
Java这个泛型高级特性,很多人还没用过!
你知道的越多,不知道的就越多,业余的像一棵小草!
成功路上并不拥挤,因为坚持的人不多。
编辑:业余草
zhenbianshu.github.io
推荐:https://www.xttblog.com/?p=5184
泛型是 Java 的高级特性之一,如果想写出优雅而高扩展性的代码,或是想读得懂一些优秀的源码,泛型是绕不开的槛。本文介绍了什么是泛型、类型擦除的概念及其实现,最后总结了泛型使用的最佳实践。
前言
想写一下关于 Java 一些高级特性的文章,虽然这些特性在平常实现普通业务时不必使用,但如果想写出优雅而高扩展性的代码,或是想读得懂一些优秀的源码,这些特性又是不可避免的。
如果对这些特性不了解,不熟悉特性的应用场景,使用时又因为语法等原因困难重重,很难让人克服惰性去使用它们,所以身边总有一些同事,工作了很多年,却从没有用过 Java 的某些高级特性,写出的代码总是差那么一点儿感觉。
为了避免几年后自己的代码还是非常 low,我准备从现在开始深入理解一下这些特性。本文先写一下应用场景最多的泛型。
泛型是什么
首先来说泛型是什么。泛型的英文是 generic,中文意思是通用的、一类的,结合其应用场景,我理解泛型是一种 通用类型。但我们一般指泛型都是指其实现方式,也就是 将类型参数化
对于 Java 这种强类型语言来说,如果没有泛型的话,处理相同逻辑不同类型的需求会非常麻烦。
如果想写一个对 int 型数据的快速排序,我们编码为(不是主角,网上随便找的=_=):
public static void quickSort(int[] data, int start, int end) {
int key = data[start];
int i = start;
int j = end;
while (i < j) {
while (data[j] > key && j > i) {
j--;
}
data[i] = data[j];
while (data[i] < key && i < j) {
i++;
}
data[j] = data[i];
}
data[i] = key;
if (i - 1 > start) {
quickSort(data, start, i - 1);
}
if (i + 1 < end) {
quickSort(data, i + 1, end);
}
}
可是如果需求变了,现在需要实现 int 和 long 两种数据类型的快排,那么我们需要利用 Java 类方法重载功能,复制以上代码,将参数类型改为 double 粘贴一遍。可是,如果还要实现 float、double 甚至字符串、各种类的快速排序呢,难道每添加一种类型就要复制粘贴一遍代码吗,这样未必太不优雅。
当然我们也可以声明传入参数为 Object,并在比较两个元素大小时,判断元素类型,并使用对应的方法比较。这样,代码就会恶心在类型判断上了。不优雅的范围小了一点,并不能解决问题。
这时,我们考虑使用通用类型(泛型),将快排方法的参数设置为一个通用类型,无论什么样的参数,只要实现了 Comparable 接口,都可以传入并排序。
public static <T extends Comparable<T>> void quickSort(T[] data, int start, int end) {
T key = data[start];
int i = start;
int j = end;
while (i < j) {
while (data[j].compareTo(key) > 0 && j > i) {
j--;
}
data[i] = data[j];
while (data[i].compareTo(key) < 0 && i < j) {
i++;
}
data[j] = data[i];
}
data[i] = key;
if (i - 1 > start) {
quickSort(data, start, i - 1);
}
if (i + 1 < end) {
quickSort(data, i + 1, end);
}
}
那么,可以总结一下泛型的应用场景了,当遇到以下场景时,我们可以考虑使用泛型:
当参数类型不明确,可能会扩展为多种时。 想声明参数类型为 Object,并在使用时用instanceof判断时。
