
为妹子打抱不平,我深夜爬取了严选的男性内裤数据,结果……

文 | 闲欢
来源:Python 技术「ID: pythonall」

上一篇文章通过爬取网易严选的评论数据来探究妹子们的内衣尺码、颜色偏好以及对内衣的评价,通过大家的反响发现好像无意中得罪了某类群体,又满足了某类群体的某种特殊癖好。作为无意的举动,作者深感愧疚。为了为妹子打抱不平,工作加班到深夜之后,我毅然牺牲睡觉时间,来爬取网易的男性内裤数据,看看有什么发现。
爬取数据
首先,我们在网易严选的搜索框输入关键词“男士内裤”,页面搜索出来男士内裤的产品列表界面:
我们点开第一个商品,点击“评论”,就可以看到如下信息:
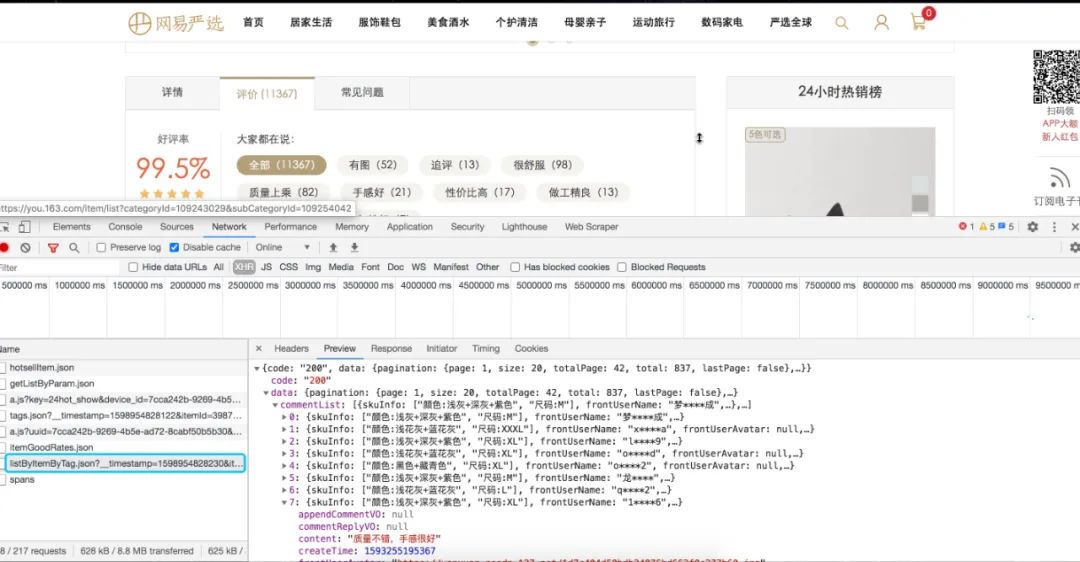
我们分析请求列表,就可以很容易地发现评论数据是通过 https://you.163.com/xhr/comment/listByItemByTag.json 这个请求来获取的。然后我们过滤请求参数,去掉不是必传的参数,最终发现 itemId 和 page 两个参数是必须的。
itemId 是指商品的ID,page 就是指的请求的页码,默认每页记录数是40。所以我们要获取评论数据的前提是获取到对应的商品ID。
我们是从搜索页面点击产品进入商品详情页的,所以搜索页面的商品列表里面肯定存在每一个商品的商品ID,我们回到搜索产品列表页,寻找搜索商品的请求:
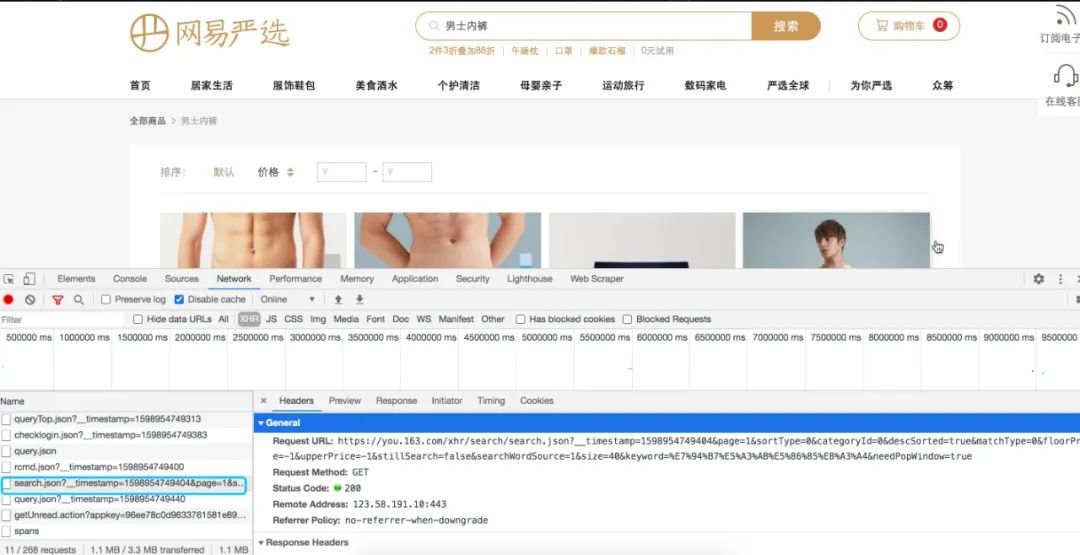
同样的,我们在搜索界面的请求分析中,找到了 http://you.163.com/xhr/search/search.json 这个请求,逐个分析请求参数后发现,我们只需要 keyword 和 page 两个参数即可。
请求分析完成后,我们就可以来码代码了。代码如下:
# 获取商品列表def search_keyword(keyword):uri = 'https://you.163.com/xhr/search/search.json'query = {"keyword": keyword,"page": 1}try:res = requests.get(uri, params=query).json()result = res['data']['directly']['searcherResult']['result']product_id = []for r in result:product_id.append(r['id'])return product_idexcept:raise# 获取评论def details(product_id):url = 'https://you.163.com/xhr/comment/listByItemByTag.json'try:C_list = []for i in range(1, 100):query = {"itemId": product_id,"page": i,}res = requests.get(url, params=query).json()if not res['data']['commentList']:breakprint("爬取第 %s 页评论" % i)commentList = res['data']['commentList']C_list.extend(commentList)time.sleep(1)return C_listexcept:raiseproduct_id = search_keyword('男士内裤')r_list = []for p in product_id:r_list.extend(details(p))with open('./briefs.txt', 'w') as f:for r in r_list:try:f.write(json.dumps(r, ensure_ascii=False) + '\n')except:print('出错啦')
为了简单起见,我抓取了首页的40件商品的评论数,将结果保存在 briefs.txt 文件中。文件数据的预览如下:

分析数据
抓取完数据后,我们就可以进入探索环节了,我想从颜色、尺码、评论三个角度分析数据,看看男士们内裤的一些“特点”。
我们来看看数据结构的特点:
{"skuInfo": ["颜色:黑色","尺码:M"],"frontUserName": "S****、","frontUserAvatar": "https://yanxuan.nosdn.127.net/0da37937c896cac1955bda8522d5754f.jpg","content": "非常好","createTime": 1592965119969,"picList": [],"commentReplyVO": null,"memberLevel": 5,"appendCommentVO": null,"star": 5,"itemId": 3544005}
仔细观察这条评论数据,我们可以看到颜色和尺码都放在 skuInfo 这个数组里面,评论是放在 content 字段里面。同时,我们多翻一些数据就可以发现,颜色有好几种格式:
单条装的颜色,例如:颜色:浅麻灰 多条装的颜色,例如:颜色:(黑色+麻灰+浅麻灰)3条 自选多条的颜色,例如:颜色:黑色+藏青色 其他,例如:规格:5条装
这里,最后一种无法分辨出颜色,我准备过滤掉。其他几种,去除掉干扰,通过“+”就可以拆分出颜色来。
而尺码数据格式是统一的,可以直接获取。
我将颜色和尺码都做成柱状图来展示,而评论就用词云来展示。最终的效果图如下:
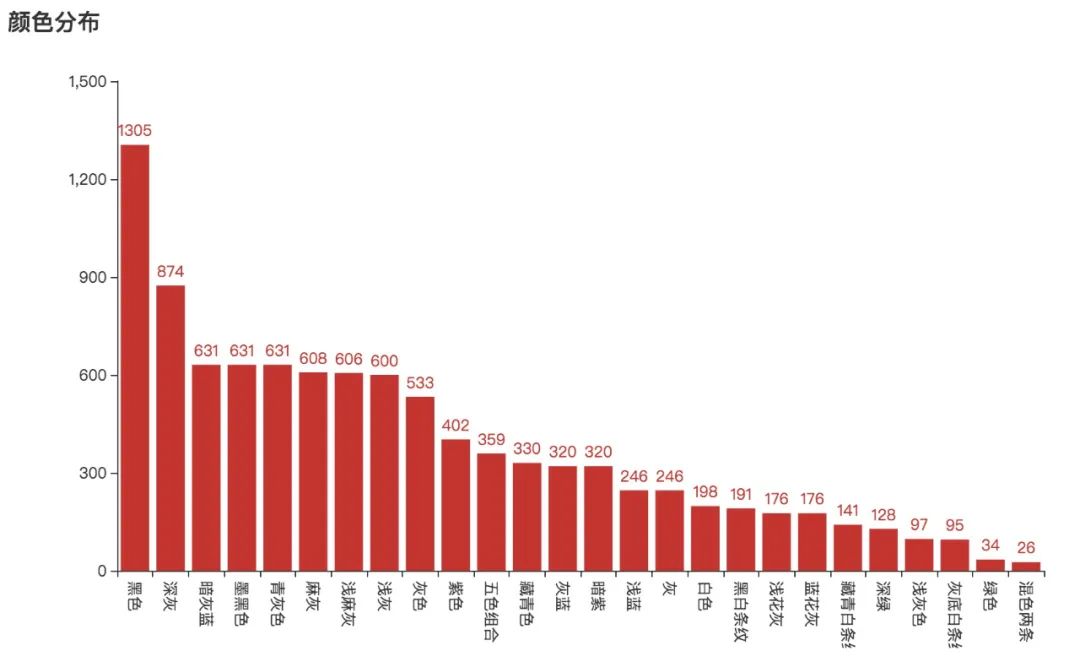
颜色并没有出乎我的意料,黑色遥遥领先,不过,如果把几种灰色加起来的话,可能超过了黑色。总之,黑色和灰色是大众的选择。
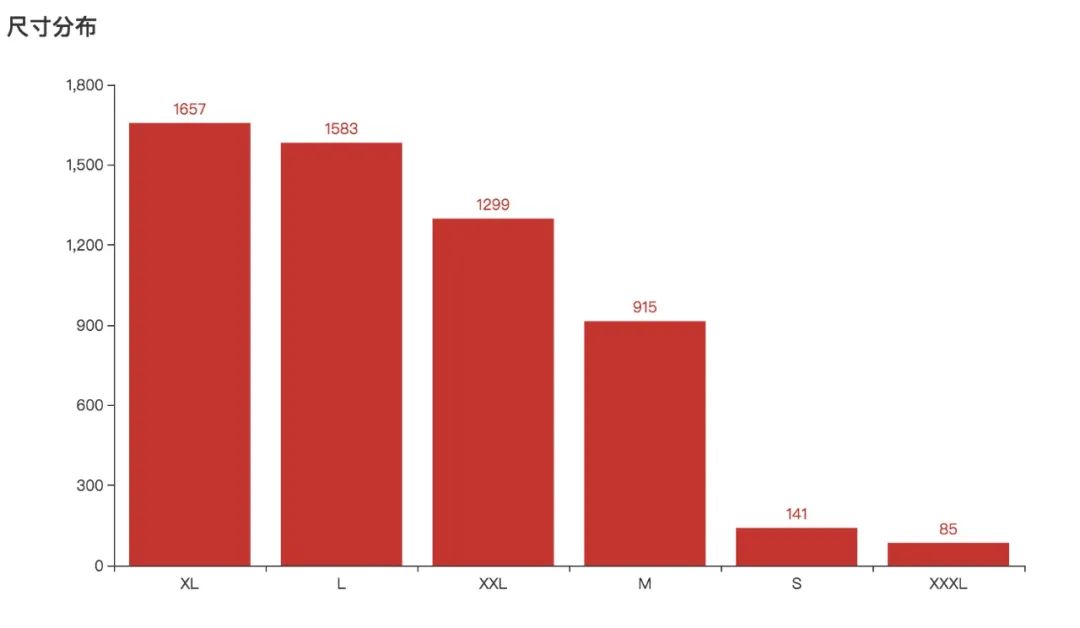
尺寸嘛,前三名是XL、L和XXL,不过XL和L相差不大。

从评论可以看出,不论是男性还是女性,对于内衣的选择,舒适度永远是第一的,质量其次。想想也是的,质量再好,穿着不舒服,是有点淡淡的忧伤~
总结
网易严选的受众群体是35岁以下的青年人,这个数据分析的结果也可以反应这个年龄群体的普遍选择。所以,广大男青年们,在你们嘲笑女性尺码多数是13的同时,不要忘了人还没到中年,腰包没鼓起来,腰带已经鼓起来了。多运动多注重身体管理吧!
PS:公号内回复「Python」即可进入Python 新手学习交流群,一起 100 天计划!
老规矩,兄弟们还记得么,右下角的 “在看” 点一下,如果感觉文章内容不错的话,记得分享朋友圈让更多的人知道!


【代码获取方式】