
从源码角度分析yarn安装依赖的过程
yarn是我们经常用到的包管理工具,之前写过一篇文章文章《前端工程师应该知道的yarn知识》,里面介绍了作为前端攻城狮应该知道的yarn知识,但是对yarn安装包的具体过程,并没有具体讲解。
本文将从源码的角度解读yarn安装包的过程,为了方便大家理解,并不会搬源码出来,而是借助几张流程图,帮助大家了解这个过程。
本文将从以下几点来展开介绍:
工作中常见的问题 yarn的一些核心概念 yarn的具体安装过程
工作中常见的问题
各位小伙伴,工作中不知道是否有以下这些疑问呢?
安装依赖出现问题时,删除yarn.lock,再重新install,这样操作有风险吗? 开发时,我把所有依赖都安装到dependence中,会有问题吗? 项目和这个项目的某个依赖都依赖了同一个包,这个包会被多次安装、重复打包吗? 开发同一个项目,有的同学使用yarn,有的同学使用npm,有问题吗?
这里先不揭晓答案,读完本文可以解除这些困惑
基本概念
为了更好的理解yarn安装的过程,我们先复习一下yarn的一些重要概念。
Registry
registry 也就是我们常说的源,指模块仓库地址, 它提供了一个查询服务。
以 yarn 官方镜像源为例,它的查询服务网址是:https://registry.yarnpkg.com,我们可以在url后面拼接对应package名字,来查询某个包的所有版本的包信息,如 https://registry.yarnpkg.com / vue,也可以拼接具体的包版本,查看某个包的具体版本的包信息,如https://registry.yarnpkg.com/broccoli-kitchen-sink-helpers/0.3.1。下面我们看一下返回的具体包信息:
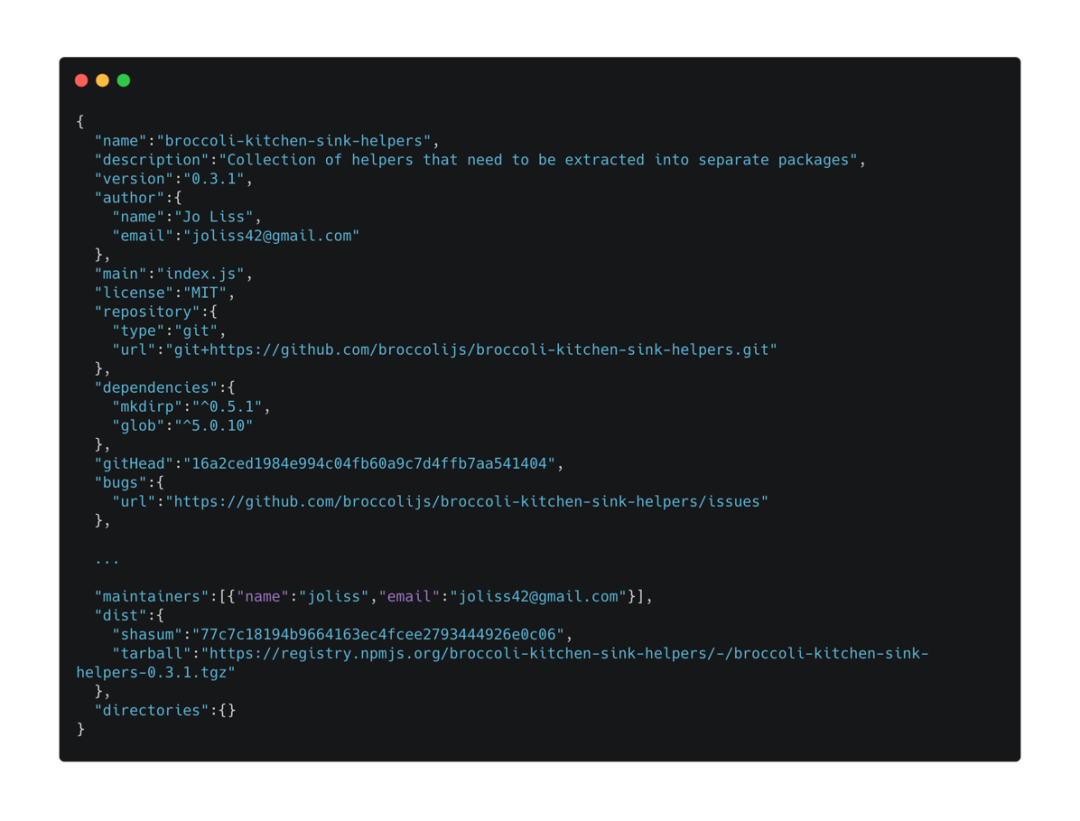
