
面试官发难,如何用 SQL 来查询 Elasticsearch 中的数据?
点击“开发者技术前线”,选择“星标🔝”
让一部分开发者看到未来

回复“666”,获取一份技术人专属大礼包
参考:https://elasticstack.blog.csdn.net/article/details/105199768
在今天的文章里,我们将简单介绍一下如何使用 Elasticsearch SQL来对我们的数据进行查询。在之前的一篇文章“Kibana:Canvas入门”里也有 Elasticsearch SQL 的具体用例介绍。
安装
对于还没安装好自己的 Elasticsearch 的开发者来说,你可以参阅我之前的文章“Elastic:菜鸟上手指南”来进行安装自己的 Elasticsearch 及 Kibana。在这里我就不累述了。
准备数据
我们首先打开 Kibana:
点击上面的“Load a data set and a Kibana dashboard”:
点击上面的 Add data,这样我们就可以完成实验数据的导入了。在 Elasticsearch 中,我们会找到一个叫 kibana_sample_data_flights 的索引。
SQL 实操
检索 Elasticsearch schema 信息:DSL vs SQL
首先,我们确定表/索引的 schema 以及可供我们使用的字段。我们将通过 REST 界面执行此操作:
POST /_sql{"query": """DESCRIBE kibana_sample_data_flights"""}上面命令的结果:{"columns" : [{"name" : "column","type" : "keyword"},{"name" : "type","type" : "keyword"},{"name" : "mapping","type" : "keyword"}],"rows" : [["AvgTicketPrice","REAL","float"],["Cancelled","BOOLEAN","boolean"],["Carrier","VARCHAR","keyword"],["Dest","VARCHAR","keyword"],["DestAirportID","VARCHAR","keyword"],["DestCityName","VARCHAR","keyword"],["DestCountry","VARCHAR","keyword"],["DestLocation","GEOMETRY","geo_point"],["DestRegion","VARCHAR","keyword"],["DestWeather","VARCHAR","keyword"],["DistanceKilometers","REAL","float"],["DistanceMiles","REAL","float"],["FlightDelay","BOOLEAN","boolean"],["FlightDelayMin","INTEGER","integer"],["FlightDelayType","VARCHAR","keyword"],["FlightNum","VARCHAR","keyword"],["FlightTimeHour","VARCHAR","keyword"],["FlightTimeMin","REAL","float"],["Origin","VARCHAR","keyword"],["OriginAirportID","VARCHAR","keyword"],["OriginCityName","VARCHAR","keyword"],["OriginCountry","VARCHAR","keyword"],["OriginLocation","GEOMETRY","geo_point"],["OriginRegion","VARCHAR","keyword"],["OriginWeather","VARCHAR","keyword"],["dayOfWeek","INTEGER","integer"],["timestamp","TIMESTAMP","datetime"]]}
也可以通过 url 参数 format = txt 以表格形式格式化以上响应。例如:
POST /_sql?format=txt{"query": "DESCRIBE kibana_sample_data_flights"}
上面命令查询的结果是:
column | type | mapping------------------+---------------+---------------AvgTicketPrice |REAL |floatCancelled |BOOLEAN |booleanCarrier |VARCHAR |keywordDest |VARCHAR |keywordDestAirportID |VARCHAR |keywordDestCityName |VARCHAR |keywordDestCountry |VARCHAR |keywordDestLocation |GEOMETRY |geo_pointDestRegion |VARCHAR |keywordDestWeather |VARCHAR |keywordDistanceKilometers|REAL |floatDistanceMiles |REAL |floatFlightDelay |BOOLEAN |booleanFlightDelayMin |INTEGER |integerFlightDelayType |VARCHAR |keywordFlightNum |VARCHAR |keywordFlightTimeHour |VARCHAR |keywordFlightTimeMin |REAL |floatOrigin |VARCHAR |keywordOriginAirportID |VARCHAR |keywordOriginCityName |VARCHAR |keywordOriginCountry |VARCHAR |keywordOriginLocation |GEOMETRY |geo_pointOriginRegion |VARCHAR |keywordOriginWeather |VARCHAR |keyworddayOfWeek |INTEGER |integertimestamp |TIMESTAMP |datetime
是不是感觉回到 SQL 时代啊:)
向前迈进,只要提供来自 REST api 的示例响应,我们就会使用上面显示的表格响应结构。要通过控制台实现相同的查询,需要使用以下命令登录:
./bin/elasticsearch-sql-cli http://localhost:9200我们可在屏幕上看到如下的画面:

太神奇了。我们直接看到 SQL 的命令提示符了。在上面的命令行中,我们打入如下的命令:
DESCRIBE kibana_sample_data_flights;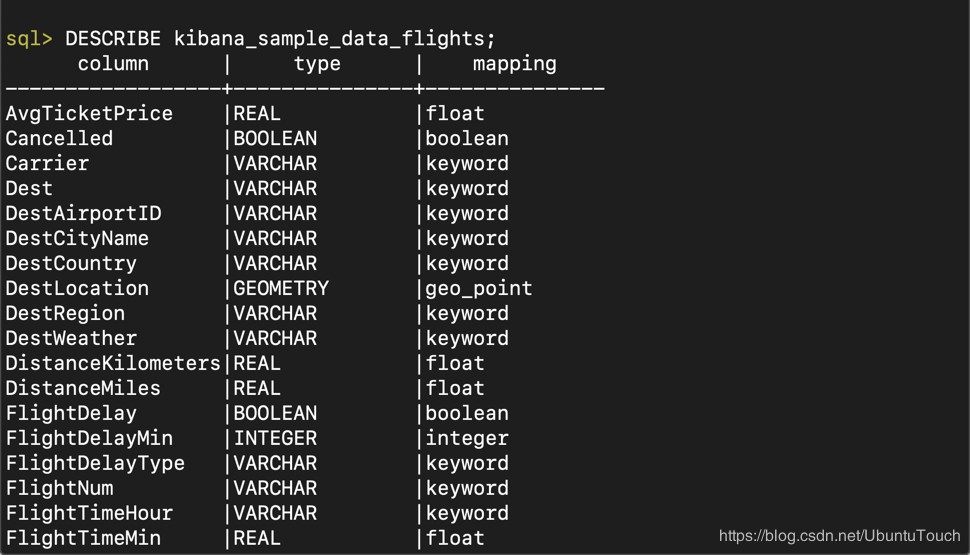
这个结果和我们在Kibana中得到的结果是一样的。
上面的schema也会随对在 SELECT 子句中显示的字段的任何查询一起返回,从而为任何潜在的驱动程序提供格式化或对结果进行操作所需的必要类型信息。例如,考虑带有 LIMIT 子句的简单 SELECT,以使响应简短。默认情况下,我们返回1000行。
我们发现索引的名字 kibana_sample_data_flights 比较长,为了方便,我们来创建一个alias:
PUT /kibana_sample_data_flights/_alias/flights这样在以后的操作中,当我们使用flights的时候,其实也就是对索引kibana_sample_data_flights 进行操作。
我们执行如下的命令:
POST /_sql?format=txt{"query": "SELECT FlightNum FROM flights LIMIT 1"}
显示结果:
FlightNum---------------9HY9SWR
相同的REST请求/响应由JDBC驱动程序和控制台使用:
SELECT OriginCountry, OriginCityName FROM flights LIMIT 1;OriginCountry | OriginCityName---------------+-----------------DE |Frankfurt am Main
请注意,如果在任何时候请求的字段都不存在(区分大小写),则表格式和强类型存储区的语义意味着将返回错误-这与 Elasticsearch 行为不同,在该行为中,根本不会返回该字段。例如,将上面的内容修改为使用字段“OrigincityName”而不是“OriginCityName”会产生有用的错误消息:
SELECT OriginCountry, OrigincityName FROM flights LIMIT 1;Bad request [Found 1 problem(s)line 1:23: Unknown column [OrigincityName], did you mean any of [OriginCityName, DestCityName]?]
同样,如果我们尝试在不兼容的字段上使用函数或表达式,则会出现相应的错误。通常,分析器在验证 AST 时会较早失败。为了实现这一点,Elasticsearch 必须了解每个字段的索引映射和功能。因此,任何具有安全性访问 SQL 接口的客户端都需要适当的权限。
如果我们继续提供每一个请求和相应的回复,我们将最终获得一篇冗长的博客文章!为了简洁起见,以下是一些带有感兴趣的注释的日益复杂的查询。
使用 WHERE 及 ORDER BY 来 SELECT
“找到飞行时间超过5小时的美国最长10班航班。”
POST /_sql?format=txt{"query": """SELECT OriginCityName, DestCityName FROM flights WHERE FlightTimeHour > 5 AND OriginCountry='US' ORDER BY FlightTimeHour DESC LIMIT 10"""}
显示结果是:
OriginCityName | DestCityName---------------+-------------------Chicago |OsloCleveland |SeoulDenver |Chitose / TomakomaiNashville |VeronaMinneapolis |TokyoPortland |TrevisoSpokane |ViennaKansas City |ZurichKansas City |ShanghaiLos Angeles |Zurich
限制行数的运算符因 SQL 实现而异。对于 Elasticsearch SQL,我们在实现LIMIT运算符时与 Postgresql/Mysql 保持一致。
Math
只是一些随机数字...
