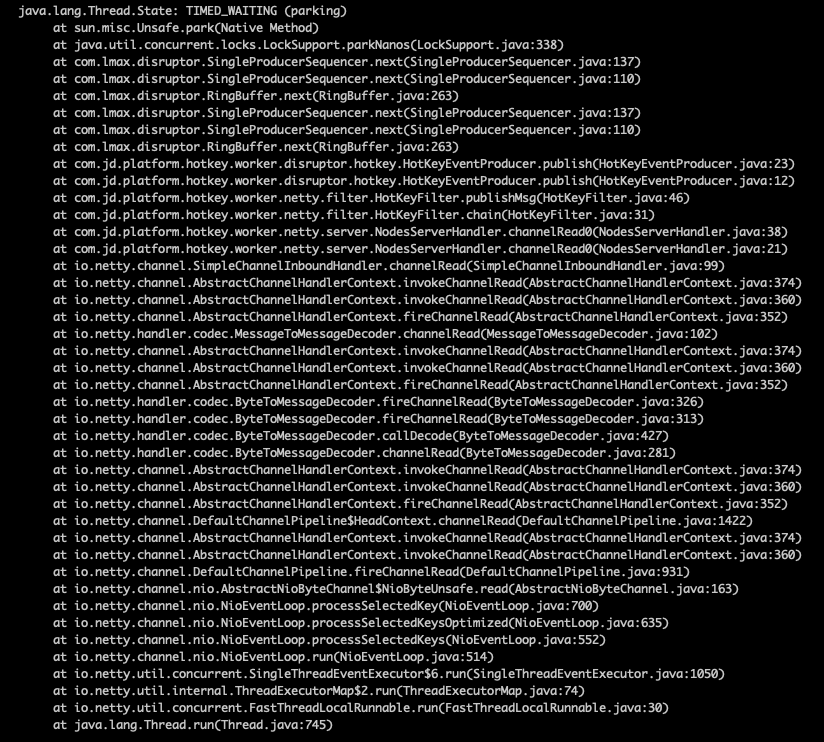
也就是说大量的disruptor消费者线程吃光了cpu,说好的百万并发框架disruptor性能呢?
当然,这次的锅不能给disruptor去背。这次的问题首要罪魁祸首是jdk版本问题,我们使用的1.8.0_20在docker容器内通过
Runtime.getRuntime().availableProcessors()方法获取到的数量是宿主机的核数,而不是分配的核数。
即便只分配这个容器4核8核,该方法取到的却是宿主机的32核、64核,直接导致netty默认分配的高达128个线程,disruptor也是128个线程。这几百个线程一开启,平时空闲着就占用20%多的cpu,压测一开始,cpu直接原地起飞,忙于轮转,瞬间瘫痪。
# 首次优化——10万QPS
jdk在1.8.0_191之后,修复了容器内获取cpu核数的问题,我们首先升级了jdk小版本,然后增加了对不同版本cpu核数的判断逻辑,把线程数降了下来。
这其中我并没有去修改disruptor所有线程都消费key的逻辑,保持了原样。也就是说,16核机器,目前是32个netty IO线程,32个消费者业务线程。再次上线,cpu日常占用率降低到7%-10%左右。
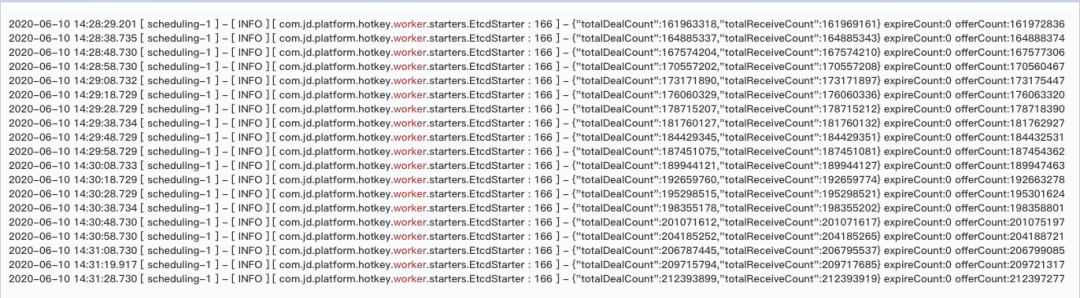
二次压测开始,从下图每10秒打印一次的日志来看,单机秒级计算完毕的key在8万多,同时秒级推送量在10万左右。

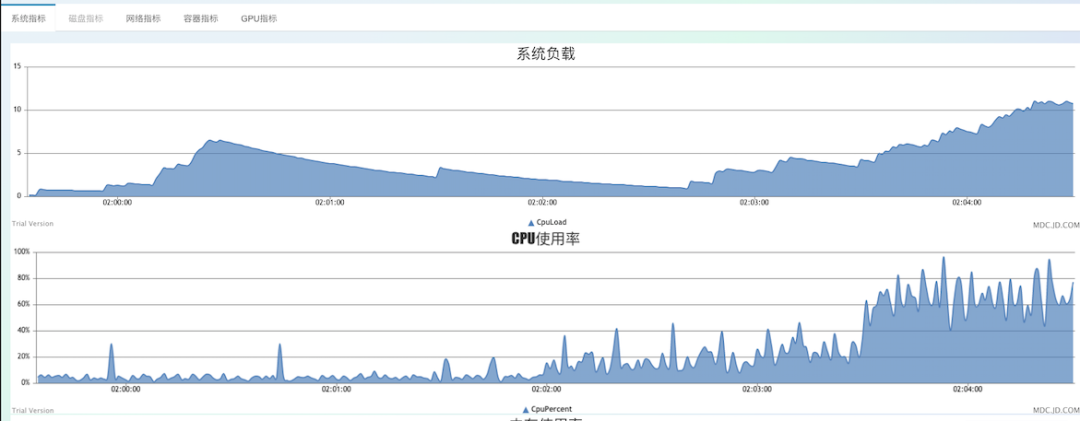
此时cpu已经开始飘高了,当单机秒级达到14万时,CPU接近跑满状态,此时已达线上平稳值上限10万。其中占用cpu较多的依旧是disruptor大量的线程。
