
分布式事务中的时间戳怎么搞?
点击关注公众号,Java干货及时送达
作者:Eric Fu
链接:https://ericfu.me/timestamp-in-distributed-trans/
本文聊一聊时间戳的前世今生,为了把讨论集中在主题上,假设读者已经对数据库的 MVCC、2PC、一致性、隔离级别等概念有个基本的了解。
为什么需要时间戳?
自从 MVCC 被发明出来之后,那个时代的几乎所有数据库都抛弃(或部分抛弃)了两阶段锁的并发控制方法,原因无它——性能太差了。当分布式数据库逐渐兴起时,设计者们几乎都选择 MVCC 作为并发控制方案。
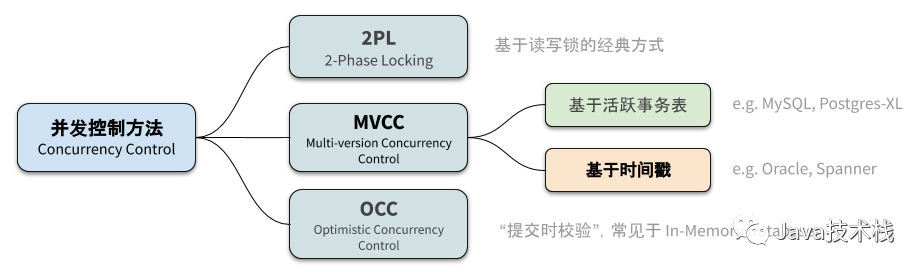
MVCC 的全称是多版本并发控制(Multi-Version Concurrency Control),这个名字似乎暗示我们一定会有个版本号(时间戳)存在。然而事实上,时间戳还真不是必须的。MySQL 的 ReadView 实现就是基于事务 ID 大小以及活跃事务列表进行可见性判断。
事务 ID 在事务开启时分配,体现了事务 begin 的顺序;提交时间戳 commit_ts 在事务提交时分配,体现了事务 commit 的顺序。
分布式数据库 Postgres-XL 也用了同样的方案,只是将这套逻辑放在全局事务管理器(GTM)中,由 GTM 集中式地维护集群中所有事务状态,并为各个事务生成它们的 Snapshot。这种中心化的设计很容易出现性能瓶颈,制约了集群的扩展性。
另一套方案就是引入时间戳,只要比较数据的写入时间戳(即写入该数据的事务的提交时间戳)和 Snapshot 的读时间戳,即可判断出可见性。在单机数据库中产生时间戳很简单,用原子自增的整数就能以很高的性能分配时间戳。Oracle 用的就是这个方案。

MVCC 原理示意:比较 Snapshot 读取时间戳和数据上的写入时间戳,其中最大但不超过读时间戳的版本,即为可见的版本
而在分布式数据库中,最直接的替代方案是引入一个集中式的分配器,称为 TSO(Timestamp Oracle,此 Oracle 非彼 Oracle),由 TSO 提供单调递增的时间戳。TSO 看似还是个单点,但是考虑到各个节点取时间戳可以批量(一次取 K 个),即便集群的负载很高,对 TSO 也不会造成很大的压力。TiDB 用的就是这套方案。
MVCC 和 Snapshot Isolation 有什么区别?前者是侧重于描述数据库的并发控制实现,后者从隔离级别的角度定义了一种语义。本文中我们不区分这两个概念。
可线性化
可线性化(linearizable)或线性一致性意味着操作的时序和(外部观察者所看到的)物理时间一致,因此有时也称为外部一致性。具体来说,可线性化假设读写操作都需要执行一段时间,但是在这段时间内必然能找出一个时间点,对应操作真正“发生”的时刻。
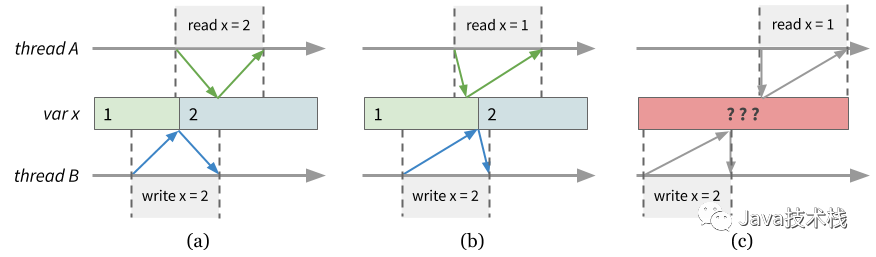
线性一致性的解释。其中 (a)、(b) 满足线性一致性,因为如图所示的时间轴即能解释线程 A、B 的行为;(c) 是不允许的,无论如何 A 都应当看到 B 的写入
注意不要把一致性和隔离级别混为一谈,这完全是不同维度的概念。理想情况下的数据库应该满足 strict serializability,即隔离级别做到 serializable、一致性做到 linearizabile。本文主要关注一致性。
TSO 时间戳能够提供线性一致性保证。完整的证明超出了本文的范畴,这里只说说直觉的解释:用于判断可见性的 snapshot_ts 和 commit_ts 都是来自于集群中唯一的 TSO,而 TSO 作为一个单点,能够确保时间戳的顺序关系与分配时间戳的物理时序一致。
可线性化是一个极好的特性,用户完全不用考虑一致性方面的问题,但是代价是必须引入一个中心化的 TSO。我们后边会看到,想在去中心化的情况下保持可线性化是极为困难的。
TrueTime
Google Spanner 是一个定位于全球部署的数据库。如果用 TSO 方案则需要横跨半个地球拿时间戳,这个延迟可能就奔着秒级去了。但是 Google 的工程师认为 linearizable 是必不可少的,这就有了 TrueTime。