可以看到返回的包信息中,包括包名字,描述信息,作者,依赖dependence等信息。其中有一个dist对象,dist.tarball对应的是package压缩包的地址,dist.shasum对应的hash。
依赖版本
yarn 的包遵守 semver,即语义化版本。SemVer 是一套语义化版本控制的约定,定义的格式为: yarn中 依赖版本范围 的表示方法有以下几种:
yarn中 依赖版本范围 的表示方法有以下几种: 我们平时使用
我们平时使用yarn add [package-name]命令安装依赖,默认使用的是 ^ 范围。每种范围表示方法的具体含义可参看《前端工程师应该知道的yarn知识》,不是本文的重点。
依赖类型
「dependences」
代码运行时所需要的依赖,比如vue,vue-router「devDependences」
开发依赖,就是那些只在开发过程中需要,而运行时不需要的依赖,比如babel,webpack「peerDependences」
同伴依赖,它用来告知宿主环境需要什么依赖以及依赖的版本范围,如Vue组件库中需要依赖Vue「optionalDependences」
可选依赖,这种依赖即便安装失败,Yarn也会认为整个依赖安装过程是成功的。「bundledDependences」
打包依赖,在发布包时,这个数组里的包都会被打包到最终的发布包里
缓存
yarn 会将安装过的包缓存下来,这样再次安装相同包的时候,就不需要再去下载,而是直接从缓存文件中直接copy进来。
可以通过命令yarn cache dir查看yarn的全局缓存目录。yarn 会将不同版本解压后的包存放在不同目录下,命名方式:npm-[package name]-[version]-[shasum]

思考
这里思考一个小问题哈,安装依赖时,是什么时候把包copy到缓存目录下的呢?是先下载到node_modules,再copy到缓存目录吗?想知道继续往下看哦~