# 二次优化——16万QPS
考虑到线程数对性能影响还是很大,该应用作为纯内存计算框架,是典型的cpu密集型,根本不需要那么多的线程来做计算。
我大幅调低了netty的IO线程数和disruptor线程数,并随后进行了多次实验。首先netty的IO线程分别为4和8反复测试,业务线程也调为4和8进行反复测试。
最终得出结论,netty的IO线程在低于4时,秒级能接收到的key数量上限较低,4和8时区别不太大。而业务线程在高于8时,cpu占用偏高。尤其是key发来的量比较少时,线程越多,cpu越高。注意,是发来的key更少,cpu更高,当完全没有key发来时,cpu会比有key时更高。
原因在于disruptor它的策略就是会反复轮询队列是否有可消费的数据,没有数据时,它这个轮询空耗cpu,即便等待策略是BlockingWaitStrategy。
所以,最终定下了IO线程和业务线程分别为8,即核数的一半。一半用来接收数据,一半用来做计算。
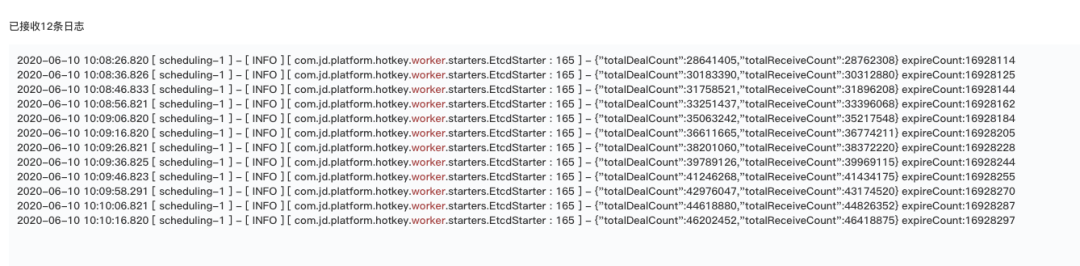
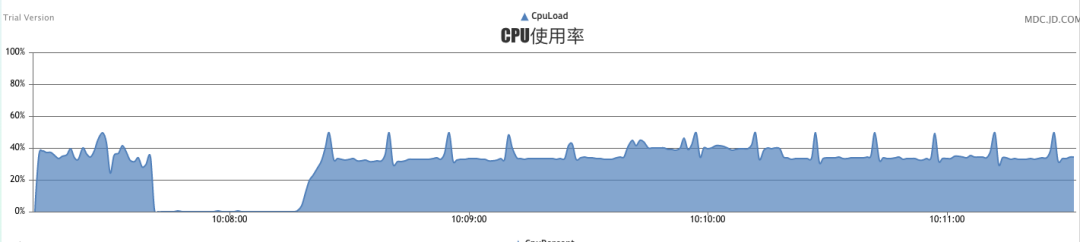
从图上可以看到,秒级可以处理完毕16万个key,cpu占用率在40%。
加大压力源后,实际处理量会继续提升,但此时我对disruptor的实际表现并不满意,总是在每百万key左右就出现几个发来的key在被消费时就已经超时(key发送时比key被处理时超过5秒)的情况。追查原因也无果,就是个别key好像是被遗忘在角落一样,迟迟未被处理。
# 三次优化——25万QPS
由于对disruptor不满意,所以这一次直接丢弃了它,改为jdk自带的LinkedBlockQueue,这是一个读写分别加锁的队列,比ArrayBlockQueue性能稍好,理论上不如disruptor性能好。
