
基于大尺寸图像的小目标检测竞赛经验总结

极市导读
本文为作者参加目标检测比赛总结的数据分析,比赛思路、模型、Tricks以及分享的一些相关资料。附有详细的模型总结以及anchor的设置总结图。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
数据分析 比赛思路 模型 Tricks 很好的参考资料 总结
前言:作为一个没有计算资源,没有接触过目标检测的渣硕第一次参加2021广东工业大赛的比赛:
2021广东工业智造创新大赛-智能算法赛-天池大赛-阿里云天池
1、资源:租了一张2080ti(五百多租一周好贵啊,有资源的大佬可以一起组队参加其他比赛啊);
2、成绩:初赛 90/4432(进复赛啦),成绩一般,受制于资源以及后期单打独斗参加比赛。
3、最终方案:Cascade R-CNN, Backbone: ResNet-50, 在线切图策略训练,测试时使用分水岭算法去了一下黑边(很简单,很多tricks都没尝试,最简单的模型融合也没做,时间和资源都不够用啊。)
4、悄悄告诉大家,在github中搜tianchi defect detection即可搜到很多开源的冠军方案(我可真是个机灵鬼skr),同理,搜kaggle + 领域也能搜到很多方案。
https://github.com/search?q=tianchi+defect+detection
5、声明:第一次写文章以及接触目标检测,若有错误还请善意指正哈,感谢。
接下来讲讲思路以及分享我花了大量时间收集的资料(后面有XMIND总结,分享给大家),一句话概括这个任务:超大尺寸图像的极小目标检测
一、数据分析
数据集图像的尺寸是8192*6000,而目标object则特别小(不知道大家能不能找到可视化出来的红色bbox,注意:这张图一共有三个bbox)

训练集里面的一张图像以及其三个bbox
看不到就放大它吧

放大好几倍,截图出来的结果(还是那么小啊)
并且每张图的object特别少(即稀疏)
做一个统计:
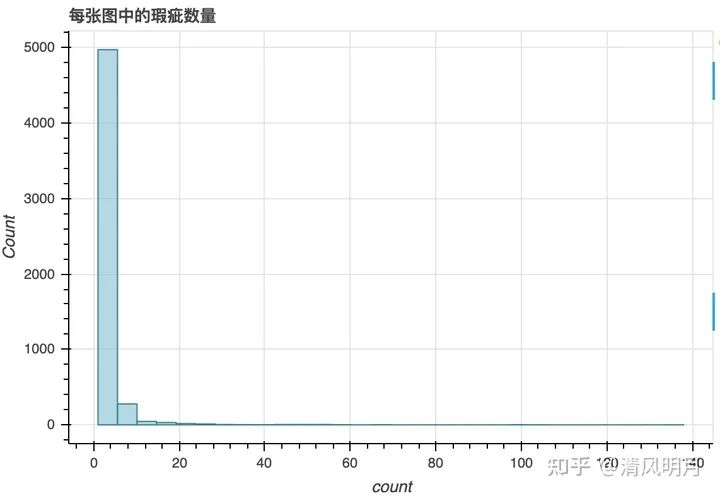
每张图的bbox的数量大部分集中在1-5个
看看bbox的面积大小吧:
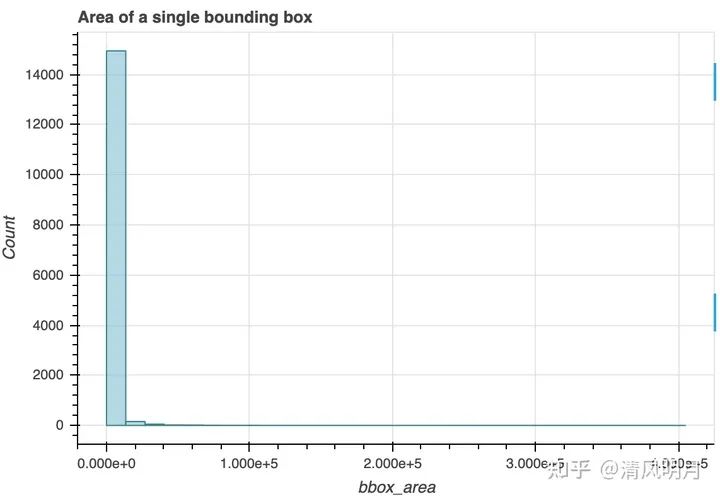
面积都很小啊
EDA的代码参考(ps,第一次看到EDA这三个字母我也是懵逼的,查了一下就是探索性数据分析(Exploratory Data Analysis,简称EDA),可能这样看起来更牛):
https://github.com/Kouin/TianCHI_guangdong/blob/main/eda.ipynb?spm=5176.12282029.0.0.26b21aaa83A2vL&file=eda.ipynb
二、比赛思路
对于这种超大尺寸图像的极小目标的检测,第一时间想到卫星图像中的目标检测,查了一下相关资料