TrueTime 利用原子钟和 GPS 实现了时间戳的去中心化。但是原子钟和 GPS 提供的时间也是有误差的,在 Spanner 中这个误差范围 εε 被设定为 7ms。换句话说,如果两个时间戳相差小于 2ε2ε ,我们就无法确定它们的物理先后顺序,称之为“不确定性窗口”。
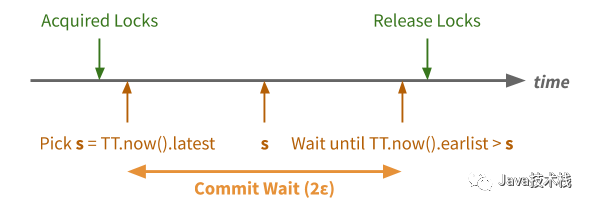
Spanner 对此的处理方法也很简单——等待不确定性窗口时间过去。
在事务提交过程中 Spanner 会做额外的等待,直到满足 TT.now()−Tstart>2εTT.now()−Tstart>2ε,然后才将提交成功返回给客户端。在此之后,无论从哪里发起的读请求必然会拿到一个更大的时间戳,因而必然能读到刚刚的写入。
Lamport 时钟与 HLC
Lamport 时钟是最简单的逻辑时钟(Logical Clock)实现,它用一个整数表示时间,记录事件的先后/因果关系(causality):如果 A 事件导致了 B 事件,那么 A 的时间戳一定小于 B。
当分布式系统的节点间传递消息时,消息会附带发送者的时间戳,而接收方总是用消息中的时间戳“推高”本地时间戳:Tlocal=max(Tmsg,Tlocal)+1Tlocal=max(Tmsg,Tlocal)+1。
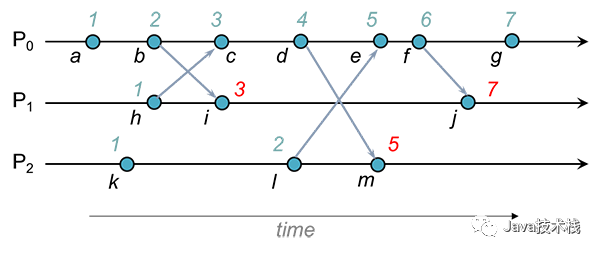
Lamport Clock 只是个从 0 开始增长的整数,为了让它更有意义,我们可以在它的高位存放物理时间戳、低位存放逻辑时间戳,当物理时间戳增加时逻辑位清零,这就是 HLC(Hybrid Logical Clock)。很显然,从大小关系的角度看,HLC 和 LC 并没有什么不同。

HLC/LC 也可以用在分布式事务中,我们将时间戳附加到所有事务相关的 RPC 中,也就是 Begin、Prepare 和 Commit 这几个消息中:
Begin:取本地时间戳 local_ts 作为事务读时间戳 snapshot_ts Snapshot Read: 用 snapshot_ts 读取其他节点数据(MVCC) Prepare:收集所有事务参与者的当前时间戳,记作 prepare_ts Commit:计算推高后的本地时间戳,即 commit_ts = max{ prepare_ts } + 1
HLC/LC 并不满足线性一致性。我们可以构造出这样的场景,事务 A 和事务 B 发生在不相交的节点上,比如事务 TATA 位于节点 1、事务 TBTB 位于节点 2,那么这种情况下 TATA、TBTB 的时间戳是彼此独立产生的,二者之前没有任何先后关系保证。具体来说,假设 TATA 物理上先于 TBTB 提交,但是节点 2 上发起的 TBTB 的 snapshot_ts 可能滞后(偏小),因此无法读到 TATA 写入的数据。
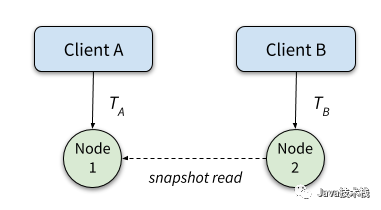
T1: w(C1)
T1: commit
T2: r(C2) (not visible! assuming T2.snapshot_ts < T1.commit_ts)
HLC/LC 满足因果一致性(Causal Consistency)或 Session 一致性,然而对于数据库来说这并不足以满足用户需求。想象一个场景:应用程序中使用了连接池,它有可能先用 Session A 提交事务 TATA(用户注册),再用 Session B 进行事务 TBTB(下订单),但是 TBTB 却查不到下单用户的记录。
如果连接池的例子不能说服你,可以想象一下:微服务节点 A 负责用户注册,之后它向微服务节点 B 发送消息,通知节点 B 进行下订单,此时 B 却查不到这条用户的记录。根本问题在于应用无法感知数据库的时间戳,如果应用也能向数据库一样在 RPC 调用时传递时间戳,或许因果一致性就够用了。
有限误差的 HLC
上个小节中介绍的 HLC 物理时间戳部分仅供观赏,并没有发挥实质性的作用。CockroachDB 创造性地引入了 NTP 对时协议。NTP 的精度当然远远不如原子钟,误差大约在 100ms 到 250ms 之间,如此大的误差下如果再套用 TrueTime 的做法,事务延迟会高到无法接受。
