NAR|北大/中科院计算所团队发布基因功能富集分析平台KOBAS-i

近日,国际知名期刊《核酸研究》(Nucleic Acids Research,IF:16.971)在线发表了北京大学孔雷课题组与中国科学院计算技术研究所赵屹研究员课题组合作开发的基因功能富集平台KOBAS-i (网址http://kobas.cbi.pku.edu.cn/ 或http://bioinfo.org/kobas),文章题为“KOBAS-i: intelligent prioritization and exploratory visualization of biological functions for gene enrichment analysis”。
KOBAS是国际上最早的发布的基因通路富集工具之一,最初的版本由北大魏丽萍教授带领的生物信息团队设计和开发。最早的standalone版算法于2005年发表于Bioinformatics 杂志,该版本包括一个KO-Based注释系统和基于Over Representation Analysis (ORA)方法的富集分析算法。KOBAS 的Server版 1.0 和2.0分别于2006年和2011年在Nucleic Acids Research上发布,在基因集合富集分析领域内有较大影响力,总的SCI引用超过2000次,属于国产生物信息软件的佼佼者。
本次升级的版本KOBAS-i是由中科院计算所的团队与北大团队合作完成。与以往不同的是,此版本未沿用数字版本命名的方式,而是命名为KOBAS-i,在这里i的含义是 intelligent version,表明与既往两个版本相比,KOBAS-i在算法上有显著的升级。该版本除了保留之前版本的ORA富集分析算法,还增加了基于机器学习算法的整合富集分析算法。开发团队成员表示,未来KOBAS将在AI驱动的代谢通路分析算法上不断寻求创新。
KOBAS-i的功能更新主要解决了现有富集分析工具存在的三大问题。
基因功能富集分析领域长期存在的一个问题是,现存的众多富集分析工具在同一数据集上结果差异较大,KOBAS-i则利用机器学习算法为解决此问题提供了一个全新的思路。在KOBAS-i出现之前,功能富集分析算法有三大主流方法。ORA方法最早被提出,应用范围也最广。该方法的优点是算法简洁易实现,对输入数据要求较低,只需要输入一个基因列表就能工作。但ORA方法的缺点有两方面,一是ORA 假设各基因是相互独立的,不会互相影响,这是不符合真实世界实际情况的;二是ORA 输入的基因列表通常是根据p-value等指标来人为选定阈值从整体基因中选取,因而结果会受选取值的影响。
为了解决人为设定p-value阈值影响分析结果的问题,研究人员提出了Functional Class Scoring(FCS)方法。FCS算法的代表是GSEA方法,给定一个排好序的基因列表L和一个预先定义好的基因集合S(通常是同属一个信号或代谢通路的基因,或者在同一 GO 目录下的基因等)。GSEA的目标是判断 S 中的成员基因是随机分布在列表 L 中,还是倾向于集中在列表的头部或者尾部。相比于ORA算法,FCS输入的是全部基因列表L及其表达量等信息。因此FCS解决了人为设定p-value阈值影响分析结果的问题,但其算法仍然假定各基因之间是独立的,互相之间不会影响表达量。
为了解决基因之间互相关联的问题,研究人员又提出了Pathway Topology Based(PT)方法。PT分析方法考虑了基因在Pathway中的上下游关系,或者基因之间的相互作用关系,并利用这些信息对基因进行综合打分,然后仍然利用ORA或者FCS方法对打分后的基因进行富集分析。PT方法虽然考虑了基因之间存在的相互影响关系,但由于现有知识的局限,PT方法整合的基因相互作用网络通常是不完整和有局限性的,因此不同的PT方法在分析同一数据集时,结果差异也比较大。这样研究人员在使用和选择不同的富集分析工具时,得到的分析结果也往往不一致,如何采信不同的结果,往往依赖于用户的主观判断,这就给研究带来实际的困难。
为了解决这个问题,KOBAS-i引入了团队前期发表的集成学习算法CGPS,这是首个基于通路和表型的先验知识构建的GSE(gene set enrichment)集成分析算法。CGPS整合了七种广泛使用的FCS方法:GSEA、GSA、PADOG、PLAGE、GAGE、GLOBALTEST和SAFE,以及两个著名PT方法:GANPA和CEPA,并将上述方法的评分用集成学习生成一个综合评分,命名为R score。R score是基因集与实验分组的相关性度量,越大的 R score值表示更高相关性。利用R score,用户可以统一客观的度量不同富集分析方法的结果。CGPS不仅是一种统计集成模型,同时还是一种数据学习模型,能够智能地从已知通路和样本之间的关系中学习。与十种广泛使用的单独方法和两种集成方法相比,CGPS中的R score在120个模拟数据集和45个真实数据集上,能特异性发现其他GSE方法遗漏的生物学功能。
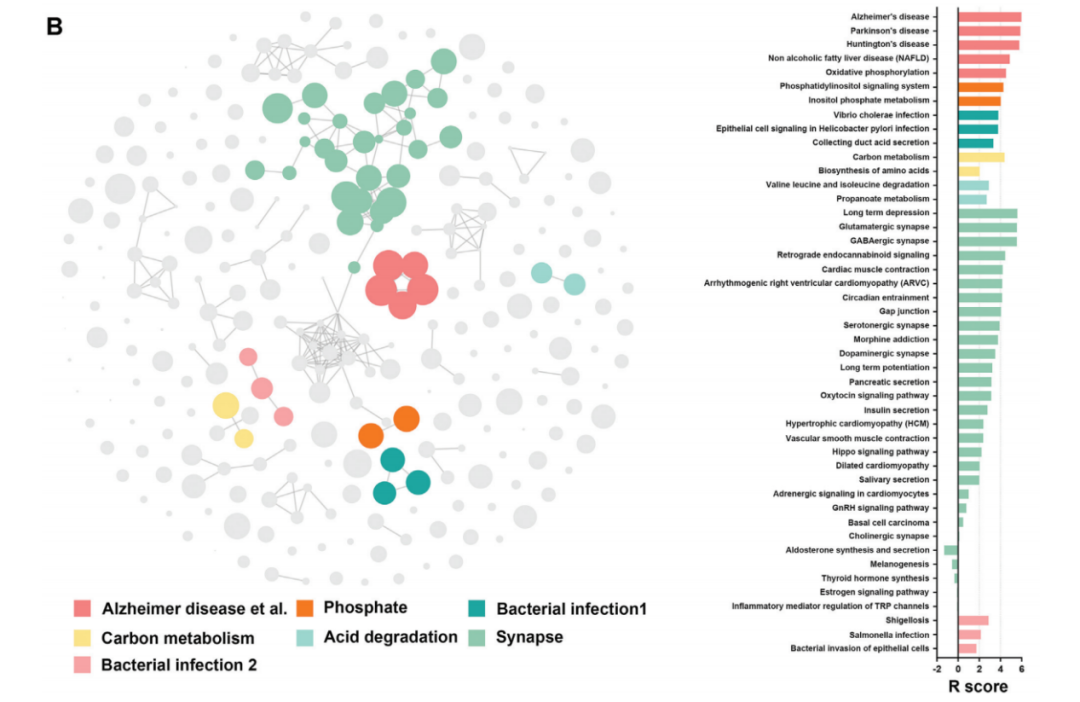
基因功能富集分析领域需要解决的另一问题是如何合理的归类富集分析结果。基因功能富集分析往往会得到几十甚至上百个可能与研究者实验分组相关的代谢通路,这就给研究人员进行进一步研究带来很大困难。如果能有合适的算法帮助研究者对代谢通路进行合理聚类和归并,将能使帮助研究者排除噪声,聚焦其所关心的具体生物学问题。KOBAS-i通过对富集分析结果进行智能聚类,推出新形式的功能富集图cirFunMap。为了帮助用户理解富集分析结果和聚焦关键生物学功能,KOBAS-i拓展了下游的交互探索可视化的过程,首次在线定义并集成了代谢通路聚类的可视化策略,以landscape的形式呈现不同的富集条目,及条目之间的关联。用户可以在提交的数据富集完成后,以个体视角交互式的方法探索并筛选数据中所隐藏的功能。在文章中,研究团队给出了一个利用阿尔茨海默病的基因列表和芯片表达谱数据,分别进行富集并绘制出cirFunMap图的demo,其可视化图能够简洁而清晰表示出功能富集的结果。
基因功能富集分析领域存在的一个通常容易被忽视,但非常重要的问题是注释数据库的更新问题。如果分析工具所使用的注释数据库不能及时更新,将会导致用户无法得到全面的分析结果,进而会影响研究的顺利进行。KOBAS-i整合了最新的KEGG数据库,将支持的物种从1327扩展到5944个,为5944个物种提供KEGG功能通路信息,71个物种提供GO注释信息。KOBAS-i支持Gene Symbols、Entrez ID、Fasta等多种形式作为输入进行功能富集分析。同时,为了降低单机版安装的复杂度,KOBAS-i提供了另一种无需安装的Docker镜像版本。在网站的服务方面,KOBAS-i放弃原有的PHP实现,改为接口化REST API的设计,以备后续的权限化、以及远程接口化的调用。任务的排队机制进一步梯度化,将BLAST任务和富集任务进行分队列调度,能够实现近乎实时化的富集结果的输出。
此外,为了克服可能的网络故障,除了原有的官方地址http://kobas.cbi.pku.edu.cn/,KOBAS研发团队还新构建了一个镜像服务地址http://bioinfo.org/kobas。KOBAS-i工作流程与操作指南详见文章原文:http://academic.oup.com/nar/article/49/W1/W317/6292104。
往期精品(点击图片直达文字对应教程)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|



























后台回复“生信宝典福利第一波”或点击阅读原文获取教程合集