原因大家应该都清楚,首先ArrayBlockQueue读写同用一把锁,LinkedBlockQueue是读一把锁、写一把锁,ArrayBlockQueue肯定是性能不如LinkedBlockQueue。
disruptor采用ringbuffer环形队列,如果生产消费速率相当情况下,理论上读写均无锁,是生产消费模型里理论上性能最优的。然而,一切都要靠场景和最终成绩来说话,网上抛开了这些单独谈框架性能其实没有什么意义。
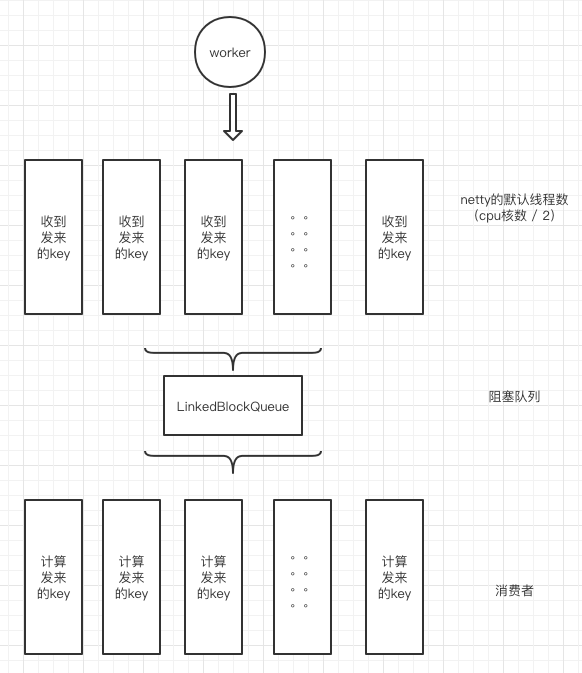
同样是8线程读取key然后写入到队列,8线程死循环消费队列。此时已经不会重复消费了,我采用了别的方式来避免多线程同时计算同一个key的数量累加问题。
再次上线后,首先非常明显的变化就是再也没有key被处理时发生超时的情况了,之前每百万必出几个,而这个Queue几亿也没一个超时的,每个写入都会迅速被消费。另一个非常直观的感受就是cpu占用率明显下降。
在平时的日常生产环境,disruptor版在秒级几千key,3千个长连接情况下,cpu占用在7%-10%之间,不低于5%。而BlockQueue版上线后,日常同等状态下,cpu占用率0.5%-1%之间,即便是后来我加入了秒级监控这个单线程挺耗资源的逻辑(该逻辑会统计累加所有client每秒的key访问数据,单线程cpu占用单核50%以上),cpu占用率也才在1.5%,不超过2%。
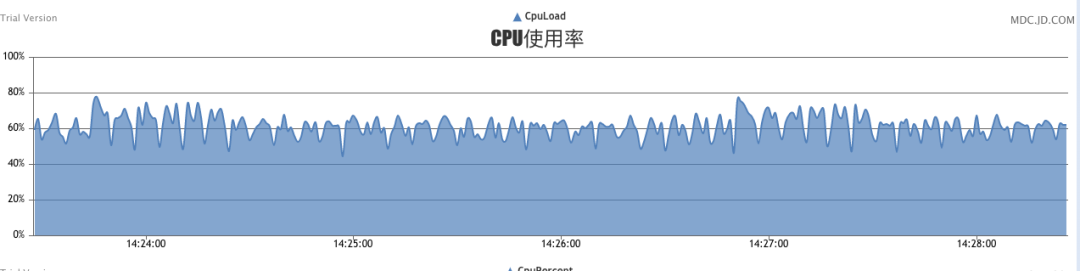
此时压测可以看到,秒级处理量能达到25-30万,cpu占用率在70%。cpu整体处于比较稳定的状态,该压测持续N个小时,未见任何异常。
并且该版也进行过并发写入同时对推送的压测,稳定推送每秒10-12万次可保持极其稳定毫秒级送达的状态。在20万次时开始出现延迟送达,极限每秒压至48万次推送,出现大量延迟,部分送达至业务client时延迟已超过5秒,此时我们认为热key毫秒级推送功能在如此延迟下已不能达到既定目的。读写并行情况下,吞吐量在40万左右。
