
CVPR 2022 | 16万视频对、28万对片段,蚂蚁开源视频侵权检测超大数据集
作者:蚂蚁集团
该研究提出了目前最大规模(超过现有其他数据集 2 个数量级规模)的视频侵权定位数据集VCSL,并提出全新的视频片段拷贝检测的评价指标。相关研究入选CVPR 2022。
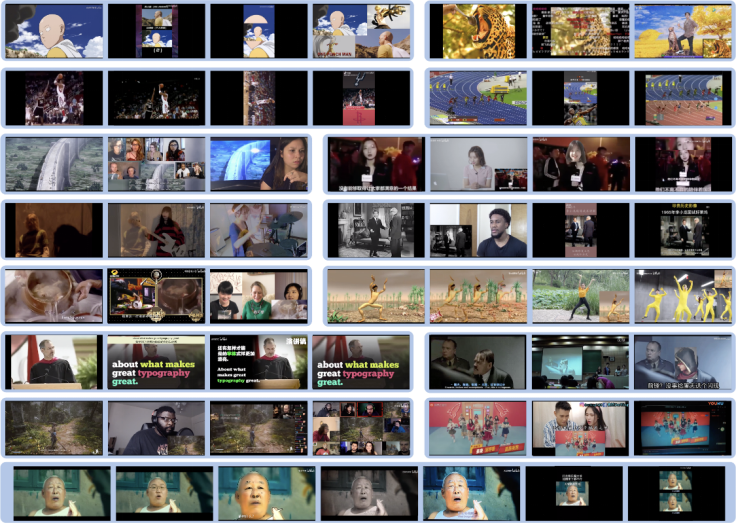
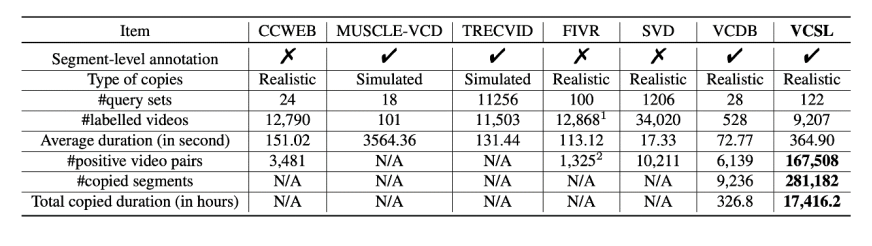
数据集,目前学术界已经开源的数据集大部分都是只有视频级别的标注(Trecvid[1], SVD[2], FIVR[3]),即视频对之间只标注了是否侵权,而并未标注两个视频之间实际侵权的时间片段(即侵权起始时间位置和结束时间位置)。目前开源的拥有片段级别标注的数据集仅有 2014 年 ECCV 上开源的 VCDB 数据集[4],但这个数据集规模比较小,仅有 6k 对实际侵权的视频对,这也会在后面的章节进行介绍。
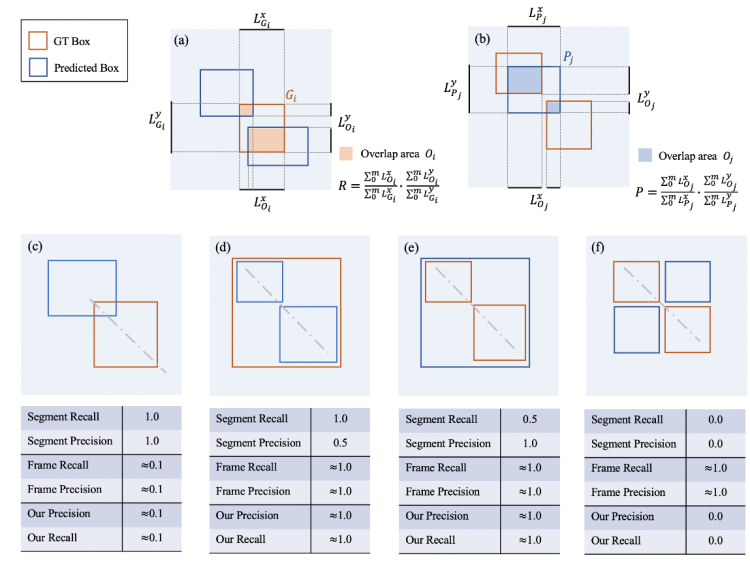
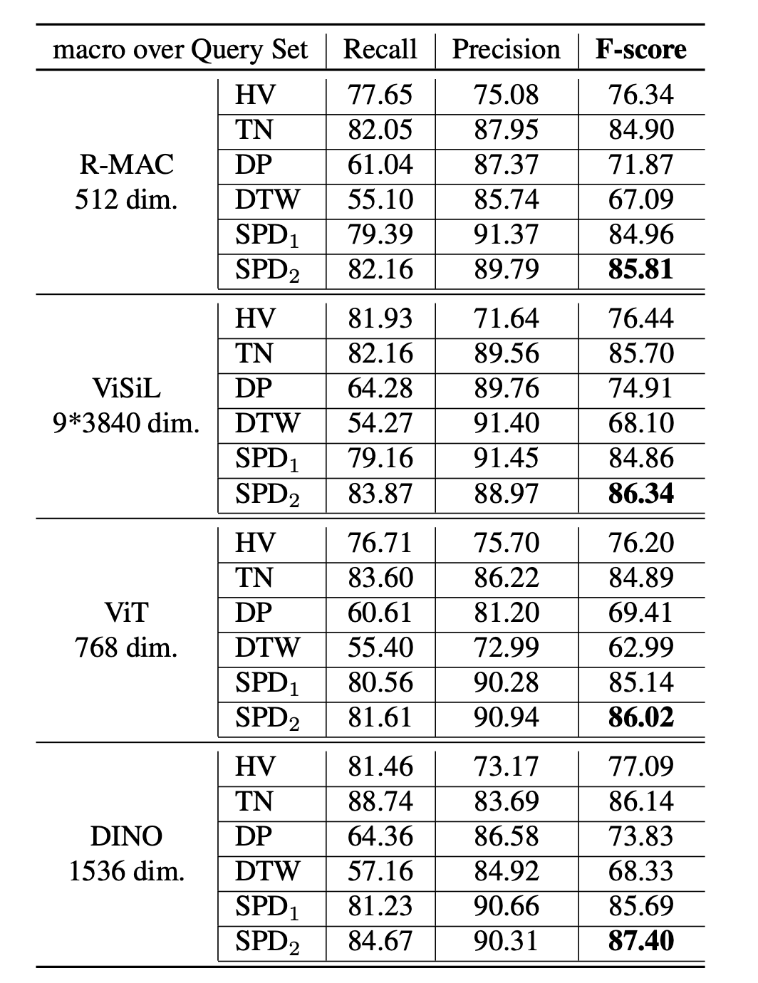