需要注意,泛型只能替代Object的子类型,如果需要替代基本类型,可以使用包装类,至于为什么,会在下文中说明。
使用
然后我们来看一下,泛型怎么用。
声明
泛型的声明使用 <占位符 [,另一个占位符] > 的形式,需要在一个地方同时声明多个占位符时,使用 , 隔开。占位符的格式并无限制,不过一般约定使用单个大写字母,如 T 代表类型(type),E 代表元素*(element)等。虽然没有严格规定,不过为了代码的易读性,最好使用前检查一下约定用法。
泛型指代一种参数类型,可以声明在类、方法和接口上。
我们最常把泛型声明在类上:
class Generics<T> { // 在类名后声明引入泛型类型
private T field; // 引入后可以将字段声明为泛型类型
public T getField() { // 类方法内也可以使用泛型类型
return field;
}
}
把泛型声明在方法上时:
public [static] <T> void testMethod(T arg) { // 访问限定符[静态方法在 static] 后使用 <占位符> 声明泛型方法后,在参数列表后就可以使用泛型类型了
// doSomething
}
最后是在接口中声明泛型,如上面的快排中,我们使用了 Comparable<T> 的泛型接口,与此类似的还有 Searializable<T> Iterable<T>等,其实在接口中声明与在类中声明并没有什么太大区别。
调用
然后是泛型的调用,泛型的调用和普通方法或类的调用没有什么大的区别,如下:
public static void main(String[] args) {
String[] strArr = new String[2];
// 泛型方法的调用跟普通方法相同
Generics.quickSort(strArr, 0, 30 );
// 泛型类在调用时需要声明一种精确类型
Generics<Long> sample = new Generics<>();
Long field = sample.getField();
}
// 泛型接口需要在泛型类里实现
class GenericsImpl<T> implements Comparable<T> {
@Override
public int compareTo(T o) {
return 0;
}
}
类型擦除
讲泛型不可不提类型擦除,只有明白了类型擦除,才算明白了泛型,也就可以避开使用泛型时的坑。
由来
严格来说,Java的泛型并不是真正的泛型。Java 的泛型是 JDK1.5 之后添加的特性,为了兼容之前版本的代码,其实现引入了类型擦除的概念。
类型擦除指的是:Java 的泛型代码在编译时,由编译器进行类型检查,之后会将其泛型类型擦除掉,只保存原生类型,如 Generics<Long> 被擦除后是 Generics,我们常用的 List<String> 被擦除后只剩下 List。
接下来的 Java 代码在运行时,使用的还是原生类型,并没有一种新的类型叫 泛型。这样,也就兼容了泛型之前的代码。
如以下代码:
public static void main(String[] args) {
List<String> stringList = new ArrayList<>();
List<Long> longList = new ArrayList<>();
if (stringList.getClass() == longList.getClass()) {
System.out.println(stringList.getClass().toString());
System.out.println(longList.getClass().toString());
System.out.println("type erased");
}
}
结果 longList 和 stringList 输出的类型都为 class java.util.ArrayList,两者类型相同,说明其泛型类型被擦除掉了。
实际上,实现了泛型的代码的字节码内会有一个 signature 字段,其中指向了常量表中泛型的真正类型,所以泛型的真正类型,还可以通过反射获取得到。
实现
那么类型擦除之后,Java 是如何保证泛型代码执行期间没有问题的呢?
