
送书|为避免尬聊,我竟爬取了一千多张斗图
大家好,我是啃书君。
前几天和女神聊天的时候实在是太尬了,因为没有足够的斗图表情包,整个聊天的气氛都带动不起来,所以抑郁不得志!
为了追到心目中的完美女神,我爬了一千多张斗图表情包,只为下一次聊天的时候,主动权都在我的手上。
考虑到有些小伙伴可能在python基础不是很好,因此,啃书君决定先帮各位补补基础知识,大佬可以直接看实战内容。本次实战内容是爬取:斗图吧。
面向对象
python从设计开始就是一门面向对象的的语言,因此使用python创建一个类与对象是非常简单的一件事情。
如果你以前没有接触过面向对象的编程语言,那么你需要了解一些面向对象语言的一些基本特征,接下来就来感受python的面向对象语言。
面向对象简介
类(Class):用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
类变量:类变量在整个实例化的对象中是公共的。类变量定义在类中,且在函数体外。
数据成员:类变量或实例变量,用于处理类及其实例对象的相关数据。
方法重载:如果从父类继承的方法,无法满足子类的需求,可以对其进行改写,这个过程叫做覆盖,也称为方法的重载。
实例变量:定义在方法中的变量,只作用于当前实例的类。
继承:即一个派生类,继承基类(父类)的字段与方法。
实例化:创建一个实例,类的具体对象。
方法:类中定义的函数
对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
创建类与对象
类相当于一个模板,模板里面可以有多个函数,函数用于实现功能。
对象其实是根据模板创建的一个实例,通过创建的实例可以执行类中的函数。
# 创建类
class Foo(object):
# 创建类中的函数
def bar(self):
# todo
pass
# 根据Foo类创建对象obj
obj = Foo()
class是关键字,代表类
object代码父类,所有类都继承object类
创建对象,类名称后加上括号即可
面向对象的三大特性
封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
将内容封装到某处
从某处调用被封装的内容
class Foo(object):
# 构造方法,根据类创建对象时自动执行
def __init__(self, name, age):
self.name = name
self.age = age
# 根据类Foo创建对象
# 自动启动Foo类的__init__方法
obj1 = Foo('Jack', 18)
obj2 = Fo('Rose', 20)
obj1 = Foo('Jack', 18) 将Jack和18分别封装到obj1(self)的name和age属性中,obj2也是同样的道理。
self是一个形式参数,当执行obj1 = Foo('Jack', 18) ,self等于obj1,因此,每个对象都有name和age属性。
通过对象调用封装内容
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
obj1 = Foo('Jack', 18)
print(obj1.name) # 调用obj1的name属性
print(obj1.age) # 调用obj1的age属性
obj2 = Foo('Jack', 18)
print(obj2.name) # 调用obj2的name属性
print(obj2.age) # 调用obj2的age属性
通过self间接调用封装的内容
class Foo(object):
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print(self.name)
print(self.age)
obj1 = Foo('Jack', 18)
obj1.detail()
obj2 = Foo('Rose', 20)
obj2.detail()
obj1.detail() python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的self=obj1,即self.name相当于obj1.name。
感受面向对象的简便
对于面向对象封装来说,其实就是使用构造方法将内容封装到对象中,然后通过对象直接或者self间接获取封装内容。
接下来,我们就来体验一下面向对象的简便性。
def kanchai(name, age, gender):
print "%s,%s岁,%s,上山去砍柴" %(name, age, gender)
def qudongbei(name, age, gender):
print "%s,%s岁,%s,开车去东北" %(name, age, gender)
def dabaojian(name, age, gender):
print "%s,%s岁,%s,最爱大保健" %(name, age, gender)
kanchai('小明', 10, '男')
qudongbei('小明', 10, '男')
dabaojian('小明', 10, '男')
kanchai('老李', 90, '男')
qudongbei('老李', 90, '男')
dabaojian('老李', 90, '男')
函数式编程
class Foo(object):
def __init__(self, name, age ,gender):
self.name = name
self.age = age
self.gender = gender
def kanchai(self):
print "%s,%s岁,%s,上山去砍柴" %(self.name, self.age, self.gender)
def qudongbei(self):
print "%s,%s岁,%s,开车去东北" %(self.name, self.age, self.gender)
def dabaojian(self):
print "%s,%s岁,%s,最爱大保健" %(self.name, self.age, self.gender)
xiaoming = Foo('小明', 10, '男')
xiaoming.kanchai()
xiaoming.qudongbei()
xiaoming.dabaojian()
laoli = Foo('老李', 90, '男')
laoli.kanchai()
laoli.qudongbei()
laoli.dabaojian()
如果使用函数式编程,需要在每一个执行函数的时候都要传入相同的参数,如果参数多的话,就每一次都要复制粘贴,非常不方便;而对于面向对象来说,只需要在创建对象时,将所需要的参数封装到对象中,然后通过对象调用即可获取封装的内容。
继承
继承就是让类和类之间存在父子关系,子类可以直接访问父类的静态属性与方法。在python中,新建的类可以继承一个或多个父类,父类可以称为基类或超类,新建的类称为派生类或子类。
class ParentClass1: #定义父类1
pass
class ParentClass2: #定义父类2
pass
class SubClass1(ParentClass1):
# 单继承,基类是ParentClass1,派生类是SubClass
pass
class SubClass2(ParentClass1,ParentClass2):
# python支持多继承,用逗号分隔开多个继承的类
pass
print(SubClass1.__bases__) # 查看所有继承的父类
print(SubClass2.__bases__)
# ===============
# (<class '__main__.Father1'>,)
# (<class '__main__.Father1'>, <class '__main__.Father2'>)
继承的规则
1、子类继承父类的成员变量与方法
2、子类不继承父类的构造方法
3、子类不能删除父类成员,但是可以重新定义父类成员
4、子类可以增加自己的成员。
具体代码,如下所示:
class Person(object):
def __init__(self, name, age, sex):
self.name = 'jasn'
self.age = 18
self.sex = sex
def talk(self):
print('I want to say someting to you')
class Chinese(Person):
def __init__(self, name, age, sex, language):
Person.__init__(self, name, age, sex) # 用父类的name, age, sex覆盖掉子类的属性
self.age = age # 覆盖掉父类的age属性,取值为子类实例传入的age参数
self.language = 'Chinese'
def talk(self):
print('我说的是普通话')
Person.talk(self)
obj = Chinese('nancy', 30, 'male', '普通话')
print(obj.name)
print(obj.age)
print(obj.language)
obj.talk()
运行结果,如下:
jasn
30
Chinese
我说的是普通话
I want to say someting to you
因为,Chinese类覆盖了Person类,在开始的时候,我们将父类的属性覆盖了子类的属性,比如说name属性,子类没有去覆盖父类,因此,即使子类传来了name属性值,但依旧还是输出父类的name属性。
继承的作用
1、实现代码(功能)重用,降低代码冗余
2、增强软件的可扩充性
3、提高软件的维护性
继承与抽象的概念
面向对象的两个重要概念:抽象与分类。
class animal(): # 定义父类
country = 'china' # 这个叫类的变量
def __init__(self,name,age):
self.name = name # 这些又叫数据属性
self.age = age
def walk(self): # 类的函数,方法,动态属性
print('%s is walking'%self.name)
def say(self):
pass
class people(animal): # 子类继承父类
pass
class pig(animal): # 子类继承父类
pass
class dog(animal): # 子类继承父类
pass
aobama=people('aobama',60) # 实例化一个对象
print(aobama.name)
aobama.walk()
上面的代码可以这样理解:我们将人、狗、猪抽象为动物,人、狗、猪都继承动物类。
python中super()的作用和原理
super()在类的继承里面非常常用,它解决了子类调用父类方法的一些问题。下面我们来看一下,它优化了什么问题。
class Foo(object):
def bar(self, message):
print(message)
obj1 = Foo()
obj1.bar('hello')
当存在继承关系的时候,有时候需要在子类中调用父类方法,此时最简单的方法就是把对象调用转换成类调用,需要注意的是这时self参数需要显示传递。
具体代码,如下所示:
class FooParent(object):
"""docstring for FooParent"""
def bar(self, message):
print(message)
class FooChild(FooParent):
"""docstring for FooChild"""
def bar(self, message):
FooParent.bar(self, message)
foochild = FooChild()
foochild.bar('hello')
这样的继承方式其实是存在缺陷的,比如说,我修改了父类的名称,那么子类中将要涉及多处修改。
因此python就引入了super()机制,具体代码如下所示:
class FooParent(object):
def bar(self, message):
print(message)
class FooChild(FooParent):
def bar(self, message):
super(FooChild, self).bar(message)
obj = FooChild()
obj.bar('hello')
多态
关于python多态的知识,因本次实战内容中并没有使用到,因此我就不再叙述了,小伙伴们可以自行查找资料去了解。
什么是生产者与消费者模式
比如有两个进程A与B,它们共享一个固定大小的缓冲区,A进程生产数据放入缓冲区;B进程从缓冲区取出数据进行计算,那么这里的A进程就相当于生产者,B进程相当于消费者。
为什么要使用生产者与消费者模式
在进程的世界里,生产者就是生产数据的进程,消费者就是使用(处理)数据的进程。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。同样的道理,如果生产者的处理能力大于消费者能力,那么生产者就必须等待消费者。
实现了生产者与消费者的解耦和,平衡了生产力与消费力,因为二者不能直接沟通,而是通过队列进行沟通。
生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。
生产者与消费者不直接通信,而是通过阻塞队列进行通信,因此,生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是去阻塞队列中找数据。阻塞队列就类似于缓冲区,平衡了生产者与消费者的能力。
multiprocess-Queue实现
具体代码,如下所示:
from multiprocessing import Process, Queue
import time, random
from threading import Thread
import queue
# 生产者
def producer(name, food, q):
for i in range(4):
time.sleep(random.randint(1, 3)) # 模拟产生数据的时间
f = '%s 生产了 %s %s个' % (name, food, i + 1)
print(f)
q.put(f)
# 消费者
def consumer(name, q):
while True:
food = q.get()
if food is None:
print('%s 获取到一个空' % name)
break
f = '%s 消费了 %s' % (name, food)
print(f)
time.sleep(random.randint(1, 3))
if __name__ == '__main__':
q = Queue() # 创建队列
# 模拟生产者,产生数据
p1 = Process(target=producer, args=('p1', '包子', q))
p1.start()
p2 = Process(target=producer, args=('p2', '烧饼', q))
p2.start()
c1 = Process(target=consumer, args=('c1', q))
c1.start()
c2 = Process(target=consumer, args=('c2', q))
c2.start()
p1.join()
p2.join()
q.put(None)
q.put(None)
Thread-Queue实现
上面的代码是由多进程实现的,接下来就考虑一下多线程实现该功能。
具体代码,如下所示:
import random
import time
from threading import Thread
import queue
def producer(name, count, q):
for i in range(count):
food = f'{name} 生产第{i}个包子'
print(food)
q.put(food)
def consumer(name, q):
while True:
time.sleep(random.randint(1, 3))
if q.empty():
break
print(f'{name} 消费了 {q.get()}')
if __name__ == '__main__':
q = queue.Queue()
print(q.empty())
for i in range(1, 4):
p = Thread(target=producer, args=(f'生产者{i}', 10, q))
p.start()
for i in range(1, 6):
c = Thread(target=consumer, args=(f'消费者{i}', q))
c.start()
生产者消费者模式特点
保证生产者不会在缓冲区满的时候继续向缓冲区放入数据,而消费者也不会在缓冲区空的时候,消耗数据。
当缓冲区满的时候,生产者会进入休眠状态,当下次消费者开始消耗缓冲区数据时,生产者才会被唤醒,开始往缓冲区添加数据;当缓冲区空的时候,消费者会进入休眠状态,直到生产者往缓冲区添加数据时才会被唤醒。
基础知识总结
到这里,我基本上就将本次实战需要用到的基础知识都教给大家了,相当于抛砖引玉。抛出我这块砖,引出小伙伴们的玉。本次的基础知识主要分为两大模块,第一个是面向对象的知识,第二个则是线程相关的知识,小伙伴们需要尽可能去熟悉,才能写出更加高效健壮的爬虫demo。
实战篇
工具库使用
本次爬虫所需要的工具库我先列举出来
import requests
from lxml import etree
import threading
from queue import Queue
import re
缺少哪些就自行安装。
抓取目标
本次实战所要抓取的网站是斗图吧。网址如下:
https://www.doutub.com/
我们需要抓取的内容是该网站下的斗图表情包。
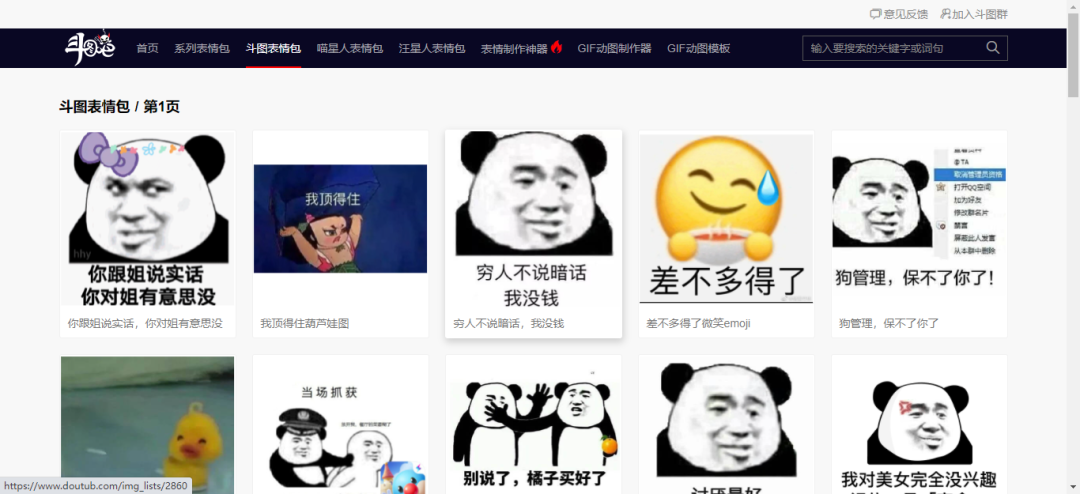
瞬间让你成为斗图高手。啥也别说了,干就完事。
网页分析
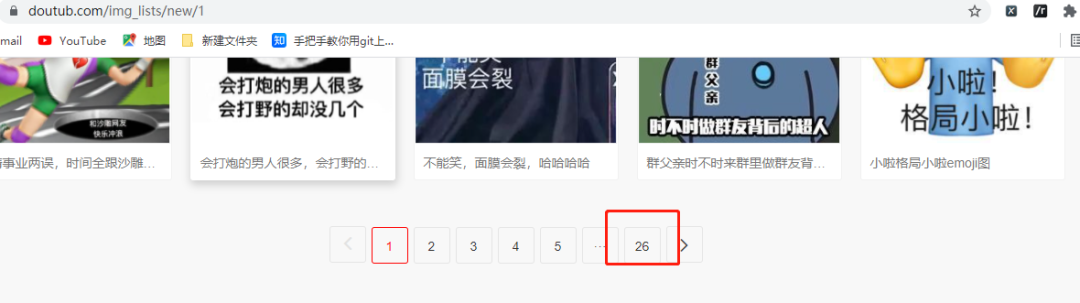
定睛一看,好家伙,居然有26页的表情包,这不起飞?
首先来分析一下不同页面url的地址变化。
# 第一页
https://www.doutub.com/img_lists/new/1
# 第二页
https://www.doutub.com/img_lists/new/2
# 第三页
https://www.doutub.com/img_lists/new/3
看到这种变化的方式之后难道你不先窃喜一下。
页面url地址已经搞定,那接下来要弄清楚的就是每一张表情包的url地址了。
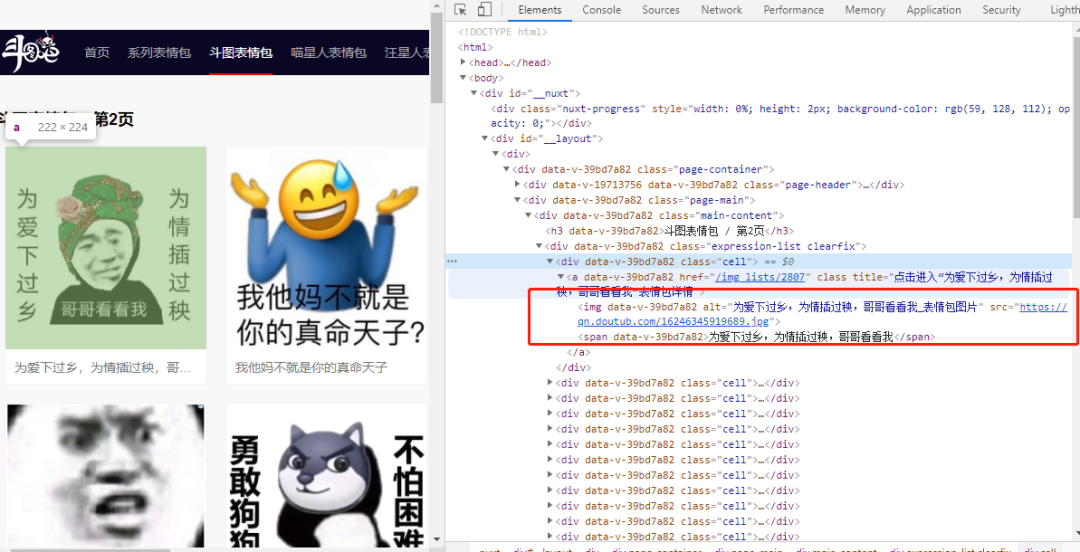
image-20210701200206882
这不是很容易就被聪明的你发现了吗?这些链接我们采用xpath将其提取出来即可。
生产者的实现
首先,我们先创建两个队列,一个用于存储每一页的url地址,另一个便用于存储图片链接。
具体代码,如下所示:
# 建立队列
page_queue = Queue() # 页面url
img_queue = Queue() # 图片url
for page in range(1, 27):
url = f'https://www.doutub.com/img_lists/new/{page}'
page_queue.put(url)
通过上面的代码,便将每一页的url地址放入了page_queue。
接下来再通过创建一个类,将图片url放入img_queue中。
具体代码如下所示:
class ImageParse(threading.Thread):
def __init__(self, page_queue, img_queue):
super(ImageParse, self).__init__()
self.page_queue = page_queue
self.img_queue = img_queue
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
def run(self):
while True:
if self.page_queue.empty():
break
url = self.page_queue.get()
self.parse_img(url)
def parse_img(self, url):
response = requests.get(url, headers=self.headers).content.decode('utf-8')
html = etree.HTML(response)
img_lists = html.xpath('//div[@class="expression-list clearfix"]')
for img_list in img_lists:
img_urls = img_list.xpath('./div/a/img/@src')
img_names = img_list.xpath('./div/a/span/text()')
for img_url, img_name in zip(img_urls, img_names):
self.img_queue.put((img_url, img_name))
消费者的实现
其实消费者很简单,我们只需要不断的从img_page中获取到图片的url链接并不停的进行访问即可。直到两个队列中有一个队列为空即可退出。
class DownLoad(threading.Thread):
def __init__(self, page_queue, img_queue):
super(DownLoad, self).__init__()
self.page_queue = page_queue
self.img_queue = img_queue
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
}
def run(self):
while True:
if self.page_queue.empty() and self.img_queue.empty():
break
img_url, filename = self.img_queue.get()
fix = img_url.split('.')[-1]
name = re.sub(r'[??.,。!!*\\/|]', '', filename)
# print(fix)
data = requests.get(img_url, headers=self.headers).content
print('正在下载' + filename)
with open('../image/' + name + '.' + fix, 'wb') as f:
f.write(data)
最后,再让创建好的两个线程跑起来
for x in range(5):
t1 = ImageParse(page_queue, img_queue)
t1.start()
t2 = DownLoad(page_queue, img_queue)
t2.start()
t1.join()
t2.join()
最后结果
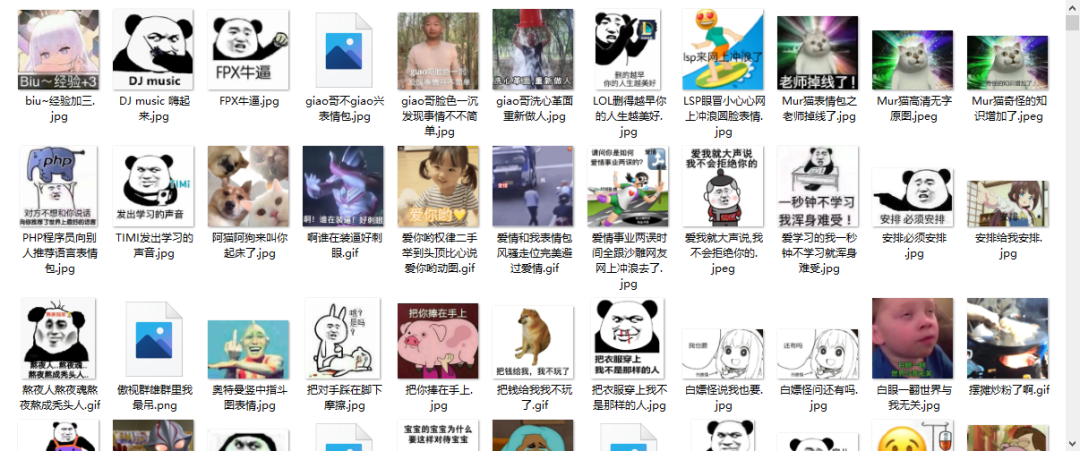
一共抓取了1269张图片。
从今往后谁还能比得上你?就这?这不有爬虫就行!
送书
又到了每周三的送书时刻,今天给大家带来的是《Python量化金融编程从入门到精通》,本书先从量化交易的基本概念讲起,然后讲解Python的基本语法及常见库的使用,在每章节的学习中都以金融量化为实例,并在后结合实战项目来进行学习和巩固,读者不但可以系统地学习Python编程的相关知识,而且还能学习到Python在量化交易场景下的应用。
本书内容通俗易懂,案例丰富,适合零基础并对Python量化感兴趣的读者,以及想学习量化交易实战项目的Python初学者。此外,本书也适合作为相关培训机构的培训教材。

公众号回复:送书 ,参与抽奖(共5本)
点击下方回复:送书 即可!
大家如果有什么建议,欢迎扫一扫二维码私聊小编~
回复:加群 可加入Python技术交流群