算法评价指标,在学术界中,视频级别的拷贝检测评价指标比较成熟,但是片段粒度的拷贝检测准确度的评价指标仍然存在着比较多的问题。之前 VCDB 论文中提出的评价指标在实际的实验测试中出现了一系列指标上的偏差以及应用上的问题。
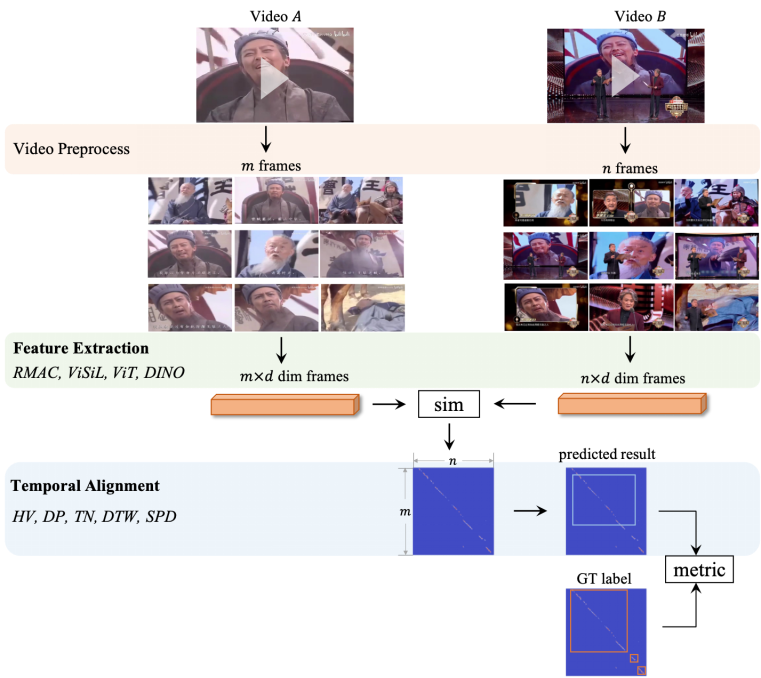
侵权定位算法,侵权定位算法,在这里侵权定位(Temporal Alignment)算法指的是在提取出两段视频的时序特征后,需要输出两段视频侵权的时间片段。大部分侵权定位的算法都是不开源的,因此学术界也无法形成一个完善的 benchmark,视频拷贝检测和侵权定位这个领域也相对较为停滞。
提出了目前最大规模(超过现有其他数据集 2 个数量级规模)的视频侵权定位数据集,包括了超过 16 万对侵权视频对,28 万对侵权片段,并且涵盖了大量的视频领域和视频时长。
提出了全新的视频片段拷贝检测的评价指标,该评价指标充分考虑到了视频拷贝检测这个任务的特殊性,并且在实际场景下体现出了更好的适应性。
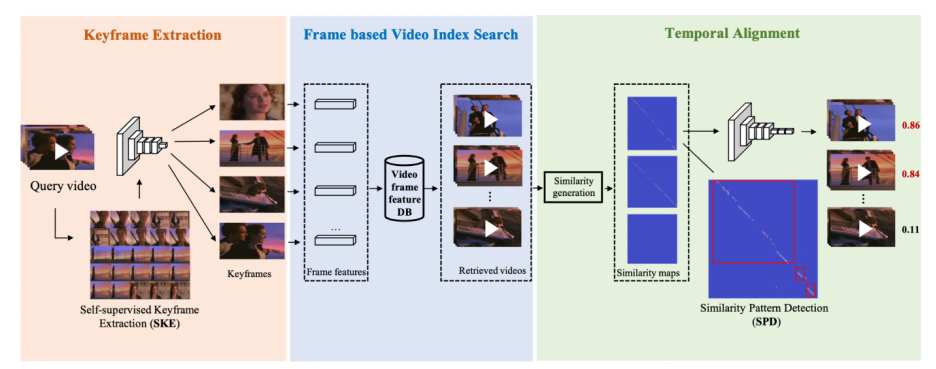
