
【js逆向爬虫】-有道翻译js逆向实战
最近在蚂蚁老师群里js逆向的话题比较火热,各位大佬都在研究,自己又对这方面比较好奇,学习了一点视频课程,找一个简单点的网站我也来练练手。
网页分析

打开网页,随意输入几个单词,发现网页不是静态加载的。不着急,我们换方式,抓包。
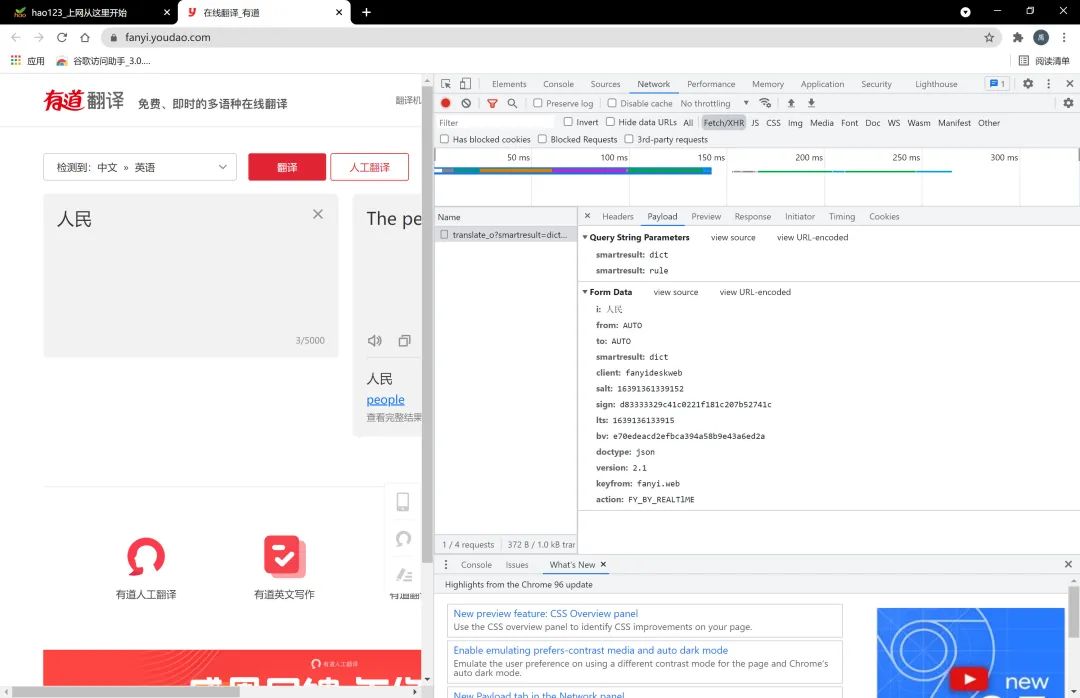
通过查找,我们在Payload里面发现了输入的需要翻译的信息,比如我这里的“人民”,然后在Preview里面发现了返回的翻译信息,这里我没有上传图片,接着继续看Headers里面的数据,通过观察,会发现网页是post请求,大概的思路就已经出来了,先尝试写一下。
初步代码实现
post请求需要携带的参数我这里就不再说明了,headers,cookies,data等等基本上都会添加。这里需要说明的一点,如参数补全后还报错的话,重新抓取请求,我就是在这里卡了好久,后来换了下面的“生活”一词。
import requests
url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
"Cookie": "OUTFOX_SEARCH_USER_ID=2030291441@10.169.0.102; JSESSIONID=aaaL9cZGnEYP5anryhK2x; OUTFOX_SEARCH_USER_ID_NCOO=624916323.622491; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcbn5lLEK4FC4F7BhK2x; ___rl__test__cookies=1639138497978",
"Referer": "https://fanyi.youdao.com",
"Content-Length": "252"
}
Payload = {
"i":"生活",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "16391384979865",
"sign": "b1e30cb6bb14501ea6827a83a554dcae",
"lts": "1639138497986",