离线镜像
如果你以前安装过某个包,再次安装时可以在没有任何互联网连接的情况下进行。yarn的离线镜像是为了在无网络情况下使用的,是在本地维护了一个镜像,默认是不开启的。
Lock
上面我们说了yarn的是遵守语义化版本的,实际项目中我们需要保证在不同的机器上安装包能获得相同的结果,所以就有了锁的概念。
yarn.lock 中会准确的存储每个依赖的具体版本信息,以保证在不同机器安装可以得到相同的结果。
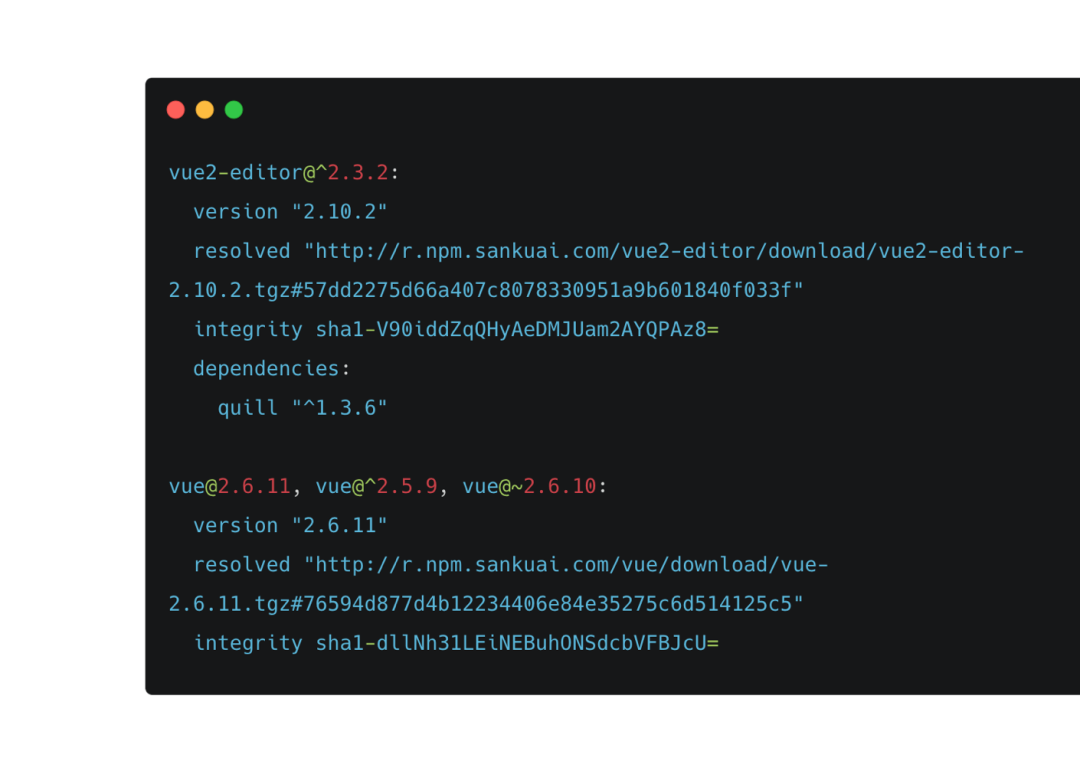 从lock文件内容可以看出,lock文件中会保存package name、语义化版本、package锁定的具体版本号、包的地址、hash,以及dependence依赖等。
从lock文件内容可以看出,lock文件中会保存package name、语义化版本、package锁定的具体版本号、包的地址、hash,以及dependence依赖等。
yarn 在安装期间,只会使用当前项目的yarn.lock文件(即顶级yarn.lock文件),会忽略任何依赖里面的 yarn.lock 文件。
在顶级yarn.lock中包含需要锁定的整个依赖树里全部包版本的所有信息。
yarn 安装依赖的过程
介绍了一些yarn的概念后,终终终于要说本文最核心的内容了,yarn是如何安装依赖的呢?yarn安装依赖会有以下几个步骤:

「Checking」
在正式安装前,yarn会做一些check工作,会检查是否有npm的一些配置文件(Shrinkwrap,npm lockfile),如果有,会提示用户避免存在这些文件,可能会导致冲突。之后会去检查一些Manifest,包括os,cpu,engines,模块兼容等配置项。「Resolving Packages」
