正则表达式理论篇

首先你要记住它的名字
正则表达式可以干嘛
数据验证。
复杂的字符串搜寻、替换。
基于模式匹配从字符串中提取子字符串。
概述
构造函数(四种写法)
var regex = new RegExp('xyz', 'i');
var regex = new RegExp(/xyz/i);
var regex = /xyz/i;
// ES6的写法。ES5在第一个参数是正则时,不允许此时使用第二个参数,会报错。
// 返回的正则表达式会忽略原有的正则表达式的修饰符,只使用新指定的修饰符。
// 下面代码返回”i”。
new RegExp(/abc/ig, 'i').flags用于模式匹配的String方法
String.search()
参数:要搜索的子字符串,或者一个正则表达式。
返回:第一个与参数匹配的子串的起始位置,如果找不到,返回-1。
说明:不支持全局搜索,如果参数是字符串,会先通过RegExp构造函数转换成正则表达式。String.replace()
作用:查找并替换字符串。
第一个参数:字符串或正则表达式,
第二个参数:要进行替换的字符串,也可以是函数。
用法:
$1、$2、...、$99 与 regexp 中的第 1 到第 99 个子表达式相匹配的文本。
$& 与 regexp 相匹配的子串。
$` 位于匹配子串左侧的文本。
$' 位于匹配子串右侧的文本。
$$ 普通字符$。'abc'.replace(/b/g, "{$$$`$&$'}")
// 结果为 "a{$abc}c",即把b换成了{$abc}String.match() 参数:要搜索的子字符串,或者一个正则表达式。返回:一个由匹配结果组成的数组。

String.split() 作用:把一个字符串分割成字符串数组。
参数:正则表达式或字符串。返回:子串组成的数组。
RegExp的方法
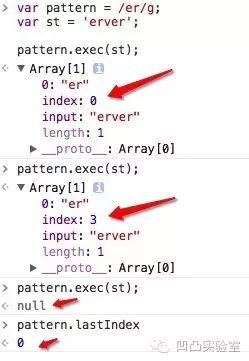
RegExpObject.exec() 参数:字符串。返回:
RegExpObject.test()
参数:字符串。
返回:true或false。RegExpObject.toString()
返回:字符串
字符
限定符(量词字符)
显示限定符中,逗号和数字之间不能有空格,否则返回null!
贪婪量词
*和+:javascript默认是贪婪匹配,也就是说匹配重复字符是尽可能多地匹配。惰性(最少重复匹配)量词
?:当进行非贪婪匹配,只需要在待匹配的字符后面跟随一个?即可。
var reg = /a+/;
var reg2 = /a+?/;
var str = 'aaab';
str.match(reg); // ["aaa"]
str.match(reg2); // ["a"]定位点(锚字符、边界)
标记
中括号
[]字符组;标记括号表达式的开始和结尾,起到的作用是匹配这个或者匹配那个。[...]匹配方括号内任意字符。很多字符在[]都会失去本来的意义:[^...]匹配不在方括号内的任意字符;[?.]匹配普通的问号和点号。
但是不要滥用字符组这个失去意义的特性,比如不要使用[.]来代替\:转义点号,因为需要付出处理字符组的代价。大括号
{}标记限定符表达式的开始和结尾。小括号
()标记子表达式的开始和结尾,主要作用是分组,对内容进行区分。
var str=`<div class="o2">
<div class="o2_team">
<img src="img/logo.jpg" />
</div>
</div>`;
// <(?!img) 表示找一个左尖括号<,而且左尖括号<的后面没有img字符;
// (?:.|\r|\n)*? 表示匹配左右尖括号<>里面的.或\r或\n,而且匹配次数为*?;(?:)不保存匹配项,提高性能;
// *后面加个? 表示非贪婪匹配。
var reg = /<(?!img)(?:.|\r|\n)*?>/gi;
str.match(reg);
// 返回结果 ["<div class="o2">", "<div class="o2_team">", "</div>", "</div>"]反向引用:主要作用是给分组加上标识符\n。
\n表示引用字符,与第n个子表达式第一次匹配的字符相匹配。
var reg = /(Mike)(\1)(s)/;
var str = "MikeMikes";
console.log(str.replace(reg,"$1$2'$3"));
// 返回结果 MikeMike's非打印字符
其他
修饰符
i执行不区分大小写的匹配。g执行一个全局匹配,简而言之,即找到所有的匹配,而不是在找到第一个之后就停止。m多行匹配模式,^匹配一行的开头和字符串的开头,$匹配行的结束和字符串的结束。
u修饰符
// 加u修饰符以后,ES6就会识别\uD83D\uDC2A为一个字符,返回false。
/^\uD83D/u.test('\uD83D\uDC2A') // false
/^\uD83D/.test('\uD83D\uDC2A') // truey修饰符
/b/y.exec('aba') // null
/b/.exec('aba') // ["b"]优先级顺序:
\转义符(), (?:), (?=), []括号和中括号*、+、?、{n}、{n,}、{n,m}限定符任何元字符
^、$、\定位点和序列|替换
关于引擎
以贪婪方式进行,尽可能匹配更多字符。
急于邀功请赏,所以最左子正则式优先匹配成功,因此偶尔会错过最佳匹配结果(多选条件分支的情况)。
'nfa not'.match(/nfa|nfa not/)
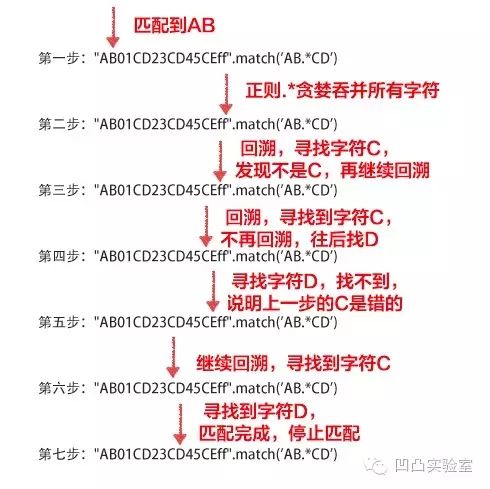
// 返回["nfa"]回溯(backtracking),导致速度慢。
"AB01CD23CD45CEff".match('AB.*CD')
// 返回 ["AB01CD23CD"]