我们将一段泛型代码用 javac 命令编译成 class 文件后,再使用 javap 命令查看其字节码信息:
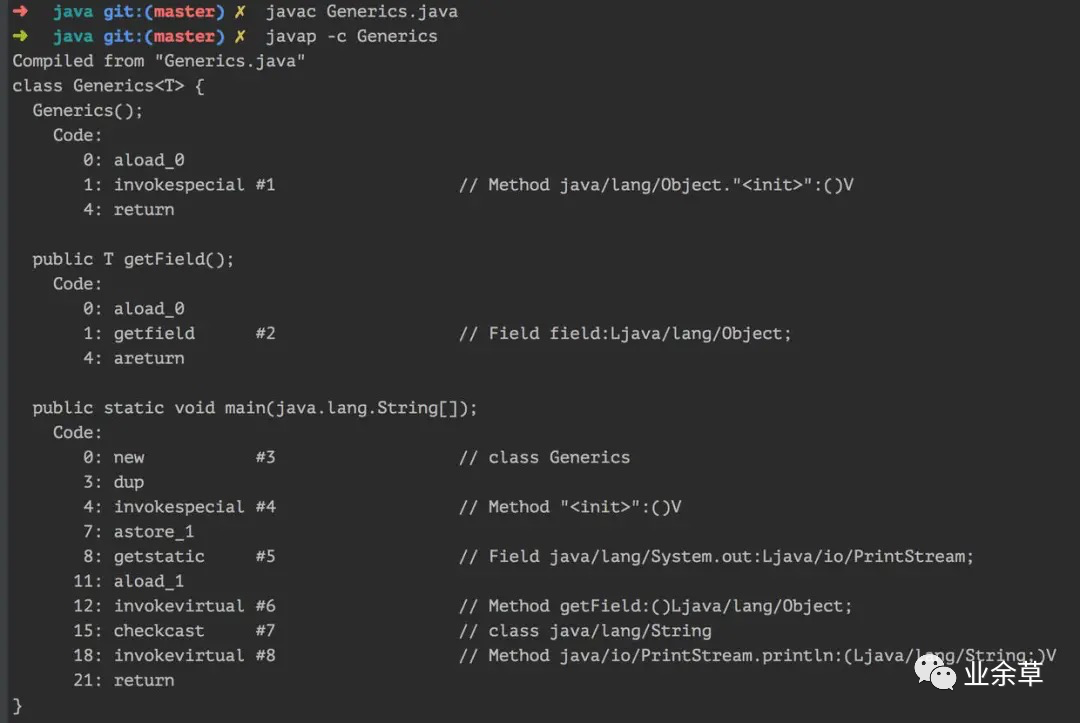
我们会发现,类型里的 T 被替换成了 Object 类型,而在 main 方法里 getField 字段时,进行了类型转换(checkcast),如此,我们可以看出来 Java 的泛型实现了,一段泛型代码的编译运行过程如下:
编译期间编译器检查传入的泛型类型与声明的泛型类型是否匹配,不匹配则报出编译器错误; 编译器执行类型擦除,字节码内只保留其原始类型; 运行期间,再将 Object 转换为所需要的泛型类型。
也就是说:Java 的泛型实际上是由编译器实现的,将泛型类型转换为 Object 类型,在运行期间再进行状态转换。
实践问题
由上,我们来看使用泛型时需要注意的问题:
具体类型须为Object子类型
上文中提到实现泛型时声明的具体类型必须为 Object 的子类型,这是因为编译器进行类型擦除后会使用 Object 替换泛型类型,并在运行期间进行类型转换,而基础类型和 Object 之间是无法替换和转换的。
如:Generics<int> generics = new Generics<int>(); 在编译期间就会报错的。
边界限定通配符的使用
泛型虽然为通用类型,但也是可以设置其通用性的,于是就有了边界限定通配符,而边界通配符要配合类型擦除才好理解。
<? extends Generics> 是上边界限定通配符,避开 上边界 这个比较模糊的词不谈,我们来看其声明 xx extends Generics, XX 是继承了 Generics 的类(也有可能是实现,下面只说继承),我们按照以下代码声明:
List<? extends Generics> genericsList = new ArrayList<>();
Generics generics = genericsList.get(0);
genericsList.add(new Generics<String>()); // 编译无法通过
我们会发现最后一行编译报错,至于为什么,可以如此理解:XX 是继承了 Generics 的类,List
而同理 <? super Generics> 是下边界限定通配符, XX 是 Generics 的父类,所以:
List<? super Generics> genericsList = new ArrayList<>();
genericsList.add(new Generics()); // 编译无法通过
Generics generics = genericsList.get(0);
使用前需要根据这两种情况,考虑需要 get 还是 set, 进而决定用哪种边界限定通配符。
最佳实践
当然,泛型并不是一个万能容器。什么类型都往泛型里扔,还不如直接使用 Object 类型。
什么时候确定用泛型,如何使用泛型,这些问题的解决不仅仅只依靠编程经验,我们使用开头快排的例子整理一下泛型的实践方式:
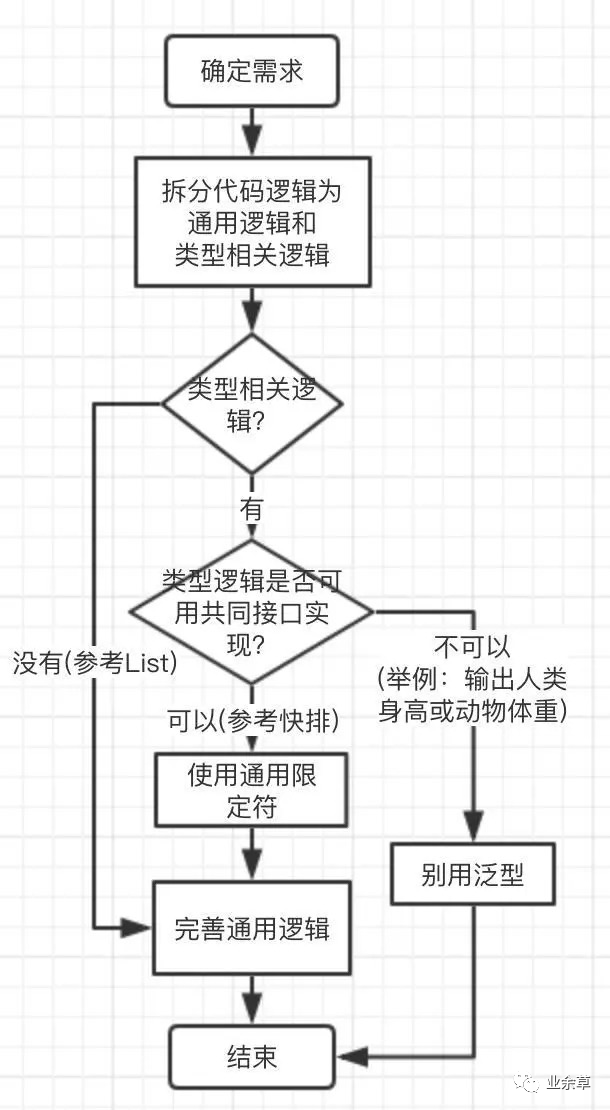
将代码逻辑拆分为两部分:通用逻辑和类型相关逻辑;通用逻辑是一些跟参数类型无关的逻辑,如快排的元素位置整理等;类型相关逻辑,顾名思义,是需要确定类型后才能编写的逻辑,如元素大小的比较,String 类型的比较和 int 类型的比较就不一样。 如果没有类型相关的逻辑,如 List 作为容器不需要考虑什么类型,那么直接完善通用代码即可。 如果有参数类型相关的逻辑,那么就需要考虑这些逻辑是否已有共同的接口实现,如果已有共同的接口实现,可以使用边界限定通配符。如快排的元素就实现了 Compare接口,Object 已经实现了toString()方法,所有的打印语句都可以调用它。如果还没有共同的接口,那么需要考虑是否可以抽象出一个通用的接口实现,如打印人类的衣服颜色和动物的毛皮颜色,就可以抽象出一个 getColor()接口,抽象之后再使用边界限定通配符。如果无法抽象出通用接口,如输出人类身高或动物体重这种,还是不要使用泛型了,因为不限定类型的话,具体类型的方法调用也就无从谈起,编译也无法通过。
我将以上步骤整理了一个流程图,按照这个图,我们可以快速得出能不能用泛型,怎么用泛型。
小结
好好理了一下泛型,感觉收获颇多,Java 迷雾被拨开了一些。这些特性确实挺难缠,每当自己觉得已经理解得差不多的时候,过些日子又觉得当初理解得还不够。重要的还是要实践,在使用时会很容易发现疑惑的地方。