CockroachDB 要求所有数据库节点间的时钟偏移不能超过 250ms,后台线程会不断探测节点间的时钟偏移量,一旦超过阈值立即自杀。通过这种方式,节点间的时钟偏移量被限制在一个有限的范围内,即所谓的半同步时钟(semi-synchronized clocks)。
下面是最关键的部分:进行 Snapshot Read 的过程中,一旦遇到 commit_ts 位于不确定性窗口 [snapshot_ts, snapshot_ts + max_clock_shift] 内的数据,则意味着无法确定这条记录到底是否可见,这时将会重启整个事务(并等待 max_clock_shift 过去),取一个新的 snapshot_ts 进行读取。
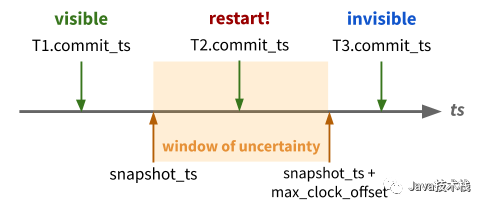
有了这套额外的机制,上一节中的“写后读”场景下,可以保证读事务 TBTB 一定能读到 TATA 的写入。具体来说,由于 TATA 提交先于 TBTB 发起,TATA 的写入时间戳一定小于 B.snapshot_ts + max_clock_shift,因此要么读到可见的结果(A.commit_ts < B.snapshot_ts),要么事务重启、用新的时间戳读到可见的结果。
那么,CockroachDB 是否满足可线性化呢?答案是否定的。Jepsen 的一篇测试报告中提到以下这个“双写”场景(其中,数据 C1、C2 位于不同节点上):
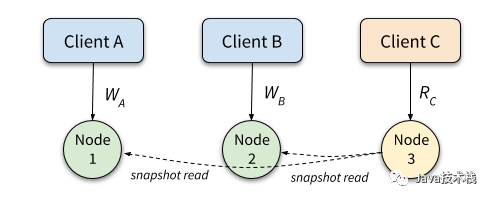
T3: r(C1) (not found)
T1: w(C1)
T1: commit
T2: w(C2)
T2: commit (assuming T2.commit_ts < T3.snapshot_ts due to clock shift)
T3: r(C2) (found)
T3: commit
虽然 T1 先于 T2 写入,但是 T3 却看到了 T2 而没有看到 T1,此时事务的表现等价于这样的串行执行序列:T2 -> T3 -> T1(因此符合可串行化),与物理顺序 T1 -> T2 不同,违反了可线性化。归根结底是因为 T1、T2 两个事务的时间戳由各自的节点独立产生,无法保证先后关系,而 Read Restart 机制只能防止数据存在的情况,对于这种尚不存在的数据(C1)就无能为力了。
Jepsen 对此总结为:CockroachDB 仅对单行事务保证可线性化,对于涉及多行的事务则无法保证。这样的一致性级别是否能满足业务需要呢?这个问题就留给读者判断吧。
结合 TSO 与 HLC
最近看到 TiDB 的 Async Commit 设计文档 引起了我的兴趣。Async Commit 的设计动机是为了降低提交延迟,在 TiDB 原本的 Percolator 2PC 实现中,需要经过以下 4 个步骤:
Prewrite:将 buffer 的修改写入 TiKV 中 从 TSO 获取提交时间戳 commit_ts Commit Primary Key Commit 其他 Key(异步进行)
为了降低提交延迟,我们希望将第 3 步也异步化。但是第 2 步中获取的 commit_ts 需要由第 3 步来保证持久化,否则一旦协调者在 2、3 步之间宕机,事务恢复时就不知道用什么 commit_ts 继续提交(roll forward)。为了避开这个麻烦的问题,设计文档对 TSO 时间戳模型的事务提交部分做了修改,引入 HLC 的提交方法:
Prewrite
TiDB 向各参与事务的 TiKV 节点发出 Prewrite 请求 TiKV 持久化 Prewrite 的数据以及 min_commit_ts,其中 min_commit_ts = 本地最大时间戳 max_ts TiKV 返回 Prewrite 成功消息,包含刚刚的 min_commit_ts Finalize
(异步):计算 commit_ts = max{ min_commit_ts },用该时间戳进行提交
Commit Primary Key Commit 其他 Key
上述流程和 HLC 提交流程基本是一样的。注意,事务开始时仍然是从 TSO 获取 snapshot_ts,这一点保持原状。
我们尝试代入上一节的“双写”场景发现:由于依赖 TSO 提供的 snapshot_ts,T1、T2 的时间戳依然能保证正确的先后关系,但是只要稍作修改,即可构造出失败场景(这里假设 snapshot_ts 在事务 begin 时获取):
T1: begin T2: begin T3: begin (concurrently)
T1: w(C1)
T1: commit (assuming commit_ts = 105)
T2: w(C2)
T2: commit (assuming commit_ts = 103)
T3: r(C1) (not found)
T3: r(C2) (found)
T3: commit
虽然 T1 先于 T2 写入,但 T2 的提交时间戳却小于 T1,于是,并发的读事务 T3 看到了 T2 而没有看到 T1,违反了可线性化。根本原因和 CockroachDB 一样:T1、T2 两个事务的提交时间戳由各自节点计算得出,无法确保先后关系。
Async Commit Done Right
上个小节给出的 Async Commit 方案破坏了原本 TSO 时间戳的线性一致性(虽然仅仅是个非常边缘的场景)。这里特别感谢 @Zhifeng Hu 的提醒,在 #8589 中给出了一个巧妙的解决方案:引入 prewrite_ts 时间戳,即可让并发事务的 commit_ts 重新变得有序。完整流程如下,注意 Prewrite 的第 1、2 步:
Prewrite
TiDB 从 TSO 获取一个 prewrite_ts,附带在其中一个 Prewrite 请求上发送给 TiKV TiKV 用 prewrite_ts(如果收到的话)推高本地最大时间戳 max_ts TiKV 持久化 Prewrite 的数据以及 min_commit_ts = max_ts TiKV 返回 Prewrite 成功消息,包含刚刚的 min_commit_ts Finalize
(异步):计算 commit_ts = max{ min_commit_ts },用该时间戳进行提交
Commit Primary Key Commit 其他 Key
对应到上面的用例中,现在 T1、T2 两个事务的提交时间戳不再是独立计算,依靠 TSO 提供的 prewrite_ts 可以构建出 T1、T2 的正确顺序:T2.commit_ts >= T2.prewrite_ts > T1.commit_ts,从而避免了上述异常。
更进一步,该方案能够满足线性一致性。这里只给一个直觉的解释:我们将 TSO 看作是外部物理时间,依靠 prewrite_ts 可以保证 commit_ts 的取值位于 commit 请求开始之后,而通过本地 max_ts 计算出的 commit_ts 一定在 commit 请求结束之前,故 commit_ts 取值落在执行提交请求的时间范围内,满足线性一致性。
总结
上述已知的时间戳方案中,仅有 TSO 和 TrueTime 能够保证线性一致性; Logical Clock 方案仅能保证 Session 一致性; Cockroach 的 HLC 方案仅能保证行级线性一致性,不保证多行事务的线性一致性; TiDB Async Commit 通过引入 Prewrite 时间戳保持了外部一致性;但如果去掉 Prewrite 时间戳、使用 HLC 的提交方式,则不保证多行的并发事务的线性一致性。
References
https://en.wikipedia.org/wiki/Lamport_timestamp https://www.slideshare.net/josemariafuster1/spanner-osdi2012-39872703 https://jepsen.io/analyses/cockroachdb-beta-20160829 https://www.cockroachlabs.com/blog/living-without-atomic-clocks/) https://sergeiturukin.com/2017/06/29/eventual-consistency.html https://github.com/tikv/sig-transaction/blob/master/design/async-commit/initial-design.md https://github.com/tikv/tikv/issues/8589







关注Java技术栈看更多干货
