
【机器学习】一文深层解决模型过拟合
一、过拟合的本质及现象
过拟合是指模型只过分地匹配特定训练数据集,以至于对训练集外数据无良好地拟合及预测。其本质原因是模型从训练数据中学习到了一些统计噪声,即这部分信息仅是局部数据的统计规律,该信息没有代表性,在训练集上虽然效果很好,但未知的数据集(测试集)并不适用。
1.1 评估拟合效果
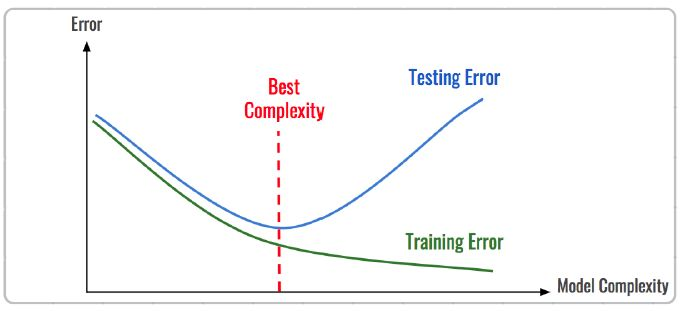 通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
通常由训练误差及测试误差(泛化误差)评估模型的学习程度及泛化能力。
欠拟合时训练误差和测试误差在均较高,随着训练时间及模型复杂度的增加而下降。在到达一个拟合最优的临界点之后,训练误差下降,测试误差上升,这个时候就进入了过拟合区域。它们的误差情况差异如下表所示: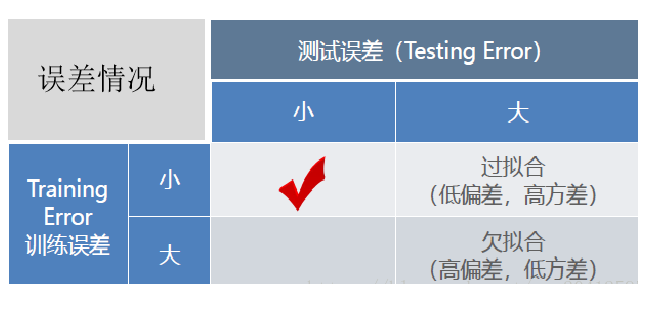
1.2 拟合效果的深入分析
对于拟合效果除了通过训练、测试的误差估计其泛化误差及判断拟合程度之外,我们往往还希望了解它为什么具有这样的泛化性能。统计学常用“偏差-方差分解”(bias-variance decomposition)来分析模型的泛化性能:泛化误差为偏差+方差+噪声之和。
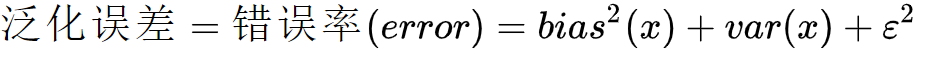
噪声(ε) 表达了在当前任务上任何学习算法所能达到的泛化误差的下界,即刻画了学习问题本身(客观存在)的难度。
偏差(bias) 是指用所有可能的训练数据集训练出的所有模型的输出值与真实值之间的差异,刻画了模型的拟合能力。偏差较小即模型预测准确度越高,表示模型拟合程度越高。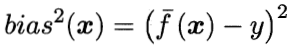
方差(variance) 是指不同的训练数据集训练出的模型对同预测样本输出值之间的差异,刻画了训练数据扰动所造成的影响。方差较大即模型预测值越不稳定,表示模型(过)拟合程度越高,受训练集扰动影响越大。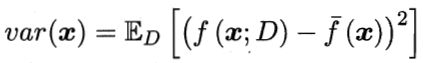 如下用靶心图形象表示不同方差及偏差下模型预测的差异:
如下用靶心图形象表示不同方差及偏差下模型预测的差异:
偏差越小,模型预测值与目标值差异越小,预测值越准确;
方差越小,不同的训练数据集训练出的模型对同预测样本预测值差异越小,预测值越集中;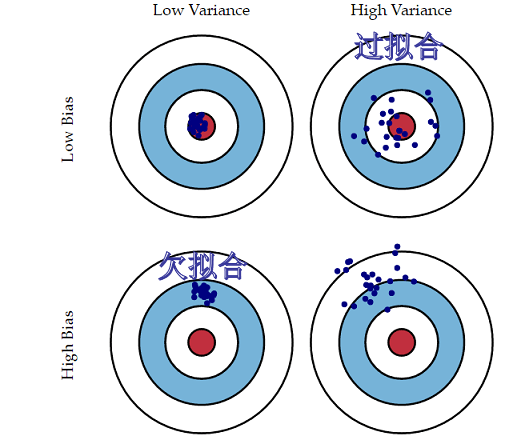
“偏差-方差分解” 说明,模型拟合过程的泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。
当模型欠拟合时:模型准确度不高(高偏差),受训练数据的扰动影响较小(低方差),其泛化误差大主要由高的偏差导致。
当模型过拟合时:模型准确度较高(低偏差),模型容易学习到训练数据扰动的噪音(高方差),其泛化误差大由高的方差导致。
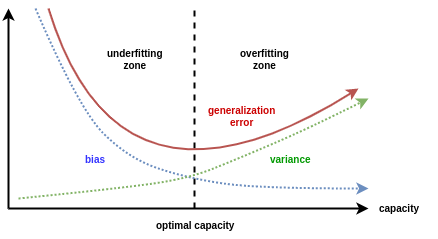 实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点。
实践中通常欠拟合不是问题,可以通过使用强特征及较复杂的模型提高学习的准确度。而解决过拟合,即如何减少泛化误差,提高泛化能力,通常才是优化模型效果的重点。
二、如何解决过拟合
2.1 解决思路
上文说到学习统计噪声是过拟合的本质原因,而模型学习是以经验损失最小化,现实中学习的训练数据难免有统计噪音的。一个简单的思路,通过提高数据量数量或者质量解决统计噪音的影响:
通过足够的数据量就可以有效区分哪些信息是片面的,然而现实情况数据通常都很有限的。
通过提高数据的质量,可以结合先验知识加工特征以及对数据中噪声进行剔除(噪声如训练集有个“用户编号尾数是否为9”的特征下,偶然有正样本的占比很高的现象,而凭业务知识理解这个特征是没有意义的噪声,就可以考虑剔除)。但这样,一来过于依赖人工,人工智障?二来先验领域知识过多的引入,如果领域知识有误,不也是噪声。
当数据层面的优化有限,接下来登场主流的方法——正则化策略。
在以(可能)增加经验损失为代价,以降低泛化误差为目的,解决过拟合,提高模型泛化能力的方法,统称为正则化策略。
2.2 常见的正则化策略及原理
本节尝试以不一样的角度去理解正则化策略,欢迎留言交流。
正则化策略经常解读为对模型结构风险的惩罚,崇尚简单模型。并不尽然!如前文所讲学到统计噪声是过拟合的本质原因,所以模型复杂度容易引起过拟合(只是影响因素)。然而工程中,对于困难的任务需要足够复杂的模型,这种情况缩减模型复杂度不就和“减智商”一样?所以,通常足够复杂且有正则化的模型才是我们追求的,且正则化不是只有减少模型容量这方式。
机器学习是从训练集经验损失最小化为学习目标,而学习的训练集里面不可避免有统计噪声。除了提高数据质量和数量方法,我们不也可以在模型学习的过程中,给一些指导性的先验假设(即根据一些已知的知识对参数的分布进行一定的假设),帮助模型更好避开一些“噪声”的信息并关注到本质特征,更好地学习模型结构及参数。这些指导性的先验假设,也就是正则化策略,常见的正则化策略如下:
L2 正则化
L2 参数正则化 (也称为岭回归、Tikhonov 正则) 通常被称为权重衰减 (weight decay),是通过向⽬标函数添加⼀个正则项 Ω(θ) ,使权重更加接近原点,模型更为简单(容器更小)。从贝叶斯角度,L2的约束项可以视为模型参数引入先验的高斯分布(参见Bob Carpenter的 Lazy Sparse Stochastic Gradient Descent for Regularized )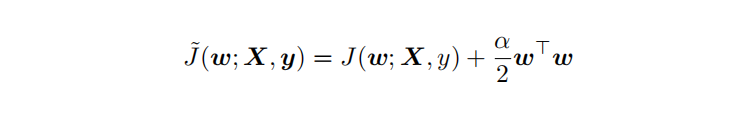 对带L2目标函数的模型参数更新权重,ϵ学习率:
对带L2目标函数的模型参数更新权重,ϵ学习率: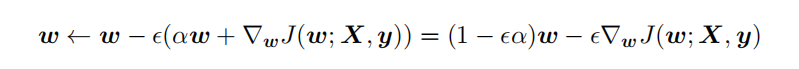
从上式可以看出,加⼊权重衰减后会导致学习规则的修改,即在每步执⾏梯度更新前先收缩权重 (乘以 1 − ϵα ),有权重衰减的效果,但是w比较不容易为0。
L1 正则化
L1 正则化(Lasso回归)是通过向⽬标函数添加⼀个参数惩罚项 Ω(θ),为各个参数的绝对值之和。从贝叶斯角度,L1的约束项也可以视为模型参数引入拉普拉斯分布。
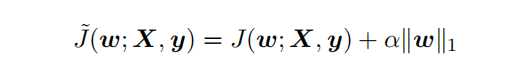
对带L1目标函数的模型参数更新权重(其中 sgn(x) 为符号函数,取参数的正负号):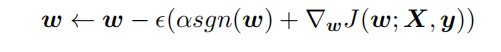 可见,在-αsgn(w)项的作用下, w各元素每步更新后的权重向量都会平稳地向0靠拢,w的部分元素容易为0,造成稀疏性。模型更简单,容器更小。
可见,在-αsgn(w)项的作用下, w各元素每步更新后的权重向量都会平稳地向0靠拢,w的部分元素容易为0,造成稀疏性。模型更简单,容器更小。
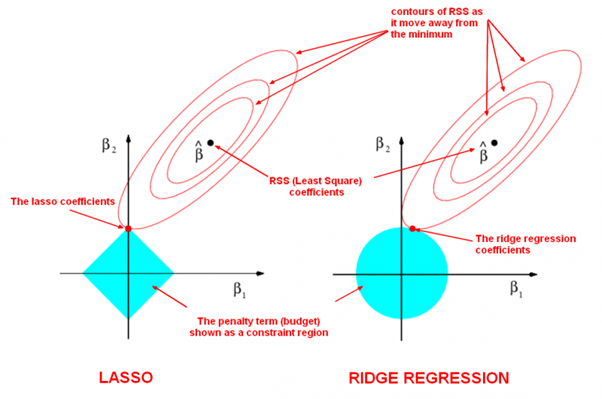
对比L1,L2,两者的有效性都体现在限制了模型的解空间w,降低了模型复杂度(容量)。L2范式约束具有产生平滑解的效果,没有稀疏解的能力,即参数并不会出现很多零。假设我们的决策结果与两个特征有关,L2正则倾向于综合两者的影响(可以看作符合bagging多释准则的先验),给影响大的特征赋予高的权重;而L1正则倾向于选择影响较大的参数,而尽可能舍弃掉影响较小的那个( 可以看作符合了“奥卡姆剃刀定律--如无必要勿增实体”的先验)。在实际应用中 L2正则表现往往会优于 L1正则,但 L1正则会压缩模型,降低计算量。
在Keras中,可以使用regularizers模块来在某个层上应用L1及L2正则化,如下代码:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l1_l2(l1=α1, l2=α2) # α为超参数惩罚系数
earlystop
earlystop(早停法)可以限制模型最小化代价函数所需的训练迭代次数,如果迭代次数太少,算法容易欠拟合(方差较小,偏差较大),而迭代次数太多,算法容易过拟合(方差较大,偏差较小),早停法通过确定迭代次数解决这个问题。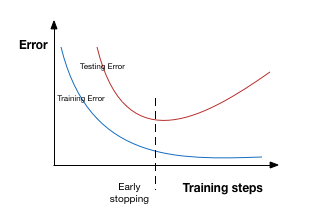 earlystop可认为是将优化过程的参数空间限制在初始参数值 θ0 的小邻域内(Bishop 1995a 和Sjöberg and Ljung 1995 ),在这角度上相当于L2正则化的作用。
earlystop可认为是将优化过程的参数空间限制在初始参数值 θ0 的小邻域内(Bishop 1995a 和Sjöberg and Ljung 1995 ),在这角度上相当于L2正则化的作用。
在Keras中,可以使用callbacks函数实现早期停止,如下代码:
from keras.callbacks import EarlyStopping
callback =EarlyStopping(monitor='loss', patience=3)
model = keras.models.Sequential([tf.keras.layers.Dense(10)])