"bv": "e70edeacd2efbca394a58b9e43a6ed2a",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
res = requests.post(url, headers=headers, data=Payload)
print(res.status_code)
print(res.text)
第一步基本上就成功了,看一下返回后的结果:
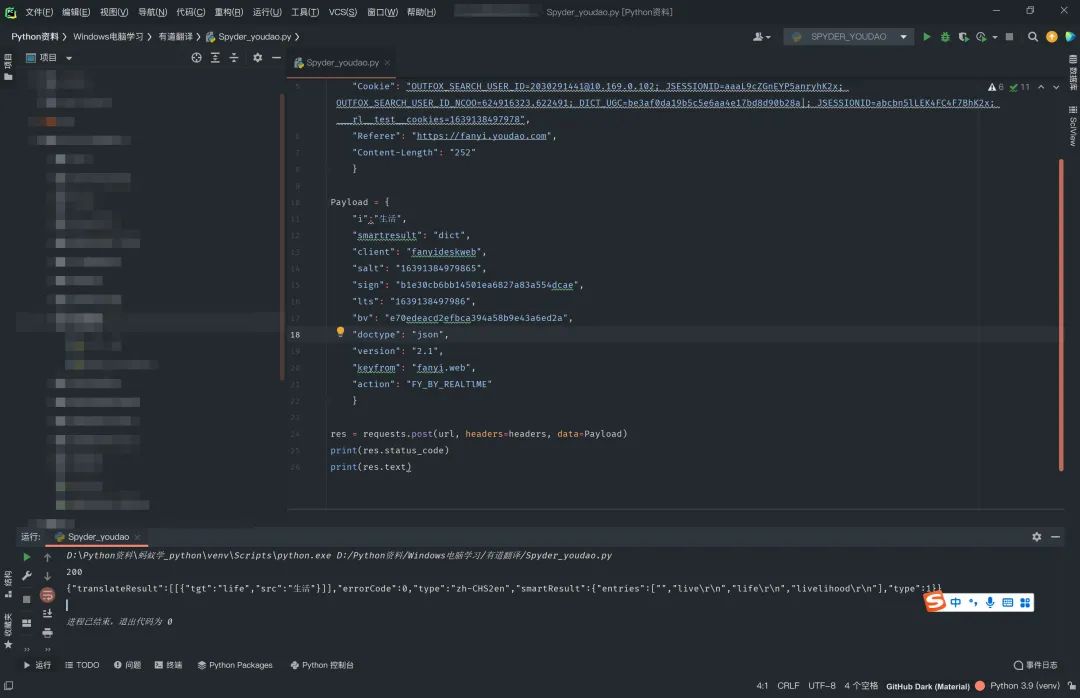
可是当我们想更换一个单词的时候,系统又会报错,比如,我这里换了太阳:

那怎么办呢?我们开始第二步,也就是js逆向
逆向查找参数
通过对上面的代码进行分析我们可以看出,"salt"、"sign"、"lts"、"bv"这四个参数不清楚怎么回事,那就需要打开Initiator下面的js代码去一一查找,定位。
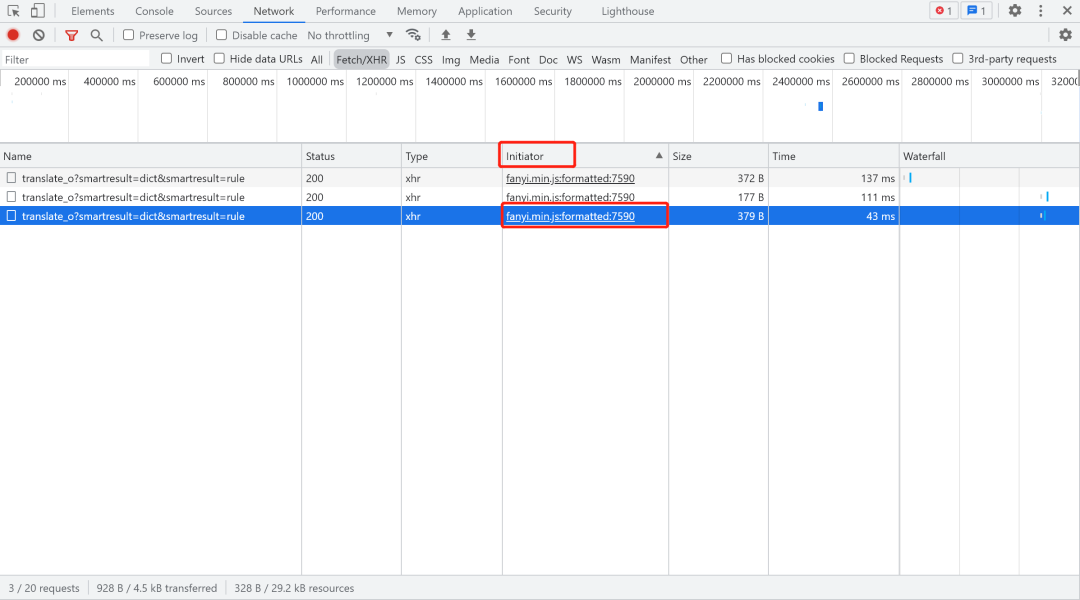
打开后,按ctrl+f搜索,比如我这里搜索的第一个参数“salt”,这里一共12,通过观察找到这一个:
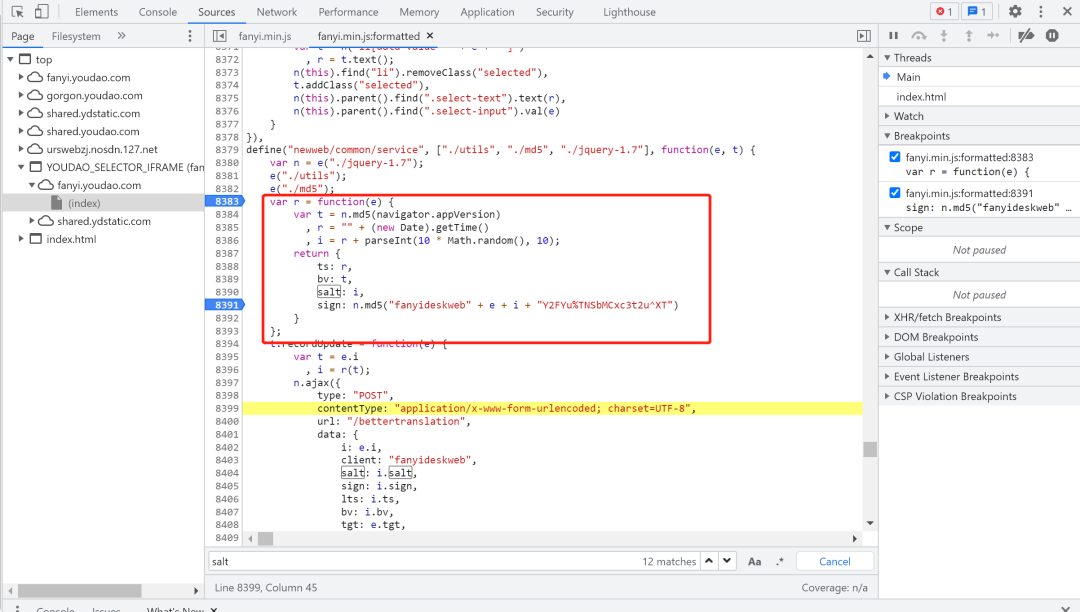
然后将需要的代码复制到Console,回车运行查找规律。比如我这里salt: i,然后i = r + parseInt(10 * Math.random(), 10),r = "" + (new Date).getTime(),通过在console运行后发现,“parseInt(10 * Math.random(), 10)”的意思是随机生成一个0-9的随机数;(new Date).getTime()是当前的一个时间,也叫时间戳。再观察又发现ts: r,bv: t,t = n.md5(navigator.appVersion),运行后得知,t就是我们在发起请求时的 "User-Agent"

那么我们开始代码实现:
先搞定ts
import time
r = time.time()
r = int(r*1000)
print(r)
>>>1639141944732
可以看到ts也就是上面的r和Payload里面的“lts”已经搞定。