图源《You Only Look Twice: Rapid Multi-Scale Object Detection InSatellite Imagery》,该论文以YOLT代称。
https://arxiv.org/pdf/1805.09512v1.pdf
YOLT算法笔记_AI之路-CSDN博客:
https://blog.csdn.net/u014380165/article/details/81556805
参考这篇论文的思路:将原输入图像切块,分别输入模型进行检测,然后再融合结果。
具体切块策略(记切图的大小是1333*800):
1、离线切图(先把训练集切图,然后再让网络训练);2、在线切图(训练时使用RandomCrop等)
因为就一块2080ti,想要做到每天都可以有两次结果提交,就先考虑的是离线切图策略。
离线切图的三种策略:
1.1、做滑动窗口切图:bbox面积特别小,又很稀疏,因此注意排除没有bbox的切图(这会引入很多正常的样本,注意这里,是个坑,后面再讲)。注意需要考虑是否做有overlap的滑动窗口切图。
1.2、遍历每个bbox,然后以该bbox作为切图中心坐标,做中心切图;如果其他bbox的坐标满足在该切图范围内,则加入该bbox。例如红色切图是以bbox#1作为中心的,但是bbox#2在红色切图范围内,则该红色切图则会有两个bbox。

对于中心切图策略,切图个数应该等于bbox的个数(手残党画的切图框示意)
中心切图可能存在的问题:对于bbox很密集的情况,有大量的几乎相差不大的切图(这个对于这个比赛影响不大)。
1.3、遍历每个bbox然后随机进行坐标偏移:考虑到中心切图引入了先验信息,即每个切图的中心一定会有一个bbox,因此引入随机性。具体的:遍历每个bbox,生成该bbox在切图坐标系中的随机坐标,例如生成的随机坐标是(0,0),该bbox则在切图的左上角,随机坐标是(1333,800),则该bbox在切图的右下角。注意:细节上还需要考虑该bbox的长宽,引入长宽后随机坐标会有一个进一步的约束(即切图大小和bbox的长宽来共同限制随机坐标)。同样的,对于随机切图策略,切图个数应该等于bbox的个数。和中心切图一样会包含在切图范围内的所有bbox。
两个细节需要考虑:1、切图要不要避免把bbox一分为几。滑动窗口切图策略加入overlap即可;其他两种策略肯定会包括每个完整的bbox(只要bbox的大小不超过切图设定的大小,即1333*800)。2、一般的backbone的下采样率(stride)是32,也就是到最后的feature map的一个特征点对应原图的32*32的区域;而大多数bbox的area基本都在100左右,最小的bbox面积为9。YOLT的做法是将stride变为16。
对于随机偏移的离线切图,可以做多次即可得到多倍的数据。离线切图的代码比较简单,我就不开源了,有需要私信我即可。
在线切图(我用的是mmdetection,在线切图的GPU利用率低啊,所以训练起来就比较慢):
2.1、使用RandomCrop
2.2、使用RandomCenterCropPad
这两个在线切图策略的不同请自己看mmdet的官方实现,提醒一个细节,RandomCrop有参数允许切图中不包括bbox,而RandomCenterCropPad不允许。我理解的是RandomCrop这种设置可以引入不包含bbox的负样本,避免最终结果的误检较多。
总结:离线切图相当于网络模型只能看到你给的这些数据了,在线切图每次都用random,数据更多样吧。在线切图的结果会比离线切图的结果好,就是训练慢了一点。
回复上面提及到的那个坑:离线切图均考虑的是切图中必须包含bbox才行,在线切图的RandomCenterCropPad得到的切图也是必须包括bbox。但是根据验证集上的可视化结果来看,误检比较多。因此加入没有bbox的切图进行训练是很有必要的。但是呢,细看官方实现RandomCenterCropPad和RandomCrop时(此时已经是比赛最后一天了),发现后者就只需要设置alllow__neg__positive = True即可,由于时间关系没有尝试该策略。
测试:因为计算资源受限,使用原图做inference显存不够啊(原图大概需要19G,而2080ti就11G),那没办法啊,把测试集也切图呗。比如切成3600*3600的,再把结果融合到原图的坐标系即可。
三、模型:
列出几个重要的
没有速度要求的话,通用就是Cascade R-CNN + Big backbone + FPN (Bbox长宽比例极端的话考虑加入DCN以及修改anchor的比例值,默认是0.5,1,2,比如可以修改为[0.2, 0.5, 1, 2, 5]),有速度要求就可以尝试YOLO系列(听说YOLO v5在kaggle的小麦检测上霸榜,可以看看他们的notebook),anchor的比例设置还是要多EDA分析得到一个合适的选择。 多尺度训练和测试,参考这个关于多尺度的解释
https://linzhenyuyuchen.github.io
https://posts.careerengine.us/p/5f94519f324fe34f723bcbed
fp16精度训练可以减少训练时间 伪标签策略(在kaggle小麦检测上可以提三个点),请参考如下
https://www.kaggle.com/nvnnghia/yolov5-pseudo-labeling
https://www.kaggle.com/nvnnghia/fasterrcnn-pseudo-labeling
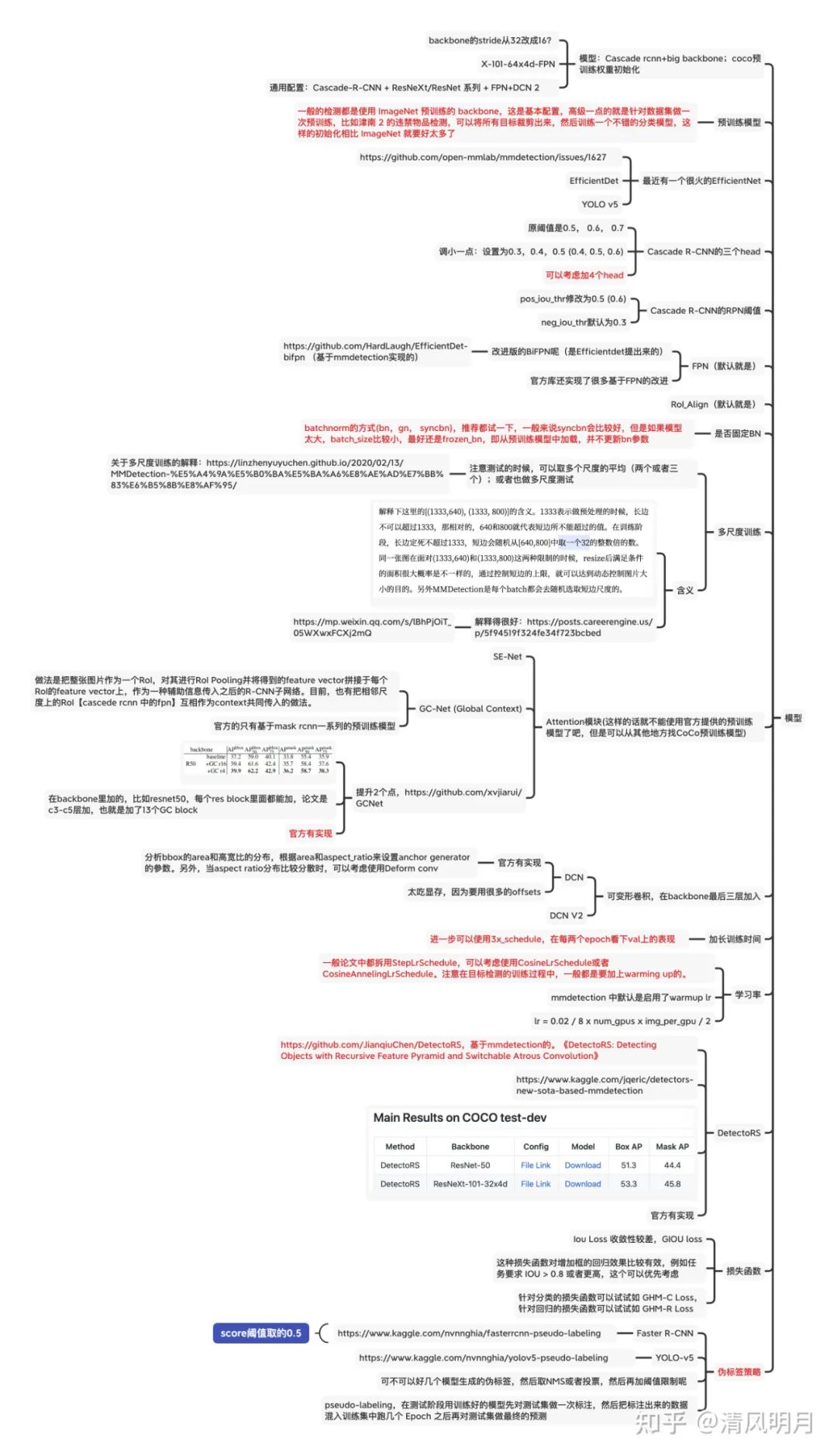
模型总结
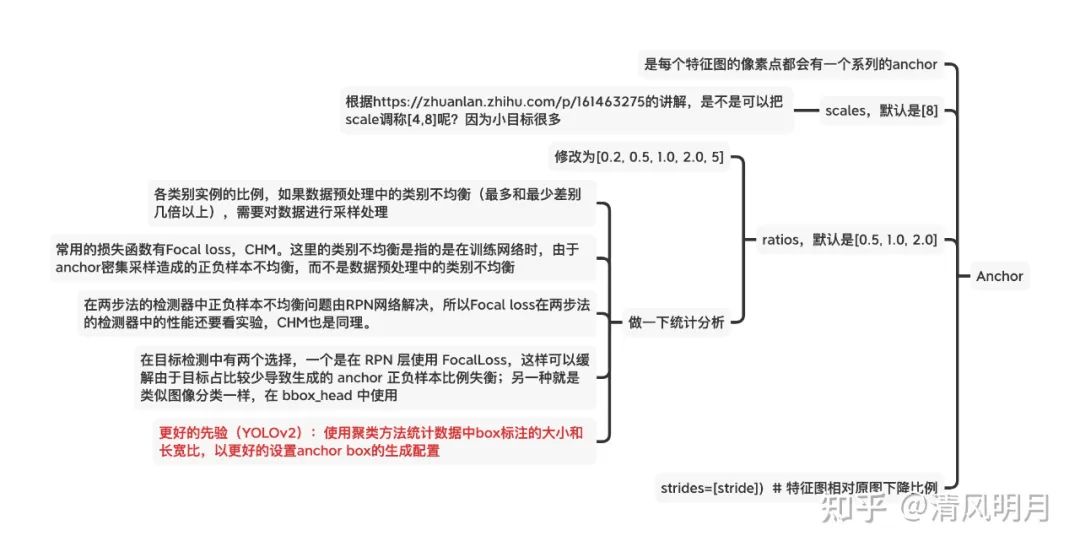
Anchor的设置总结
四、Tricks:
列出几个重要的:
WBF,TTA是涨点神器 比赛中无脑降低score的阈值会提升mAP,会有较多误检 两个重要的数据增强策略:Mixup以及填鸭式,下面是一个简单的实现
https://github.com/chuliuT/Tianchi_Fabric_defects_detection/blob/master/final_commit/Duck_inject.py