解析包的信息,在这一步,会解析出依赖树中每个包的具体版本信息「Fetching Packages」
获取依赖包,这一步,会对缓存中没有的包进行下载,将对应package下载到缓存目录下,完成这一步,代表着依赖树中需要的所有包都存在缓存当中了「Linking Packages」
这一步,是将缓存中的对应包扁平化的安装到项目的依赖目录下(一般为node_modules)「Building Packages」
对于一些二进制包,需要进行编译,在此时进行
上面的步骤中,比较核心的安装过程是2.Resolving Packages ,3.Fetching Packages,4.Linking Packages,下面我们对这几个重要步骤的具体实现做详细介绍。
Resolving Packages
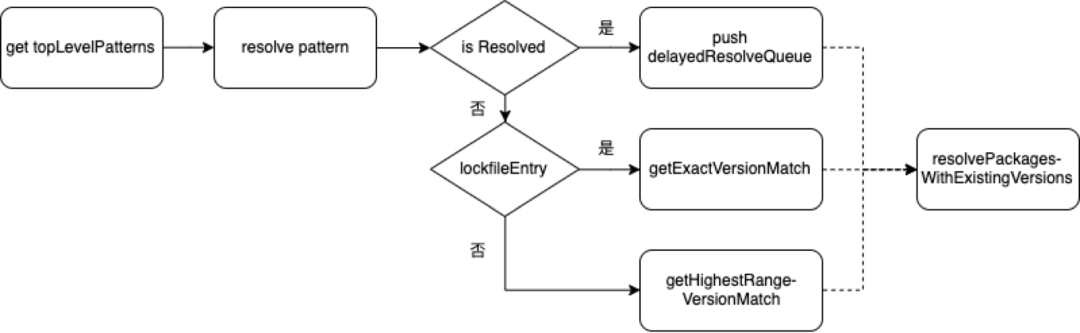 Resolving Packages,主要是解析依赖树中的每个package的包版本信息。
Resolving Packages,主要是解析依赖树中的每个package的包版本信息。
首先,从当前项目的package.json中获取首层依赖,首层依赖包括dependences、devDependences、optionalDependences 遍历首层依赖,调用find方法获取依赖包的版本信息,然后递归调用find,查找每个依赖下的dependence中依赖的版本信息。在解析包的同时使用一个Set(fetchingPatterns)来保存已经解析和正在解析的package。 在具体解析每个package时,首先会根据其name和range(版本范围)判断当前package是否为被解析过(即resolved)(通过判断是否存在于上面维护的set中,即可确定是否已经解析过) 对于未解析过的包,首先尝试从lockfile中获取到精确的版本信息, 如果lockfile中存在对于的package信息,获取后,标记成resolved(已解析)。如果lockfile中不存在该package的信息,则向registry发起请求获取满足range的已知最高版本的package信息,获取后,将当前package标记为resolved 对于已解析过的包,则将其放置到一个延迟队列(delayedResolveQueue)中先不处理 当依赖树的所有package都递归遍历完成后,再遍历delayedResolveQueue,在已经解析过的包信息中,找到最合适的可用版本信息
Resolving Packages 结束后,我们就确定了依赖树中所有package的具体版本,以及该包地址等详细信息。
Fetching Packages
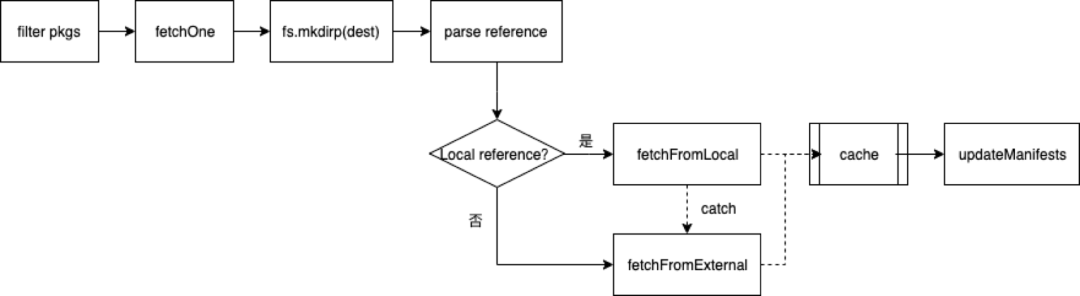 Fetching Packages,主要是对缓存中没有的package进行下载。
Fetching Packages,主要是对缓存中没有的package进行下载。
已经在缓存中存在的package,是不需要重新下载的,所以第一步先过滤掉本地缓存中已经存在的package。过滤过程是根据 cacheFolder+slug+node_modules+pkg.name生成一个path,判断系统中是否存在该path,如果存在,证明已经有缓存,不用重新下载,将它过滤掉。维护一个fetch任务的queue,根据Resolving Packages中解析出的包下载地址去依次获取包。 在下载每个包的时候,首先会在缓存目录下创建其对应的缓存目录,然后对包的reference地址进行解析。 如果reference是file协议,或者是相对路径,则说明其指向的是本地目录(即离线镜像),调用fetchFromLocal从离线缓存中获取包,否则调用fetchFromExternal到外部(registry) 获取包。 将获取的package文件流通过fs.createWriteStream写入到缓存目录下,缓存下来的是.tgz压缩文件,再解压到当前目录下 下载解压完成后,更新lockfile文件
Linking Packages

经过Fetching Packages后,我们本地缓存中已经有了所有的package,接下来就是如何将这些package复制到我们项目中的node_modules下。
在复制包之前,会先解析peerDependences,如果找不到匹配的peerDependences,进行warning提示 之后对依赖树进行扁平化处理,生成要拷贝到的目标目录dest 对扁平化后的目标dest进行排序(使用localeCompare本地排序规则) 根据flatTree中的dest(要拷贝到的目标目录地址),src(包的对应cache目录地址)中,执行将copy任务,将package从src拷贝到dest下。
在Fetching Packages中,最核心的就是如何生成扁平化的dest目录。
下面假设我们有如下的依赖关系树:
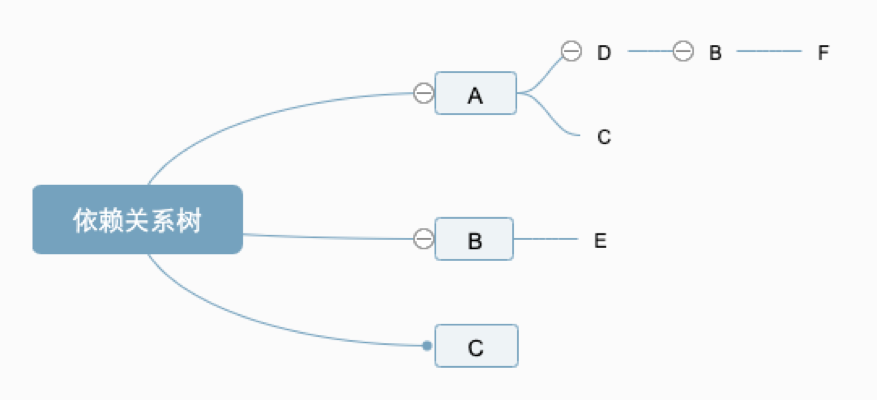 那么,如果我们没有进行扁平化的话,安装后的目录如下(#:代表安装到其前面package的node_modules下):
那么,如果我们没有进行扁平化的话,安装后的目录如下(#:代表安装到其前面package的node_modules下):
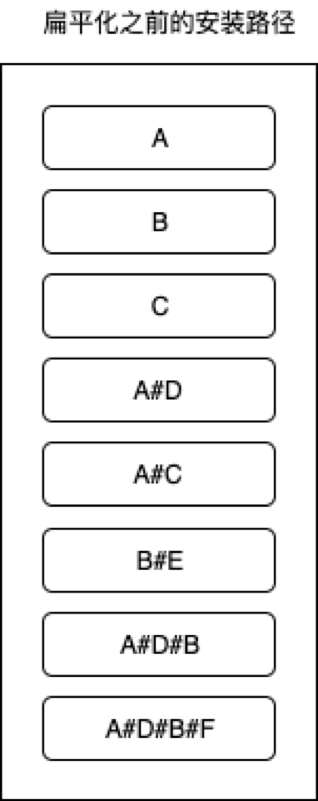
可以想象在安装A#D包(即在A的node_modules下安装D)的时候,因为根node_modules下只安装了A、B、C,没有D包,所以D是可以安装到根node_modules下的。