这一版也是618大促期间线上运行的版本(秒级监控是618后加入的功能)。
# 最近优化——35万QPS
之前所有版本,都是通过fastjson进行的序列化和反序列化,两端通信时交互的对象都是fastjson序列化的字符串,采用netty的StringDecoder进行交互。
这种序列化和反序列化方式在平时使用中,性能处于足够的状态,几千几万个小对象序列化耗时很少。大家都知道一些其他的序列化方式,如protobuf、msgPack等。
本地测试很容易,搞个只有几个属性的对象,做30万次序列化、反序列化,对比json和protobuf的耗时区别。30万次,大概相差个300-500ms的样子,在量小时几乎没什么区别,但在30万QPS时,差的就是这几百ms。
网上相关评测序列化方式的文章也很多,可以自行找一些看看对比。
在更换序列化方式,修改netty编解码器后,压测如图:
秒级16万时,cpu大概25%。

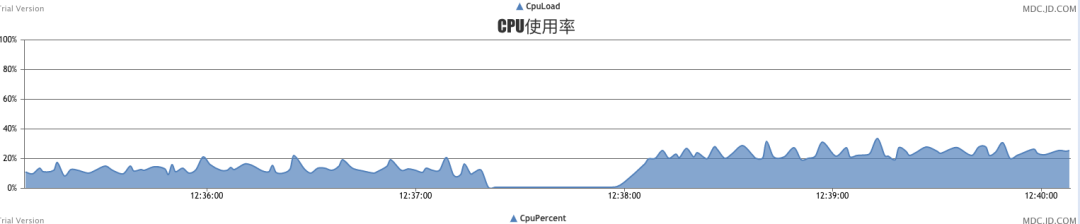
秒级36.5万时,cpu在50%的样子。
此时,每秒压力机发来的key在42万以上,但处理量维持在36万左右,不能继续提升。因为多线程消费LinkedBlockQueue,已达到该组件性能上限。netty的IO线程尚未达到接收上限。

# 争议项
其实从上面的生产消费图大家都能看出来,所有netty收到的消息都发到了BlockQueue里,这是唯一的队列,生产消费者都是多线程,那么必然是存在锁竞争的。
很多人都会考虑为何不采用8个队列,每个线程只往一个队列发,消费者也只消费这一个线程。或者干脆去掉队列,直接消费netty收到的消息。这样不就没有锁竞争了吗,性能不就能再次起飞?
这个事情自然我也是多次测试过了,首先通过上面的压测,我们知道瓶颈是在BlockQueue那里,它一秒被8线程消费了37万次,已经不能再高了,那么8个队列只要能超过这个数值,就代表这样的优化是有效的。
然而实际测试结果并不让人满意,分发到8个队列后,实际秒级处理量骤降至25万浮动。至于直接在netty的IO线程做业务逻辑,这更不可取,如果不小心可能导致较为严重的积压,甚至导致客户端阻塞。
虽然网上很多文章都专门讲锁竞争导致性能下降,避免锁来提升性能,但在这种30万以上的场景下,实践的重要性远大于理论。至于为什么会性能变差,就留给大家思考一下吧。
# 后记
可能大家觉得哇塞你这个调优好简单,我也学会了,就是减少线程数,那么实际是这样吗?
我们再来看看,线程少时导致吞吐量大幅下降的场景。
之前我们的测试都是说每秒收到了多少万个key,处理了多少万个key,大部分负载都是处理key上。现在我们来测试一下纯推送量,只接收很少的key,然后让所有的key都是热key,开启很多个客户端,每秒推送很多次。
测试是这样的,由一个单独的client每秒发送1万个key到单个worker,设置变热规则为1,那么这1万个就全是热key,然后我分别采用40、60、80、100个client端机器,这样就意味着每秒单个worker要推送40、60、80、100万次,通过观察client端每秒是否接收到了1万个热key推送来判断worker的推送极限。
首先还是使用上面的配置,即8个IO线程,8个消费者线程。

可以看到8线程在每秒推送40万次时比较稳定,在client端打日志也是基本1秒1万个全部收到,没有超时的情况。在60万次时,cpu大幅抖动,大部分能及时推送到达,但开始出现部分超时送达的情况。上到60万以上时,系统已不可用,大量的超时,所有信息都超时,开始出现推送积压,堆外内存持续增长,逐渐内存溢出。
调大IO线程至16,推送量每秒60万:
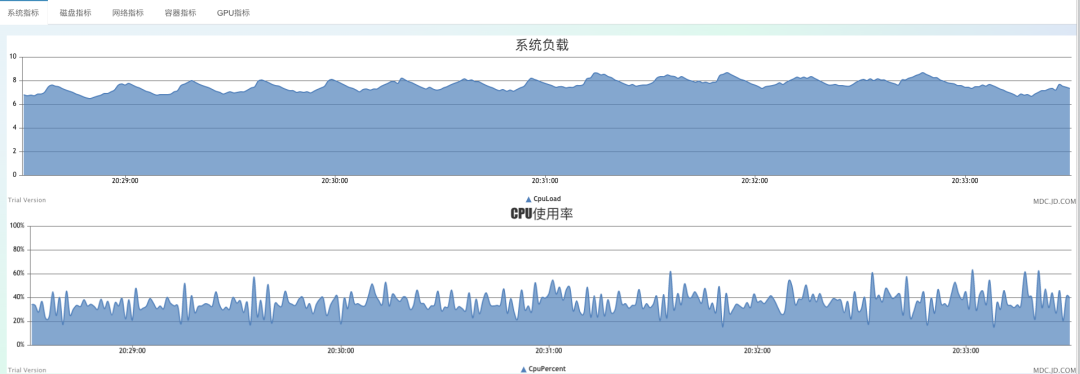
持续运行较长时间,cpu非常稳定,未出现8线程时那种偶尔大幅抖动的情况,稳定性比之前的8线程明显好很多。
随后我加大到80个客户端,即每秒推送80万次。
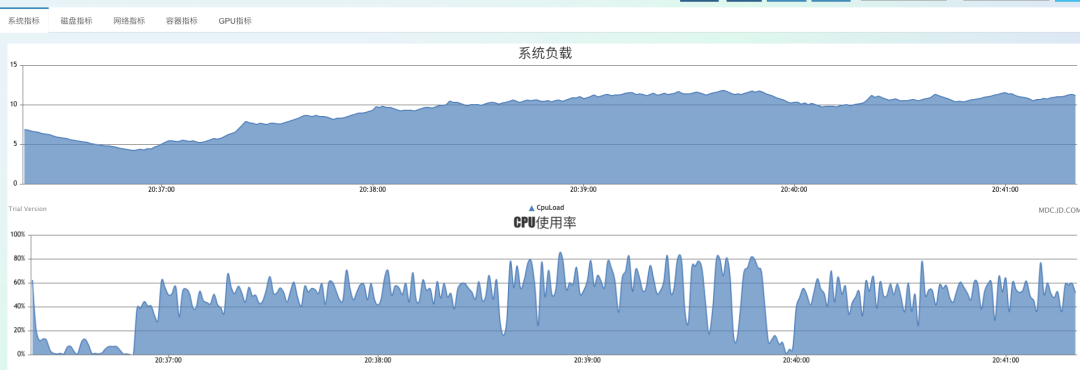
总体还是比较平稳,cpu来了60%附近,full gc开始变得频繁起来,几乎每20秒一次,但并未出现大量的超时情况,只有full gc那一刻,会有个别key在到达client时超过1秒。系统开始出现不稳定的情况。
我加大到100个client,即每秒要推送100万次。
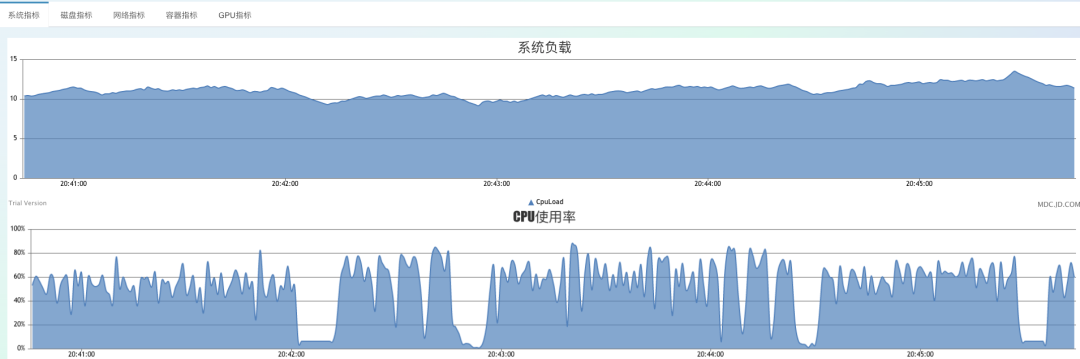
此时系统已经明显不堪重负,full gc非常密集,cpu开始大幅抖动,大量的1秒超时,整体已经不可控了,持续运行后,就会开始出异常,内存溢出等问题。
通过对纯推送的压测,发现更多的IO线程,几乎可以到达每秒70万推送稳定,比8线程的时候40多万稳定,强了不是一点点。同样一台机器,仅改了改线程数量而已。
那么问题又来了,我们应该怎么去配置这个线程数量呢?
那么就有实际场景了,你是到底每秒有很多key要探测、但是热的不多,还是探测量一般般、但是阈值调的低、热key产生多、需要每秒推送很多次。归根到底,是要把计算资源让给IO线程多一些,还是消费者线程多一些的问题。
# 总结
在开发过程中,遇到了诸多问题,远不止上面调个线程数那么简单,对很多数据结构、包传输、并发、和客户端的连接处理很多地方都出过问题,也对很多地方选型做过权衡,线上以求稳为主,稳中有性能提升是最好的。
主要的结论就是一切靠实践,任何理论、包括书上写的、博客写的,很多是靠想象,平时本地运行多久都不出问题,拿到线上,百万流量一冲击,各种奇奇怪怪的问题。有些在被冲击后,过一会能恢复服务,而有些技术就不行了,就直接瘫痪只能重启,甚至于连个异常信息都没有,就那么安安静静的停止响应了。
线上真实流量+极端暴力压测是我们在每一个微小改动后都会去做的事情,力求服务极端流量不宕机、不误判。
目前该框架已在开源中国发布开源,https://gitee.com/jd-platform-opensource/hotkey,有相关热key痛点需求的可以了解一下,有定制化需求,或不满足自己场景的也可以反馈,我们也在积极采纳内外部意见建议,共建优质框架。
来源:https://my.oschina.net/1Gk2fdm43/blog/4533994