再搞定salt
先来生成parseInt(10 * Math.random(), 10)的随机数:
import random
s = random.randint(0,10)
print(s)
再来实现i = r + parseInt(10 * Math.random(), 10):
import time
import random
r = time.time()
r = int(r*1000)
s = random.randint(0,10)
i = r+s
print(i)
至此,我们已经拿到了三个参数,代码也可以改写一下了:
import requests
import time
import random
url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
"Cookie": "OUTFOX_SEARCH_USER_ID=2030291441@10.169.0.102; JSESSIONID=aaaL9cZGnEYP5anryhK2x; OUTFOX_SEARCH_USER_ID_NCOO=624916323.622491; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcbn5lLEK4FC4F7BhK2x; ___rl__test__cookies=1639138497978",
"Referer": "https://fanyi.youdao.com",
"Content-Length": "252"
}
#获取时间戳
r = time.time()
r = int(r*1000)
#获取salt
s = random.randint(0,10)
i = r+s
Payload = {
"i":"太阳",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": i,
"sign": "b1e30cb6bb14501ea6827a83a554dcae",
"lts": r,
"bv": "e70edeacd2efbca394a58b9e43a6ed2a",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
res = requests.post(url, headers=headers, data=Payload)
print(res.status_code)
print(res.text)
最后搞定sign
通过观察可以发现:sign: n.md5("fanyideskweb" + e + i + "Y2FYu%TNSbMCxc3t2u^XT"),能得到的信息有:1.这个是md5加密,2."fanyideskweb"是固定的,3.i前面已经生成了,4.e不知道是什么,5."Y2FYu%TNSbMCxc3t2u^XT"这一部分是固定的。
通过断点调试后发现,e就是我们输入的文字。
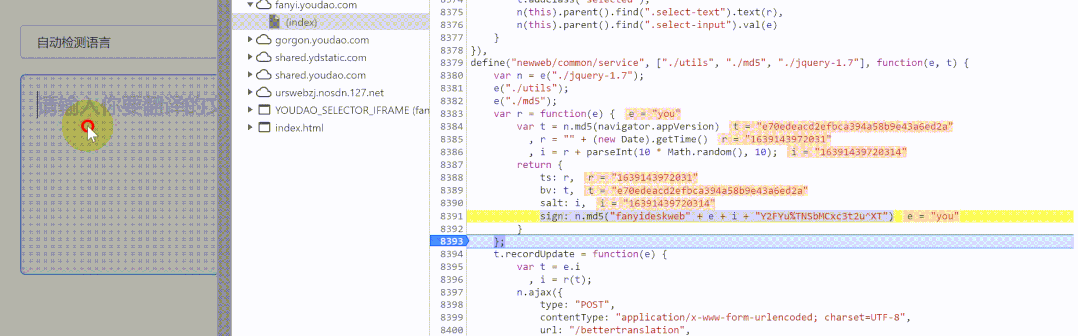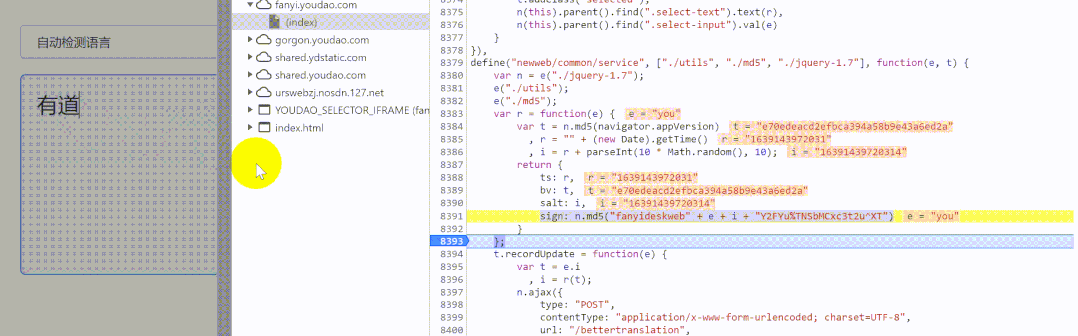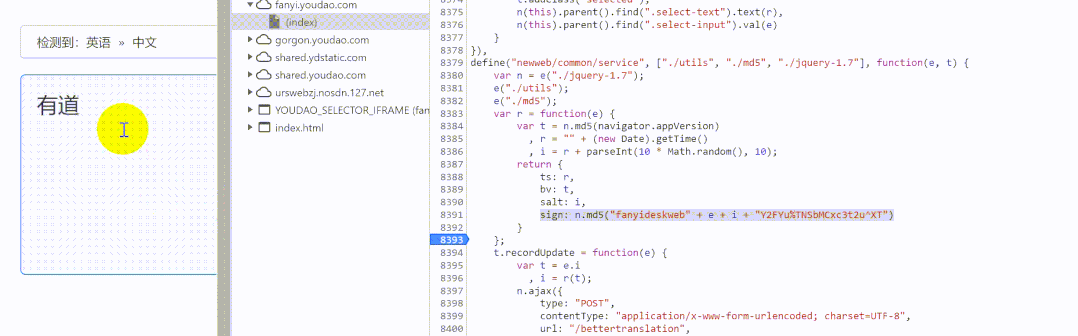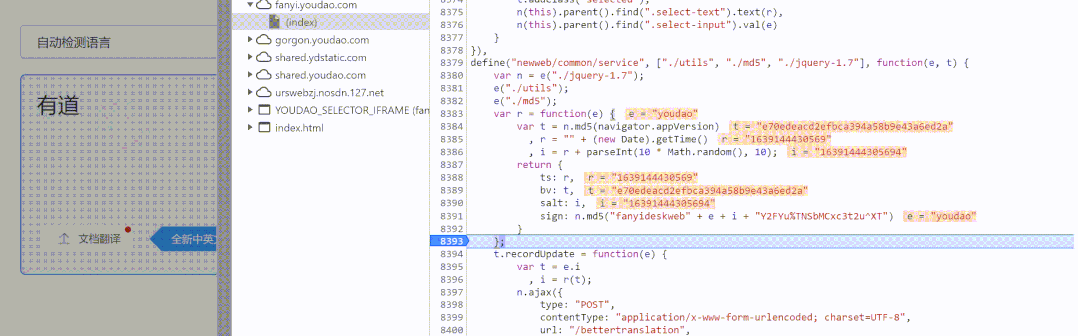
最后一步,百度md5怎么加密,这里我感觉是最难的地方,说实话这一块我也不懂,百度的结果如下:
from hashlib import md5
string = "**********"
m = md5()
m.update(string.encode())
sign = m.hexdigest()
改写代码
import requests
import time
import random
from hashlib import md5
import json
url = "https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36",
"Cookie": "OUTFOX_SEARCH_USER_ID=2030291441@10.169.0.102; JSESSIONID=aaaL9cZGnEYP5anryhK2x; OUTFOX_SEARCH_USER_ID_NCOO=624916323.622491; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abcbn5lLEK4FC4F7BhK2x; ___rl__test__cookies=1639138497978",