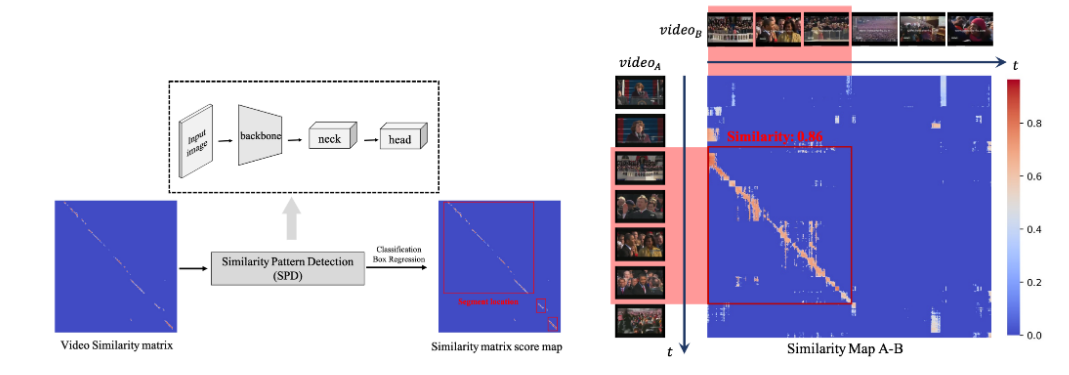
提出了关键帧和侵权定位端到端的模型 SSAN 并达到了现阶段最高指标,并且将现阶段学术界的常见侵权定位算法进行复现并且开源,形成了完善全面的视频侵权定位 benchmark。

CVPR 2022 VCSL 论文:https://arxiv.org/abs/2203.02654
VCSL 数据集和评测以及算法代码:https://github.com/alipay/VCSL
视频拷贝的类型必须要尽可能的全面,但是要避免过度变换使得侵权的视频基本不具备观赏性。
视频类型必须覆盖常见的视频种类,比如电影、电视剧、动画、体育等不同场景。
视频时长分布尽可能广泛,不要局限于只是短视频或者只是长视频。



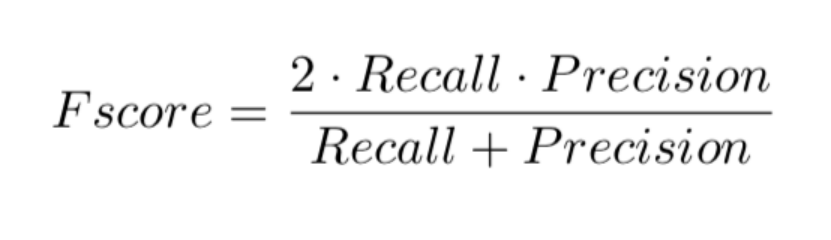
猜您喜欢:
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!附下载 |《TensorFlow 2.0 深度学习算法实战》