sql> SELECT ((1 + 3) * 1.5 / (7 - 6)) * 2 AS random;random---------------12.0
这代表服务器端对功能执行某些后处理的示例。没有等效的Elasticsearch DSL查询。
Functions & Expressions
“在2月份之后查找所有航班,该航班的飞行时间大于5小时,并且按照时间最长来排序。”
POST /_sql?format=txt{"query": """SELECT MONTH_OF_YEAR(timestamp), OriginCityName, DestCityName FROM flights WHERE FlightTimeHour > 1 AND MONTH_OF_YEAR(timestamp) > 2 ORDER BY FlightTimeHour DESC LIMIT 10"""}
显示结果是:
MONTH_OF_YEAR(timestamp)|OriginCityName | DestCityName------------------------+---------------+---------------4 |Chicago |Oslo4 |Osaka |Spokane4 |Quito |Tucson4 |Shanghai |Stockholm5 |Tokyo |Venice5 |Tokyo |Venice5 |Tokyo |Venice5 |Buenos Aires |Treviso5 |Amsterdam |Birmingham5 |Edmonton |Milan
这些功能通常需要在 Elasticsearch 中运用 Painless 变形才能达到等效的效果,而 SQL 的功能声明避免任何脚本编写。还要注意我们如何在WHERE和SELECT子句中使用该函数。WHERE 子句组件被下推到 Elasticsearch,因为它影响结果计数。SELECT 函数由演示中的服务器端插件处理。
请注意,可用功能列表可通过“SHOW FUNCTIONS”检索
SHOW FUNCTIONS;name | type-----------------+---------------AVG |AGGREGATECOUNT |AGGREGATEFIRST |AGGREGATEFIRST_VALUE |AGGREGATELAST |AGGREGATELAST_VALUE |AGGREGATEMAX |AGGREGATE...
将其与我们之前的数学能力相结合,我们可以开始制定查询,对于大多数DSL用户来说,查询将非常复杂。
“找出最快的2个航班(速度)的距离和平均速度,这些航班在星期一,星期二或星期三上午9点至11点之间离开,并且距离超过500公里。将距离和速度四舍五入到最接近的整数。如果速度相等,请先显示最长的时间。”
首先我们在上面的 DESCRIBE kibana_sample_data_flights 命令的输出中,我们可以看到FlightTimeHour 是一个 keyword。这个显然是不对的,因为它是一个数值。也许在最初的设计时这么想的。我们需要把这个字段改为 float 类型的数据。
PUT flight1{"mappings": {"properties": {"AvgTicketPrice": {"type": "float"},"Cancelled": {"type": "boolean"},"Carrier": {"type": "keyword"},"Dest": {"type": "keyword"},"DestAirportID": {"type": "keyword"},"DestCityName": {"type": "keyword"},"DestCountry": {"type": "keyword"},"DestLocation": {"type": "geo_point"},"DestRegion": {"type": "keyword"},"DestWeather": {"type": "keyword"},"DistanceKilometers": {"type": "float"},"DistanceMiles": {"type": "float"},"FlightDelay": {"type": "boolean"},"FlightDelayMin": {"type": "integer"},"FlightDelayType": {"type": "keyword"},"FlightNum": {"type": "keyword"},"FlightTimeHour": {"type": "float"},"FlightTimeMin": {"type": "float"},"Origin": {"type": "keyword"},"OriginAirportID": {"type": "keyword"},"OriginCityName": {"type": "keyword"},"OriginCountry": {"type": "keyword"},"OriginLocation": {"type": "geo_point"},"OriginRegion": {"type": "keyword"},"OriginWeather": {"type": "keyword"},"dayOfWeek": {"type": "integer"},"timestamp": {"type": "date"}}}}
我们需要 reindex 这个索引。
POST _reindex{"source": {"index": "flights"},"dest": {"index": "flight1"}}
那么现在 flight1 的数据中,FlightTimeHour 字段将会是一个 float 的类型。我们再次重新设置 alias 为 flights:
POST _aliases{"actions": [{"add": {"index": "flight1","alias": "flights"}},{"remove": {"index": "kibana_sample_data_flights","alias": "flights"}}]}
那么现在 flights 将是指向 flight1 的一个 alias。
我们使用如下的 SQL 语句来查询:
sql> SELECT timestamp, FlightNum, OriginCityName, DestCityName, ROUND(DistanceMiles) AS distance, ROUND(DistanceMiles/FlightTimeHour) AS speed, DAY_OF_WEEK(timestamp) AS day_of_week FROM flights WHERE DAY_OF_WEEK(timestamp) >= 0 AND DAY_OF_WEEK(timestamp) <= 2 AND HOUR_OF_DAY(timestamp) >=9 AND HOUR_OF_DAY(timestamp) <= 10 ORDER BY speed DESC, distance DESC LIMIT 2;timestamp | FlightNum |OriginCityName | DestCityName | distance | speed | day_of_week------------------------+---------------+---------------+---------------+---------------+---------------+---------------2020-05-17T10:53:52.000Z|LAJSKLT |Guangzhou |Lima |11398.0 |783.0 |12020-04-27T09:30:39.000Z|VLUDO2H |Buenos Aires |Moscow |8377.0 |783.0 |2
一个相当复杂且奇怪的问题,但希望您能明白这一点。还要注意我们如何创建字段别名并在ORDER BY 子句中引用它们。
还要注意,不需要在 SELECT 子句中指定 WHERE 和 ORDER BY 中使用的所有字段。这可能与您过去使用的 SQL 实现不同。例如,以下内容完全正确:
POST /_sql{"query":"SELECT timestamp, FlightNum FROM flights WHERE AvgTicketPrice > 500 ORDER BY AvgTicketPrice"}
它显示:
{"columns" : [{"name" : "timestamp","type" : "datetime"},{"name" : "FlightNum","type" : "text"}],"rows" : [["2020-04-26T09:04:20.000Z","QG5DXD3"],["2020-05-02T23:18:27.000Z","NXA71BT"],["2020-04-17T01:55:18.000Z","VU8K9DM"],["2020-04-24T08:46:45.000Z","UM8IKF8"],...]
我们都曾尝试过要在 Elasticsearch DSL 中表达的 SQL 查询,或者想知道它是否是最佳的。新 SQL 接口的引人注目的功能之一是它能够协助 Elasticsearch 的新采用者解决此类问题。使用 REST 接口,我们只需将/translate附加到“sql”端点,即可获取驱动程序将发出的Elasticsearch 查询。
让我们考虑一下以前的一些查询:
POST /_sql/translate{"query": "SELECT OriginCityName, DestCityName FROM flights WHERE FlightTimeHour > 5 AND OriginCountry='US' ORDER BY FlightTimeHour DESC LIMIT 10"}
对于任何有经验的 Elasticsearch 用户,等效的 DSL 都应该是显而易见的:
{"size" : 10,"query" : {"bool" : {"must" : [{"range" : {"FlightTimeHour" : {"from" : 5,"to" : null,"include_lower" : false,"include_upper" : false,"boost" : 1.0}}},{"term" : {"OriginCountry.keyword" : {"value" : "US","boost" : 1.0}}}],"adjust_pure_negative" : true,"boost" : 1.0}},"_source" : {"includes" : ["OriginCityName","DestCityName"],"excludes" : [ ]},"sort" : [{"FlightTimeHour" : {"order" : "desc","missing" : "_first","unmapped_type" : "float"}}]}
WHERE 子句将按您期望的那样转换为 range 和 term 查询。请注意,子字段的OriginCountry.keyword变体如何用于与父代 OriginCountry(文本类型)的精确匹配。不需要用户知道基础映射的行为差异-正确的字段类型将会被自动选择。有趣的是,该接口尝试通过在 _source 上使用 docvalue_fields 来优化检索性能,例如适用于启用了 doc 值的确切类型(数字,日期,关键字)。我们可以依靠 Elasticsearch SQL 为指定的查询生成最佳的 DSL。
现在考虑我们上次使用的最复杂的查询:
POST /_sql/translate{"query": """SELECT timestamp, FlightNum, OriginCityName, DestCityName, ROUND(DistanceMiles) AS distance, ROUND(DistanceMiles/FlightTimeHour) AS speed, DAY_OF_WEEK(timestamp) AS day_of_week FROM flights WHERE DAY_OF_WEEK(timestamp) >= 0 AND DAY_OF_WEEK(timestamp) <= 2 AND HOUR_OF_DAY(timestamp) >=9 AND HOUR_OF_DAY(timestamp) <= 10 ORDER BY speed DESC, distance DESC LIMIT 2"""}
上面的响应为:
{"size" : 2,"query" : {"bool" : {"must" : [{"script" : {"script" : {"source" : "InternalSqlScriptUtils.nullSafeFilter(InternalSqlScriptUtils.and(InternalSqlScriptUtils.gte(InternalSqlScriptUtils.dateTimeChrono(InternalSqlScriptUtils.docValue(doc,params.v0), params.v1, params.v2), params.v3), InternalSqlScriptUtils.lte(InternalSqlScriptUtils.dateTimeChrono(InternalSqlScriptUtils.docValue(doc,params.v4), params.v5, params.v6), params.v7)))","lang" : "painless","params" : {"v0" : "timestamp","v1" : "Z","v2" : "HOUR_OF_DAY","v3" : 9,"v4" : "timestamp","v5" : "Z","v6" : "HOUR_OF_DAY","v7" : 10}},"boost" : 1.0}},{"script" : {"script" : {"source" : "InternalSqlScriptUtils.nullSafeFilter(InternalSqlScriptUtils.and(InternalSqlScriptUtils.gte(InternalSqlScriptUtils.dayOfWeek(InternalSqlScriptUtils.docValue(doc,params.v0), params.v1), params.v2), InternalSqlScriptUtils.lte(InternalSqlScriptUtils.dayOfWeek(InternalSqlScriptUtils.docValue(doc,params.v3), params.v4), params.v5)))","lang" : "painless","params" : {"v0" : "timestamp","v1" : "Z","v2" : 0,"v3" : "timestamp","v4" : "Z","v5" : 2}},"boost" : 1.0}}],"adjust_pure_negative" : true,"boost" : 1.0}},"_source" : {"includes" : ["FlightNum","OriginCityName","DestCityName","DistanceMiles","FlightTimeHour"],"excludes" : [ ]},"docvalue_fields" : [{"field" : "timestamp","format" : "epoch_millis"}],"sort" : [{"_script" : {"script" : {"source" : "InternalSqlScriptUtils.nullSafeSortNumeric(InternalSqlScriptUtils.round(InternalSqlScriptUtils.div(InternalSqlScriptUtils.docValue(doc,params.v0),InternalSqlScriptUtils.docValue(doc,params.v1)),params.v2))","lang" : "painless","params" : {"v0" : "DistanceMiles","v1" : "FlightTimeHour","v2" : null}},"type" : "number","order" : "desc"}},{"_script" : {"script" : {"source" : "InternalSqlScriptUtils.nullSafeSortNumeric(InternalSqlScriptUtils.round(InternalSqlScriptUtils.docValue(doc,params.v0),params.v1))","lang" : "painless","params" : {"v0" : "DistanceMiles","v1" : null}},"type" : "number","order" : "desc"}}]}
是不是觉得非常复杂啊?
我们的 WHERE 和 ORDER BY 子句已转换为 painless 脚本,并在 Elasticsearch 提供的排序和脚本查询中使用。这些脚本甚至被参数化以避免编译并利用脚本缓存。
附带说明一下,尽管以上内容代表了 SQL 语句的最佳翻译,但并不代表解决更广泛问题的最佳解决方案。实际上,我们希望在索引时间对文档中的星期几,一天中的小时和速度进行编码,因此可以只使用简单的范围查询。这可能比使用painless 脚本解决此特定问题的性能更高。实际上,由于这些原因,其中的某些字段实际上甚至已经存在于文档中。这是用户应注意的常见主题:尽管我们可以依靠 Elasticsearch SQL 实现为我们提供最佳翻译,但它只能利用查询中指定的字段,因此不一定能为更大的问题查询提供最佳解决方案。为了实现最佳方法,需要考虑基础平台的优势,而 _translate API 可能是此过程的第一步。
END
前线推出学习交流群,加群一定要备注:研究/工作方向+地点+学校/公司+昵称(如大数据+上海+携程+可可),根据格式备注,可更快被通过且邀请进群,领取一份专属学习礼包 扫码家助理微信进群,内推和技术交流,大佬们零距离