"Referer": "https://fanyi.youdao.com",
"Content-Length": "252"
}
def get_param():
lts = int(time.time()*1000) #获取时间戳lts
random_num = random.randint(0,10)
salt = lts+random_num #获取salt
word = input("请输入需要翻译的单词:")
string = "fanyideskweb" + word + str(salt) + "Y2FYu%TNSbMCxc3t2u^XT"
m = md5()
m.update(string.encode())
sign = m.hexdigest() #获取md5加密的sign
return word,salt,lts,sign
word,salt,lts,sign = get_param()
Payload = {
"i":word,
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"lts": lts,
"bv": "e70edeacd2efbca394a58b9e43a6ed2a",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
res = requests.post(url, headers=headers, data=Payload)
# print(res.text)
data_json = json.loads(res.text)
result = data_json['translateResult'][0][0]
tgt = result['tgt']
src = result['src']
print(f"需要翻译的单词为:{tgt}")
print(f"翻译的结果为:{src}")
成果展示
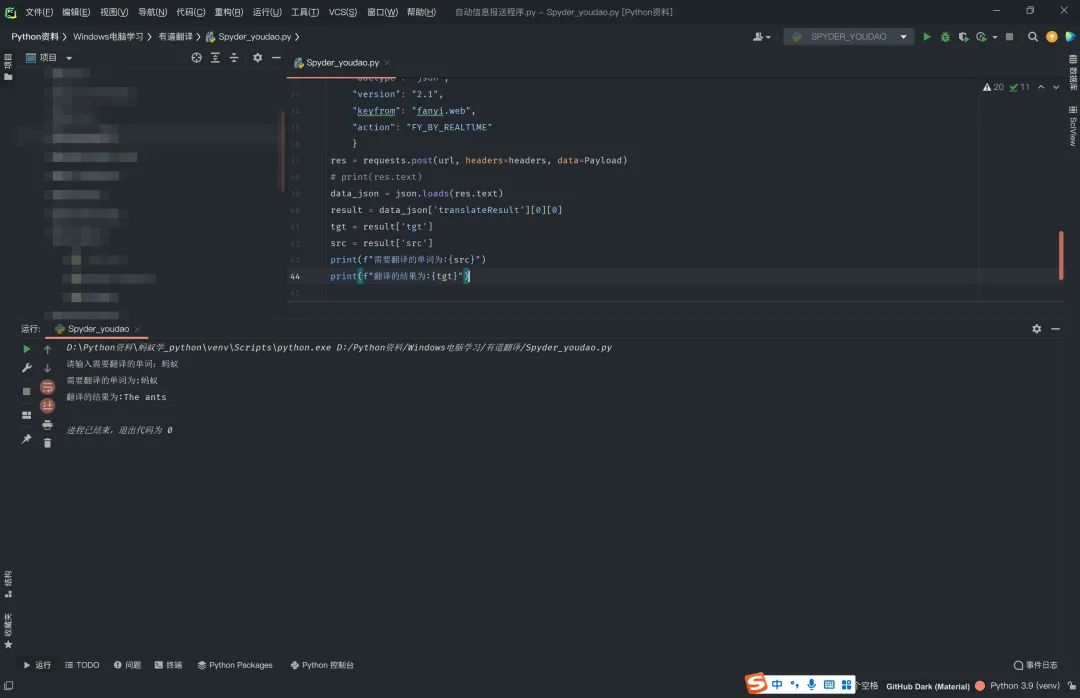
最后,推荐蚂蚁老师的Python爬虫数据分析课程: