
精选| 2020年12月R新包推荐(第49期)
翻译:黄小伟,资深大数据分析从业者。目前就职杭州有赞数据分析团队!
知乎专栏:中国R语言社区 |11000+关注
知乎圈子:数据分析圈|10000+加入
2020年12月,123个R新包收录于CRAN(2020年11月份收录292个),累计收录18,010个R包!此次选摘了40个R包(九个类别),分布结构如下:
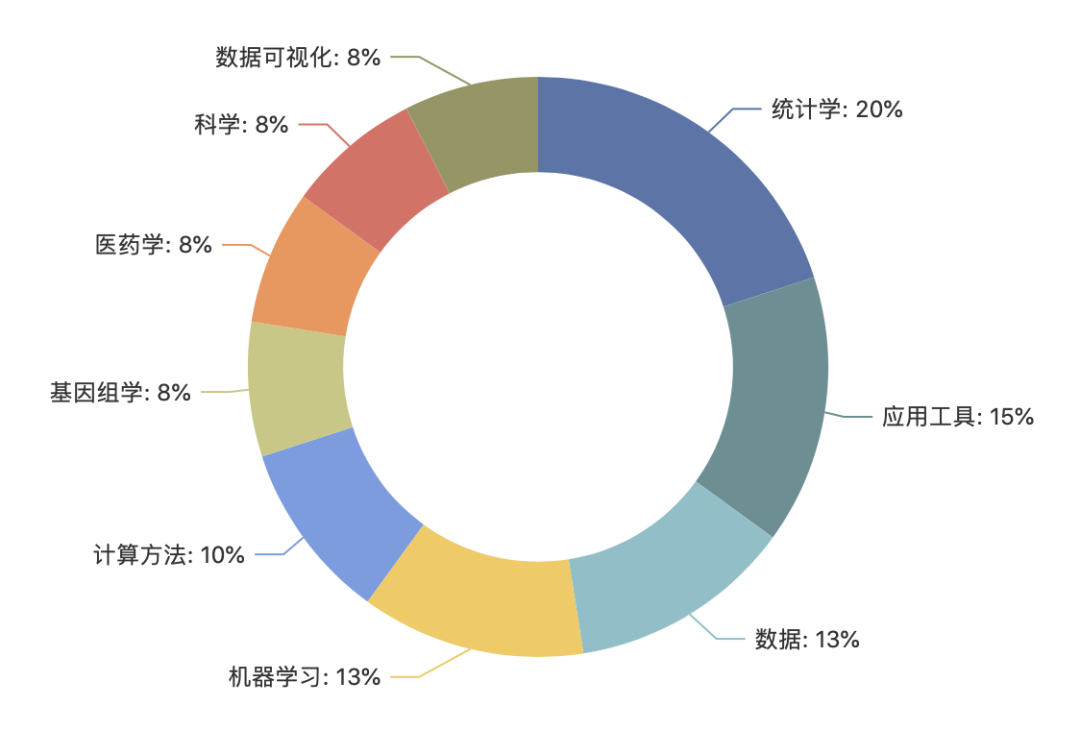
以下是本期(总第49期)R新包的核心功能介绍:
一. 计算方法
1. FKF.SP: 提供了一种快速灵活的Kalman滤波实现方法,利用序列处理,然后通过最大似然估计进行有效的参数估计.
2. rminizinc: 提供与MiniZinc的接口,它是一种免费的开源约束建模语言,当可以根据任意约束对问题进行建模时,该语言用于从大量候选对象中识别可行的解决方案.
3. nosiySBM: 实现了变分期望最大化算法,将一个噪声随机块模型拟合到一个观察到的稠密图上,并进行节点聚类.
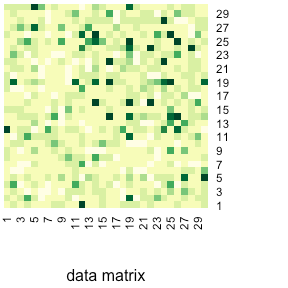
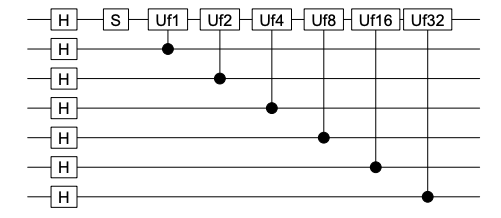
4. qsimulatR: 实现最多具有24个量子位的量子计算机模拟器,该模拟器提供许多通用门,并允许用户定义通用单个量子位门和通用受控单个量子位门。该软件包支持绘制电路并将电路导出到Qiskit,这是一个Python软件包,可用于在IBM的Quantum硬件上运行.
二. 数据
1. eyedata: 提供来自伦敦Moorfields眼科医院治疗患者的匿名真实生活开源数据集.
2. rgugik: 自动化开放数据采集,包括来自波兰大地测量和制图总部的光栅和矢量数据.
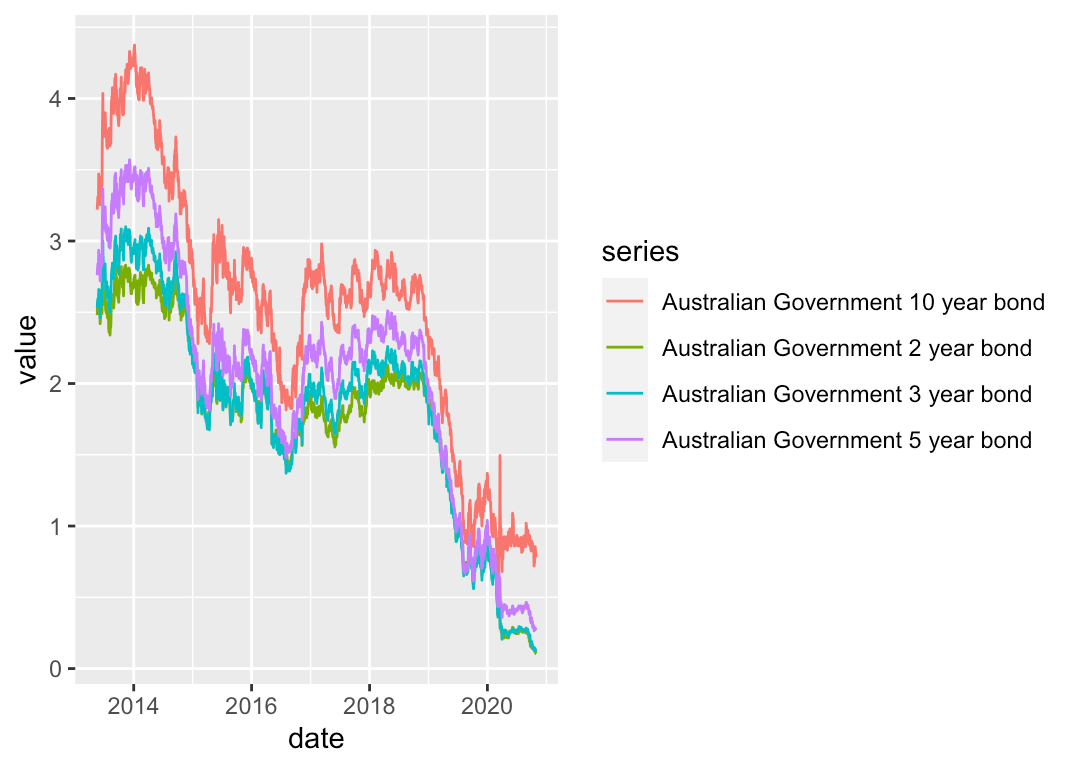
3. readrba: 提供工具从澳大利亚储备银行的数据中下载当前和历史统计表和预测,这些数据包括广泛的澳大利亚宏观经济和金融时间序列.
4. threesixtygiving: 支持对360Giving(英国慈善捐赠数据库)公开数据的访问.
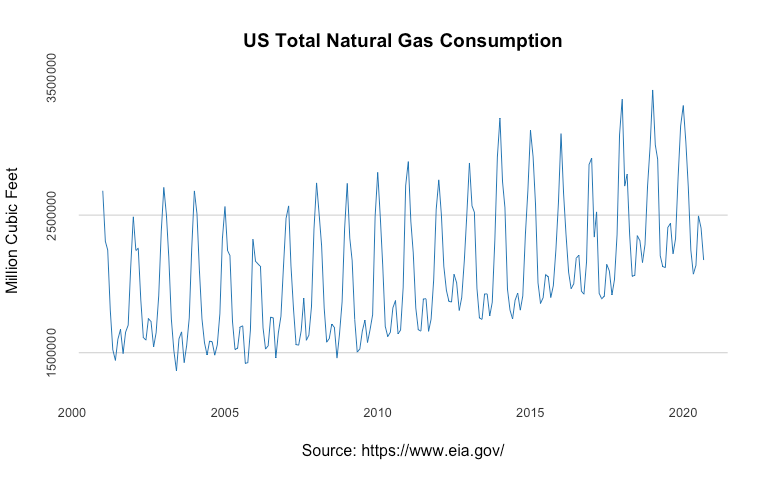
5. USgas: 支持与美国能源信息管理局的链接,提供县级天然气需求和概述.
三.基因组学
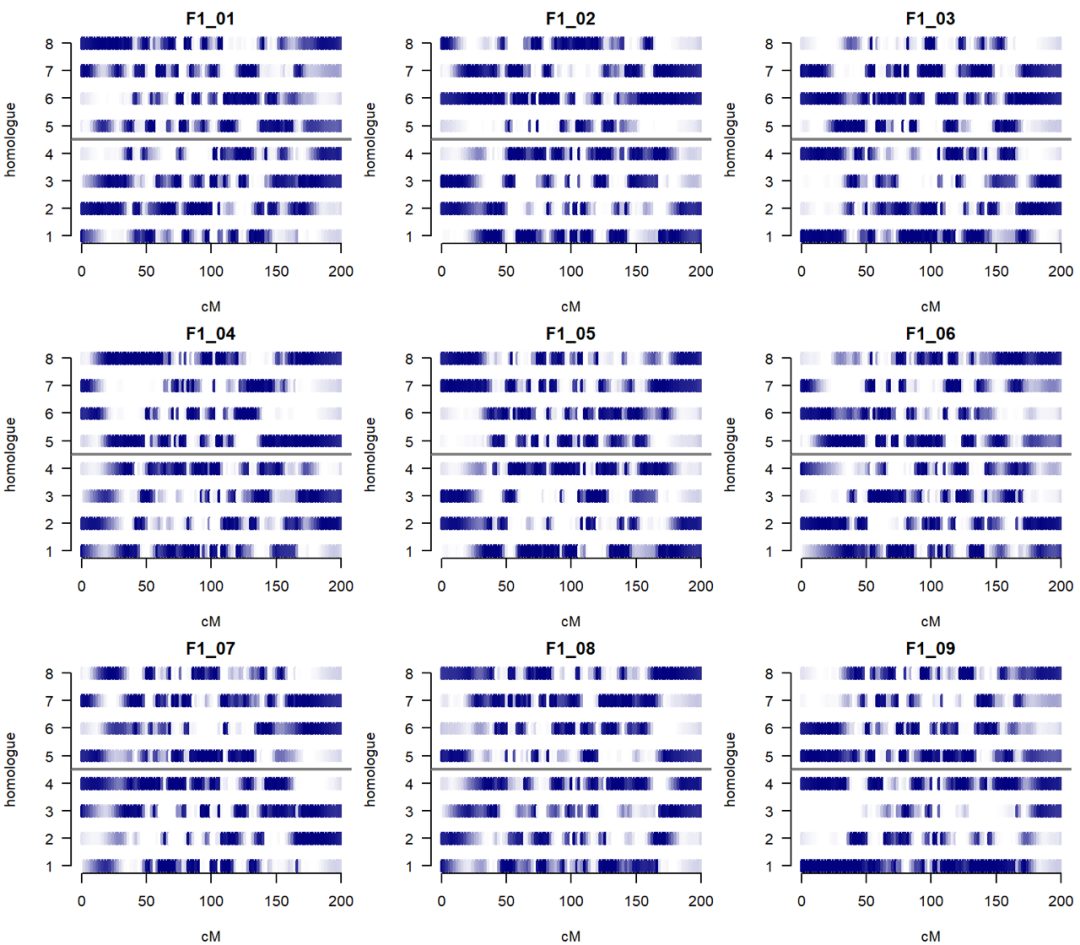
1. polyqtlR: 提供多倍体双亲F1群体数量性状基因座(QTL)分析的功能.
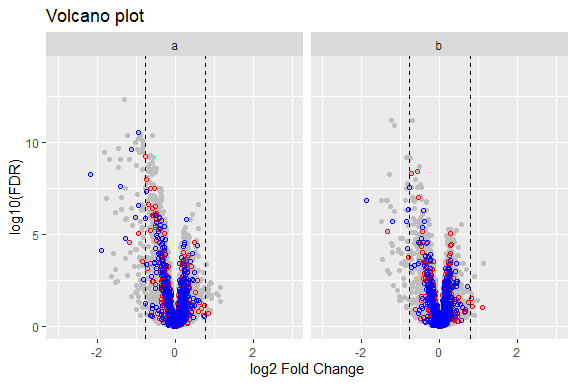
2. RPPASPACE: 提供用于分析反相蛋白质阵列(RPPA)的工具,该阵列也称为组织裂解物阵列或简单裂解物阵列.
3. RVA: 在RNAseq分析中,支持下游可视化和路径分析的自动化实现.
四. 机器学习
1. comparator: 实现用于比较字符串、序列和数字向量的函数,用于集群和记录链接应用程序。它包括用于比较序列/字符串的广义编辑距离、用于标记集模糊比较的Monge-Elkan相似性和用于比较数值向量的L-p距离.
2. DoubleML: 针对部分线性回归模型、线性工具变量回归模型、交互回归模型和交互工具变量回归模型,实施Chernozhukov等人(2018)的双/基于Debiase的机器学习框架.
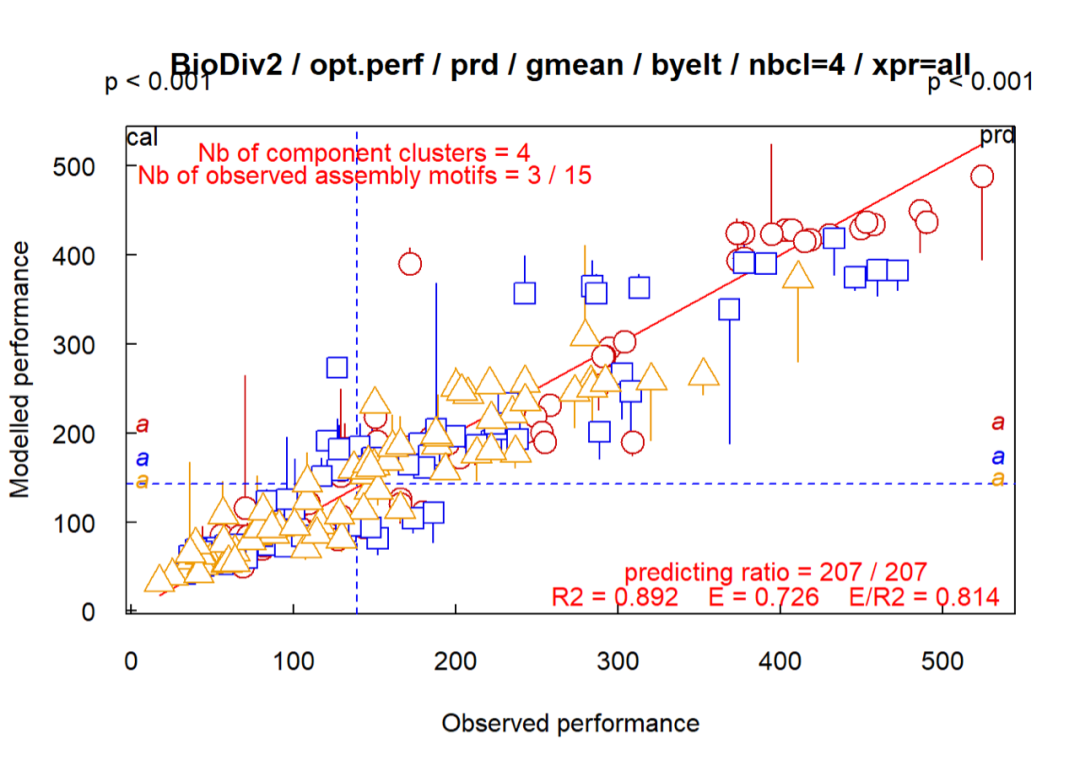
3. functClust: 支持将组成交互式系统的组件聚类,以实现一个或多个集体的系统性能.
4. mlpack: 实现与mlpack C ++机器学习库的绑定.
5. RFCCA: 使用典型相关分析实现随机林,这是一种根据主题相关协变量估计两组变量之间典型相关的方法.
五. 医药学
1. babsim.hospital: 实现了医院资源规划的离散事件仿真模型。受当前COVID-19大流行中卫生保健机构所面临的挑战的影响,卫生部门可以利用它来预测对重症监护病床、呼吸机和人力资源的需求.
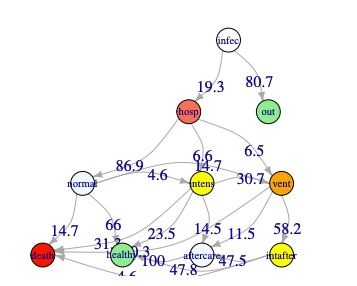
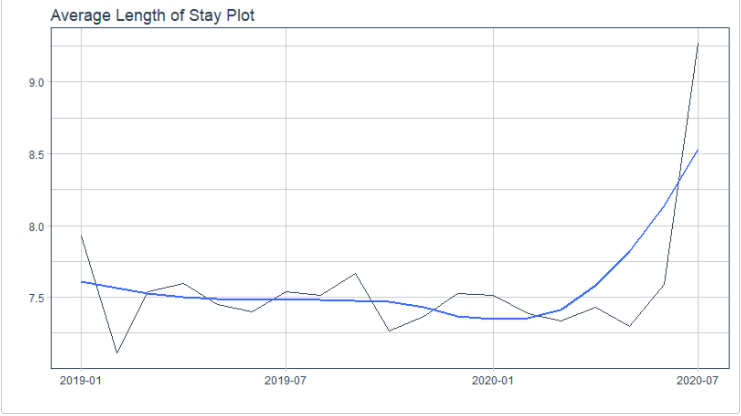
2. healthyR: 提供一个医院数据分析工作流工具,包括建模工具和用于查看常见行政医院数据的工具,如平均住院时间、再入院率、按服务项目列出的平均净付款额等.
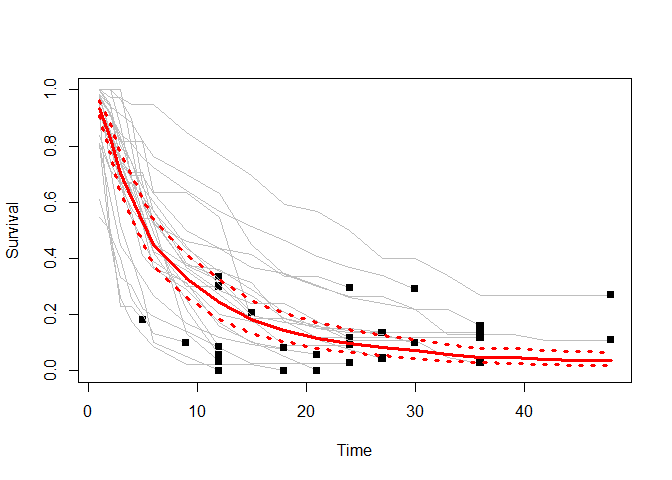
3. metaSurvival: 提供评估汇总生存曲线中的信息并测试层间异质性的功能.
六. 科学
1. cmcR: 实现了Song(2013)提出的用于弹壳识别的全等匹配单元方法,以及Tong等人提出的方法的扩展.
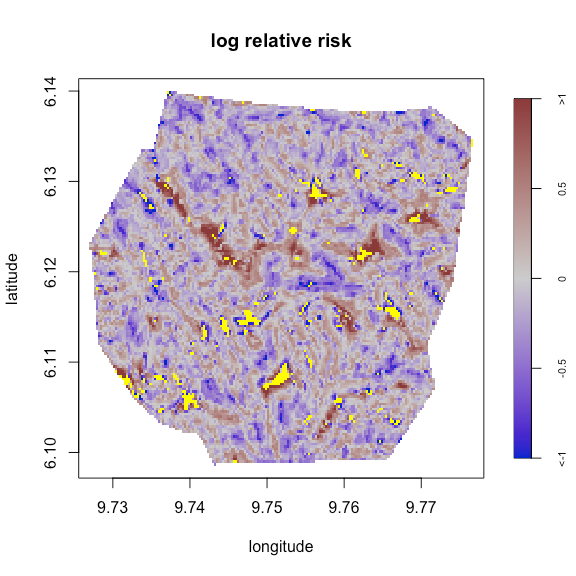
2. envi: 提供使用发生数据、协变量、基于核密度的估计和空间相对风险的环境插值工具。有关空间相对风险的详细信息,请参见Davies et al.(2018),Bithell(1990)用于核密度估计,Bithell(1991)用于相对风险估计.
3. PAMpal: 提供加载和处理被动声学数据的工具,包括读取Pamguard数据、处理和导出数据的功能.

七. 统计学
1. bpcs: 使用Stan实现成对比较数据分析模型,包括随机效应、预测因子的广义模型和Bradley-Terry模型的顺序效应贝叶斯版本.
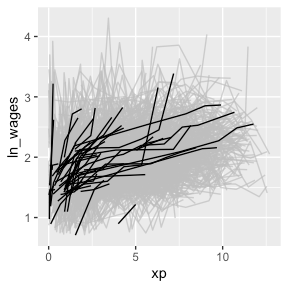
2. brolgar: 提供一个工具框架,用于总结、可视化和探索纵向数据,包括计算特征和汇总统计数据以及对单个序列进行采样的方法.
3. MASSExtra: 为MASS包提供增强、扩展和添加(例如Gramm-Schmidt正交化和广义特征值问题),并提供方便的默认设置和用户界面.
4. motifr: 提供用于多级网络中的主题分析的工具,以可视化多级网络,对多级网络主题进行计数并将主题出现与基准模型进行比较.
5. OptCirClust: 基于优化框架聚类的核心算法,为循环、周期或框架数据提供快速(运行时=O(K N log^2 N)、最佳、可重复的聚类算法.
6. pflamelet: 提供计算持久性Flamelet的函数,这是一种用于探索Padellini和Brutti(2017)中介绍的尺度空间族拓扑不变量的统计工具.
7. PRDA: 执行Gelman&Carlin(2014)提出的设计分析,将功率分析评估与其他推断风险相结合.
8. puls: 通过提供一种使用曲线的子区域信息对功能数据进行聚类的方法来补充fda和fda.use包.
八. 应用工具
1. coro: 提供协同程序,这是一系列可以在以后挂起和恢复的函数。这包括异步函数(等待)和生成器(产生).
2. dataReporter: 提供用于自动生成可自定义数据报告的函数,该报告显示数据集中的潜在错误.
3. DescrTab2: 提供为连续变量和分类变量创建描述性统计表的函数.
4. libr: 提供创建数据库、生成数据字典和模拟数据步骤的功能.
5. outsider: 允许用户通过使用Docker和联机存储库在R中安装和运行外部命令行程序.
6. srcr: 提供一个简单的工具,用于从源代码中提取连接详细信息(包括机密凭据),并管理常用数据库连接的配置.
九. 数据可视化
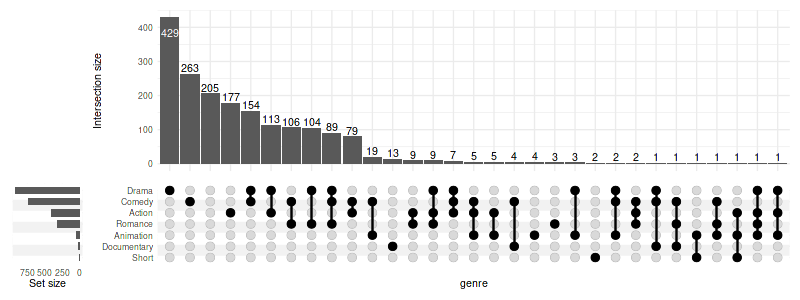
1. ComplexUpset: 提供创建翻转图的函数,该函数提供了对集合重叠可视化的维恩图的改进.
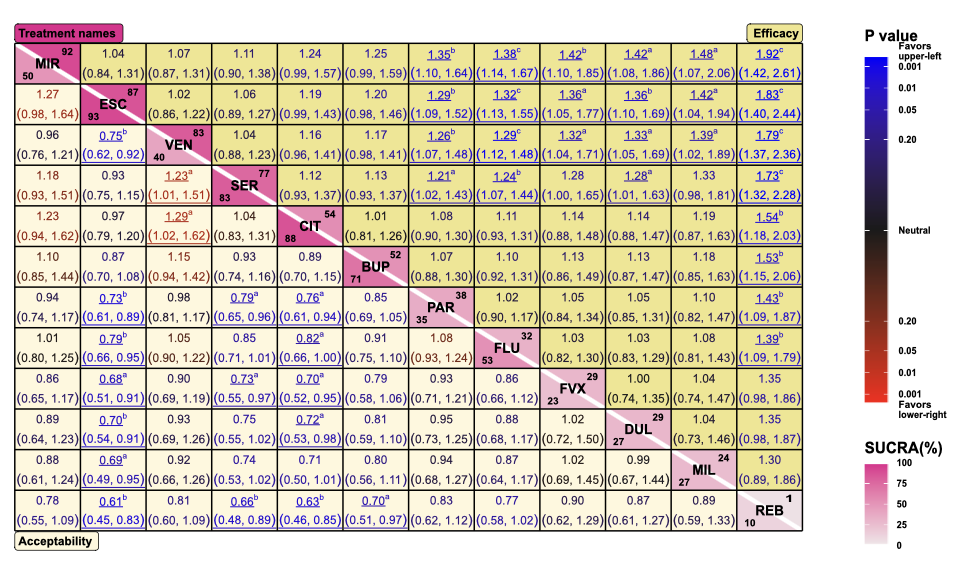
2. nmaplateplot: 提供网络元分析(NMA)结果的图形显示,该结果适用于优势比、风险比、风险差异和标准化平均差异等结果.
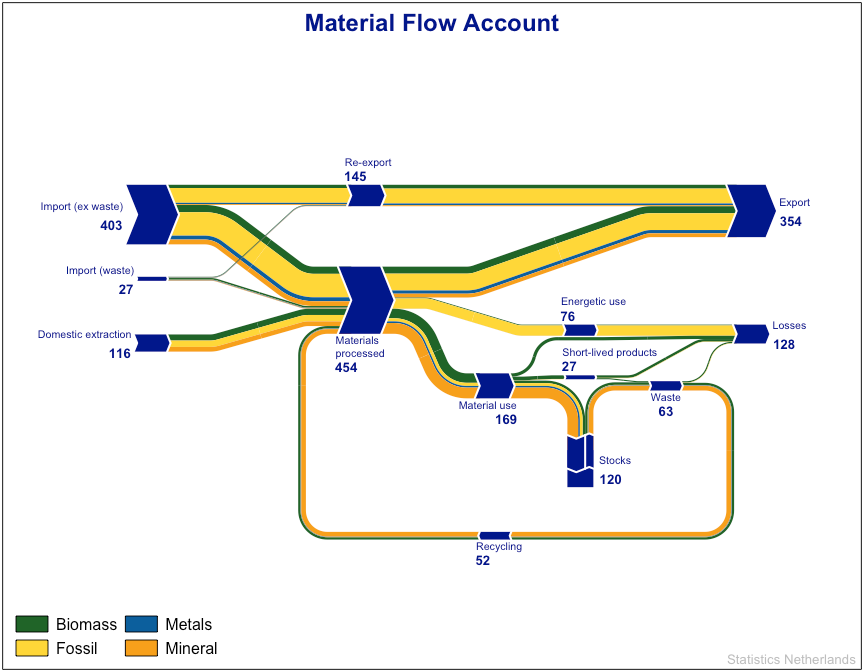
3. PantaRhei: 提供产生Sankey图的功能,这些图用于可视化保守物质通过系统的流动.
说明:限于个人水平,错误之处难免,烦请批评指正,共同交流~
原文:https://rviews.rstudio.com/2021/01/29/dec-2020-top-40-new-cran-packages/

北京大学出版社《R语言数据分析与可视化从入门到精通》
学R语言、练语法、取数据、预处理、可视化、交互图、重实战……一书在手,精通R语言数据分析与可视化!
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集
(请备注姓名-学校/企业-职务等)
评论