总结的一些tricks
很好的参考资料:
目标检测比赛中的 trick | 极市高质量视觉算法开发者社区(https://bbs.cvmart.net/topics/1500)
https://cloud.tencent.com/developer/article/1486440
http://spytensor.com/index.php/archives/53/?aazqne=u9pzg2&lktala=z15jb3
初识CV:目标检测比赛中的tricks(已更新更多代码解析)(https://zhuanlan.zhihu.com/p/102817180)
目标检测比赛提高mAP的方法 - 骏腾 - 博客园(https://www.cnblogs.com/zi-wang/p/12537034.html)
最后:
1、参加比赛可以学到很多东西,尤其是在不懂该领域时。这会让你去了解一些细节而不是单纯看paper时的囫囵吞枣。但是呢,现在detection有很多集成得很好的库了(例如mmdetection),很多细节也是只需要改一些参数,配置一些configs即可。若想细致的了解,还需要看具体的实现。
2、参加比赛很重要的一点是团队。作为队长你想要取得什么样的成绩,同时队友也有致力于这个目标的自驱动力,即设置一个合理的目标。如何激发每个成员的主观能动性是很重要的!作为队长,对于整个比赛的进度把控是很重要的,什么时候出一个baseline,基于baseline结果的各种可能细分为各种方向,每个成员在哪些方向进行探索(数据处理/模型等),定期的头脑碰撞很重要。
3、实验设置/结果记录,实验结果的管理也很重要,推荐使用一些共享文档来记录(例如腾讯文档,石墨文档)。学会利用身边的一切资源(能找到有卡的队友真是太幸福了),在比赛群里看到有同样思路的其他队伍积极交流啊(这个对我来说帮助很大),避免局部最优,闭门造车嘛。
4、自己的总结是参考了很多其他的博客以及知乎文章,因此有一些‘抄袭’吧。若原作者看见了请联系我,可以删除或者加上你的文章链接。感谢!
5、知乎图片应该会有压缩,因此上传一个Xmind源文件给大家,有需要的下载即可。里面不仅有上面那些图片的总结源文件,还有mmdetection的使用总结(因为我是一个爱写笔记的人,所以啥都总结),还有一些服务器的使用总结等等,关于Xmind中一些是我加工处理过的,信息传递会存在gap嘛甚至会存在错误,所以欢迎批评指正
XMIND源文件可在极市平台回复关键词“目标检测竞赛”获得。
觉得有用可以点个赞呀,谢谢,比心。

推荐阅读