model.compile(keras.optimizers.SGD(), loss='mse')
history = model.fit(np.arange(100).reshape(5, 20), np.zeros(5),
epochs=10, batch_size=1, callbacks=[callback],
verbose=0)
数据增强
数据增强是提升算法性能、满足深度学习模型对大量数据的需求的重要工具。数据增强通过向训练数据添加转换或扰动来增加训练数据集。数据增强技术如水平或垂直翻转图像、裁剪、色彩变换、扩展和旋转(此外还有生成模型伪造的对抗样本),通常应用在视觉表象和图像分类中,通过数据增强有助于更准确的学习到输入数据所分布的流形(manifold)。
在keras中,你可以使用ImageDataGenerator来实现上述的图像变换数据增强,如下代码:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal_flip=True)
datagen.fit(train)
引入噪声
与清洗数据的噪音相反,引入噪声也可以明显增加神经网络模型的鲁棒性(很像是以毒攻毒)。对于某些模型而言,向输入添加方差极小的噪声等价于对权重施加范数惩罚 (Bishop, 1995a,b)。常用有三种方式:
在输入层引入噪声,可以视为是一种数据增强的方法。
在模型权重引入噪声
这项技术主要用于循环神经网络 (Jim et al., 1996; Graves, 2011)。向网络权重注入噪声,其代价函数等于无噪声注入的代价函数加上一个与噪声方差成正比的参数正则化项。
在标签引入噪声
原实际标签y可能多少含有噪声,当 y 是错误的,直接使用0或1作为标签,对最大化 log p(y | x)效果变差。另外,使用softmax 函数和最大似然目标,可能永远无法真正输出预测值为 0 或 1,因此它会继续学习越来越大的权重,使预测更极端。使用标签平滑的优势是能防止模型追求具体概率又不妨碍正确分类。如标签平滑 (label smoothing) 基于 k 个输出的softmax 函数,把明确分类 0 和 1 替换成 ϵ /(k−1) 和 1 − ϵ,对模型进行正则化。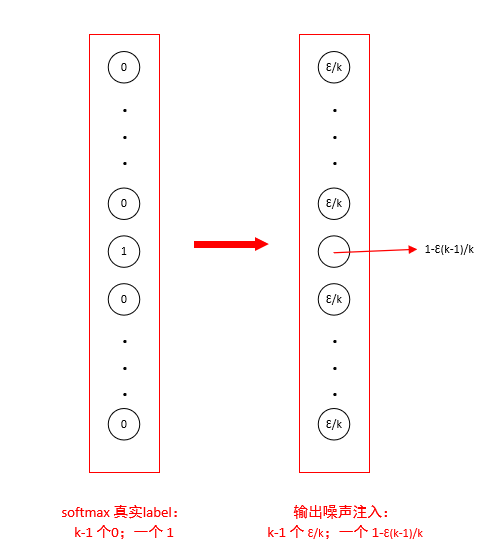
半监督学习
半监督学习思想是在标记样本数量较少的情况下,通过在模型训练中直接引入无标记样本,以充分捕捉数据整体潜在分布,以改善如传统无监督学习过程盲目性、监督学习在训练样本不足导致的学习效果不佳的问题 。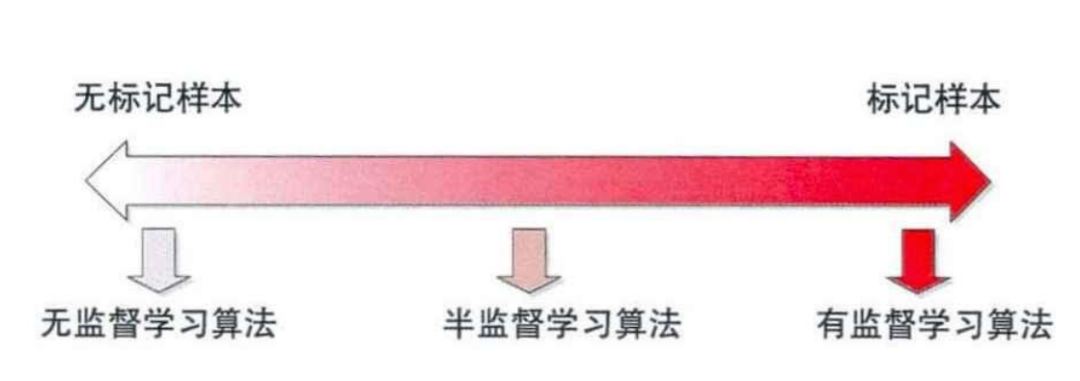 依据“流形假设——观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示”,无标签数据相当于提供了一种正则化(regularization),有助于更准确的学习到输入数据所分布的流形(manifold),而这个低维流形就是数据的本质表示。