同理,在安装A#C时,由于根node_modules下已经存在C,所以这里不能够提升,只能将C安装到A的node_modules下。
在整个目录的提升过程中,会通过一个map来维护提升后的安装目录,在对每个安装路径进行分析时,会判断其是否存在于这个map中,来判断其安装的位置是否可以进行提升。
同理,其他的包安装过程也是上面这样,下面以最复杂的A#D#B#F来说明:
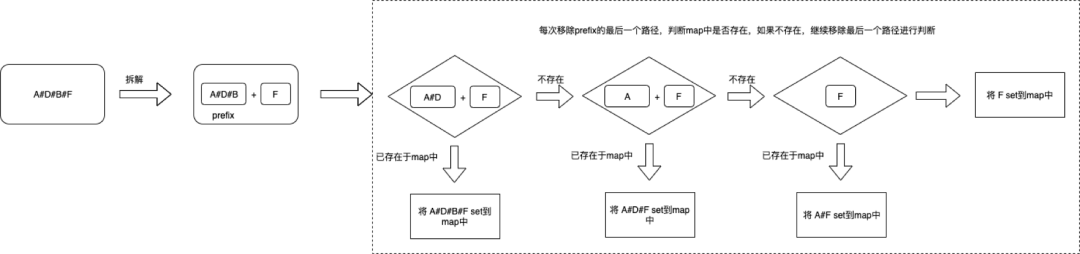
这样,我们扁平化后的安装目录就变成了:
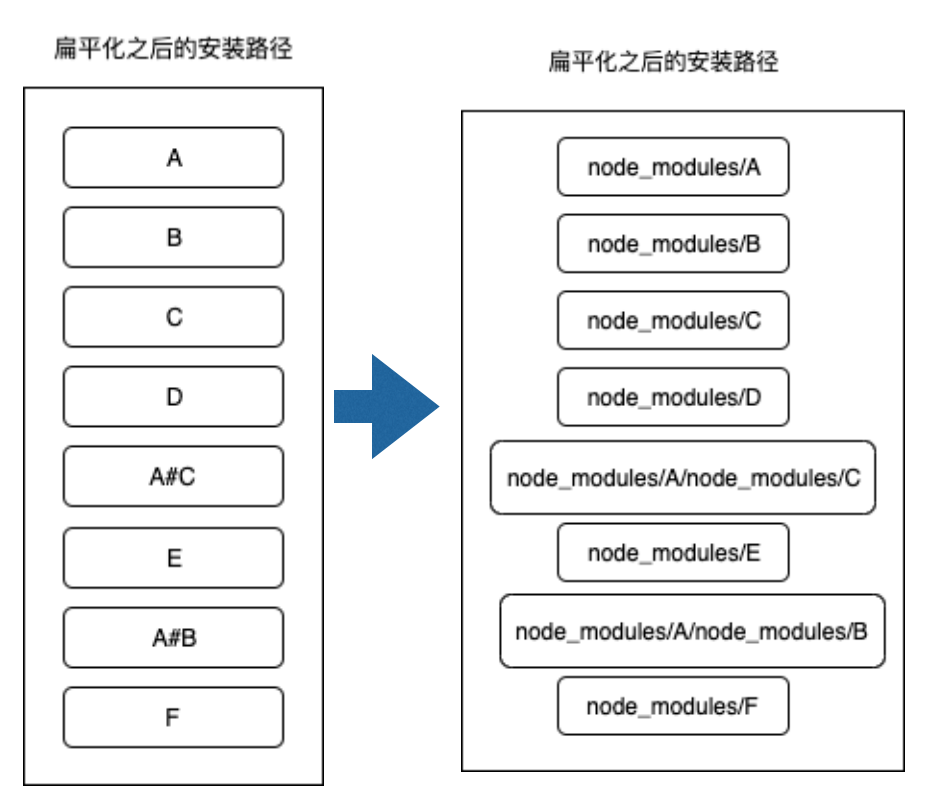
然后按照我们上面的第3步,使用localeCompare本地排序规则进行排序,结果为:
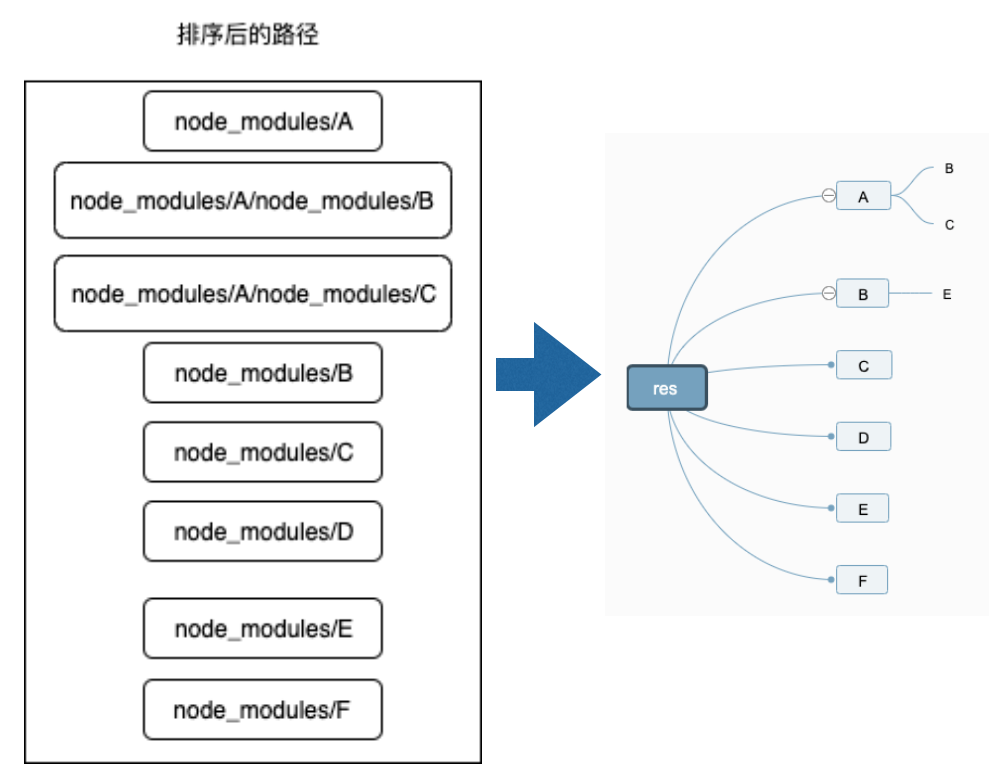
小结
安装过程到这里就结束啦,现在回过头来看看「工作中常见的问题 」,是否还有疑惑呢?下面给出答案哈,如果还有疑惑欢迎留言讨论~
安装依赖出现问题时,删除yarn.lock,再重新install,这样操作有风险吗?
「有风险」开发时,我把所有依赖都安装到dependence或devDependence中,会有问题吗?
「普通工程中,只是不规范,不会导致问题;如果是提供给其他项目的依赖包,会有问题」项目和这个项目的某个依赖都依赖了同一个包,这个包会被多次安装、重复打包吗? 「看版本范围是否在一个范围内,同一个版本范围,不会重复,否则会」 开发同一个项目,有的同学使用yarn,有的同学使用npm,有问题吗?
「有,锁文件不同,可能导致最终安装版本不一致」
❤️ 看完三件事
点个「在看」,让更多的人也能看到这篇内容(喜欢不点在看,都是耍流氓 -_-)
关注我的官网 https://muyiy.cn,让我们成为长期关系
关注公众号「高级前端进阶」,公众号后台回复「面试题」 送你高级前端面试题,回复「加群」加入面试互助交流群