依据“流形假设——观察到的数据实际上是由一个低维流形映射到高维空间上的。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示”,无标签数据相当于提供了一种正则化(regularization),有助于更准确的学习到输入数据所分布的流形(manifold),而这个低维流形就是数据的本质表示。
多任务学习
多任务学习(Caruana, 1993) 是通过合并几个任务中的样例(可以视为对参数施加的软约束)来提高泛化的一种方法,其引入一个先验假设:这些不同的任务中,能解释数据变化的因子是跨任务共享的。常见有两种方式:基于参数的共享及基于正则化的共享。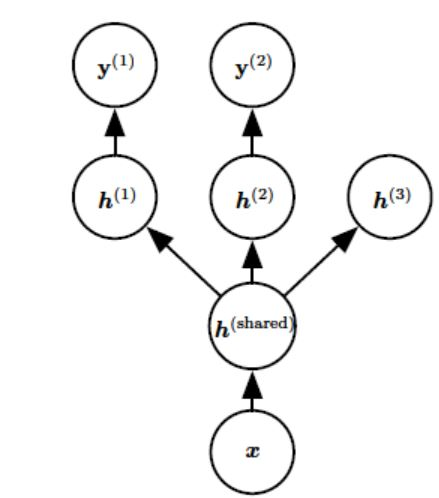
额外的训练样本以同样的方式将模型的参数推向泛化更好的方向,当模型的一部分在任务之间共享时,模型的这一部分更多地被约束为良好的值(假设共享是合理的),往往能更好地泛化。
bagging
bagging是机器学习集成学习的一种。依据多释准则,结合了多个模型(符合经验观察的假设)的决策达到更好效果。具体如类似随机森林的思路,对原始的m个训练样本进行有放回随机采样,构建t组m个样本的数据集,然后分别用这t组数据集去训练t个的DNN,最后对t个DNN模型的输出用加权平均法或者投票法决定最终输出。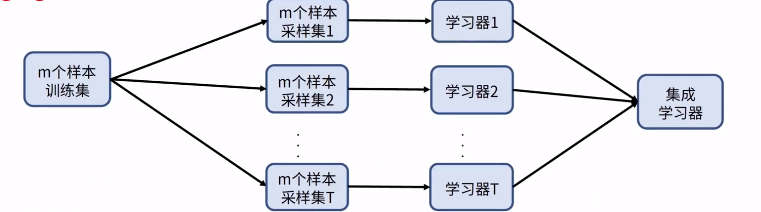
bagging 可以通过平滑效果降低了方差,并中和些噪声带来的误差,因此有更高的泛化能力。
Dropout
Dropout是正则化技术简单有趣且有效的方法,在神经网络很常用。其方法是:在每个迭代过程中,以一定概率p随机选择输入层或者隐藏层的(通常隐藏层)某些节点,并且删除其前向和后向连接(让这些节点暂时失效)。权重的更新不再依赖于有“逻辑关系”的隐藏层的神经元的共同作用,一定程度上避免了一些特征只有在特定特征下才有效果的情况,迫使网络学习更加鲁棒(指系统的健壮性)的特征,达到减小过拟合的效果。这也可以近似为机器学习中的集成bagging方法,通过bagging多样的的网络结构模型,达到更好的泛化效果。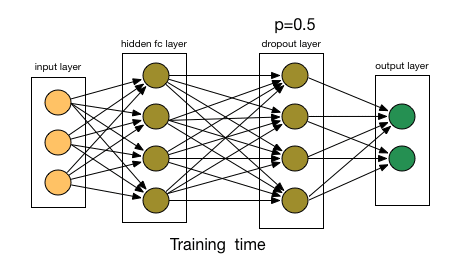 相似的还有Drop Connect ,它和 Dropout 相似的地方在于它涉及在模型结构中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。
相似的还有Drop Connect ,它和 Dropout 相似的地方在于它涉及在模型结构中引入稀疏性,不同之处在于它引入的是权重的稀疏性而不是层的输出向量的稀疏性。
在Keras中,我们可以使用Dropout层实现dropout,代码如下:
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation='relu'),
Dropout(0.25)
])
(end)
文章首发公众号“算法进阶”,更多原创文章敬请关注。
个人github博客:https://github.com/aialgorithm
往期精彩回顾 本站qq群554839127,加入微信群请扫码: