[译]数据包在 Kubernetes 中的一生(1)
即使是对于具备一定虚拟网络和路由知识的人来说,Kubernetes 集群的网络也是个颇为麻烦的事情。本文尝试帮助读者理解 Kubernetes 网络的基础知识。初期目标是根据一个发往 Kubernetes 集群 Service 的 HTTP 请求的路线,来理解 Kubernetes 网络的复杂性。这中间会涉及到命名空间、CNI 以及 Calico。第一篇会从 Linux 网络开始,后续章节会涉及到其他主题。
Linux 命名空间
Linux 命名空间包含了现代容器中的一些基础技术。从高层来看,这一技术允许把系统资源在进程之间进行隔离。例如 PID 命名空间会会把进程 ID 空间进行隔离,这样同一个主机之中的两个进程就能隔离了。
这个级别的隔离对容器世界来说是很重要的。没有命名空间的话,A 容器中的进程可能会卸载 B 容器中的文件系统,或者修改 C 容器的主机名,又或删除 D 容器的网卡。将这些资源纳入命名空间进行管理,A 容器甚至无法感知 B、C、D 容器的存在。
Mount:
隔离文件系统加载点;
UTS:
隔离主机名和域名;
IPC:
隔离跨进程通信(IPC)资源;
PID:
隔离 PID 空间;
网络:
隔离网络接口;
用户:
隔离 UID/GID 空间;
Cgroup:
隔离 cgroup 根目录。
绝大多数容器会使用上述命名空间在容器进程之间进行隔离。要注意 cgroup 命名空间出现较晚,相对其它命名空间来说,用的比较少。
容器网络(网络命名空间)
在进入 CNI 和 Docker 之前,首先看看容器网络的核心技术。Linux 内核有不少多租户方面的功能。命名空间对不同种类的资源进行了隔离,网络命名空间隔离的自然就是网络。
在主流 Linux 操作系统中都可以简单地用 ip 命令创建网络命名空间。接下来创建两个分别用于服务器和客户端的网络命名空间。
$ ip netns add client
$ ip netns add server
$ ip netns list
server
client
创建一对 veth 将命名空间进行连接,可以把 veth 想象为连接两端的网线。
$ ip link add veth-client type veth peer name veth-server
$ ip link list | grep veth
4: veth-server@veth-client: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
5: veth-client@veth-server: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000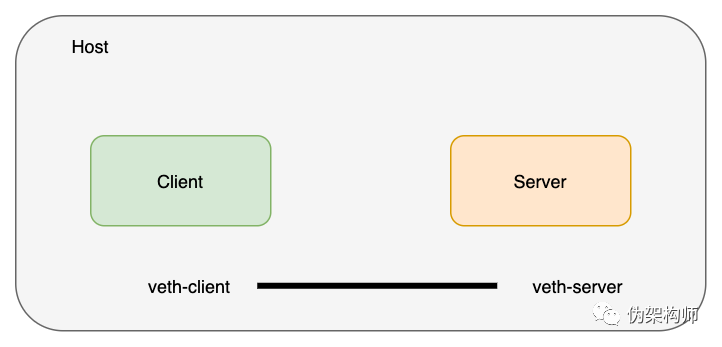
这一对 veth 是存在于主机的网络命名空间的,接下来我们把两端分别置入各自的命名空间:
$ ip link set veth-client netns client
$ ip link set veth-server netns server
$ ip link list | grep veth # doesn’t exist on the host network namespace now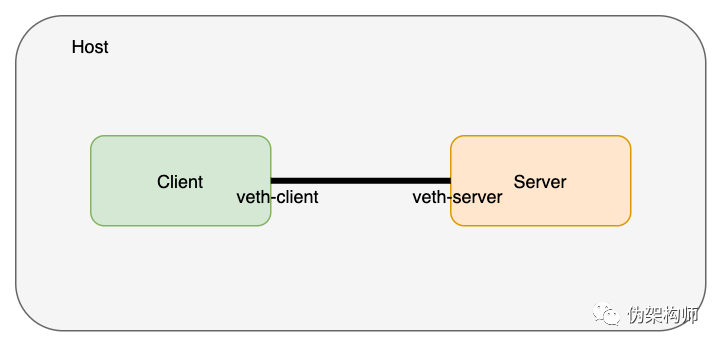
从 client 命名空间检查一下命名空间中的 veth 状况:
$ ip netns exec client ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth-client@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1然后是 server 命名空间:
$ ip netns exec server ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth-server@if5: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0接下来给这些网络接口分配 IP 地址并启用:
$ ip netns exec client ip address add 10.0.0.11/24 dev veth-client
$ ip netns exec client ip link set veth-client up
$ ip netns exec server ip address add 10.0.0.12/24 dev veth-server
$ ip netns exec server ip link set veth-server up
$
$ ip netns exec client ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
5: veth-client@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ca:e8:30:2e:f9:d2 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 10.0.0.11/24 scope global veth-client
valid_lft forever preferred_lft forever
inet6 fe80::c8e8:30ff:fe2e:f9d2/64 scope link
valid_lft forever preferred_lft forever
$
$ ip netns exec server ip addr
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
4: veth-server@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 42:96:f0:ae:f0:c5 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.12/24 scope global veth-server
valid_lft forever preferred_lft forever
inet6 fe80::4096:f0ff:feae:f0c5/64 scope link
valid_lft forever preferred_lft forever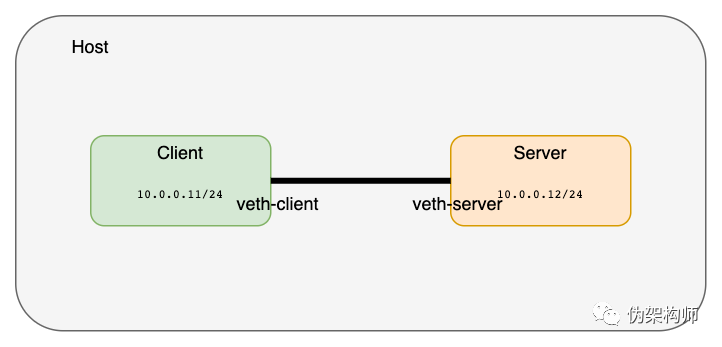
在 client 命名空间中使用 ping 命令检查一下两个网络命名空间的连接状况:
$ ip netns exec client ping 10.0.0.12
PING 10.0.0.12 (10.0.0.12) 56(84) bytes of data.
64 bytes from 10.0.0.12: icmp_seq=1 ttl=64 time=0.101 ms
64 bytes from 10.0.0.12: icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from 10.0.0.12: icmp_seq=3 ttl=64 time=0.084 ms
64 bytes from 10.0.0.12: icmp_seq=4 ttl=64 time=0.077 ms
64 bytes from 10.0.0.12: icmp_seq=5 ttl=64 time=0.079 ms如果要创建更网络命名空间并互相连接,用 veth 对将这些网络命名空间进行两两连接就很麻烦了。可以创建创建一个 Linux 网桥来连接这些网络命名空间。Docker 就是这样为同一主机内的容器进行连接的。
下面就创建网络命名空间并用网桥连接起来:
# All in one
BR=bridge1
HOST_IP=172.17.0.33
ip link add client1-veth type veth peer name client1-veth-br
ip link add server1-veth type veth peer name server1-veth-br
ip link add $BR type bridge
ip netns add client1
ip netns add server1
ip link set client1-veth netns client1
ip link set server1-veth netns server1
ip link set client1-veth-br master $BR
ip link set server1-veth-br master $BR
ip link set $BR up
ip link set client1-veth-br up
ip link set server1-veth-br up
ip netns exec client1 ip link set client1-veth up
ip netns exec server1 ip link set server1-veth up
ip netns exec client1 ip addr add 172.30.0.11/24 dev client1-veth
ip netns exec server1 ip addr add 172.30.0.12/24 dev server1-veth
ip netns exec client1 ping 172.30.0.12 -c 5
ip addr add 172.30.0.1/24 dev $BR
ip netns exec client1 ping 172.30.0.12 -c 5
ip netns exec client1 ping 172.30.0.1 -c 5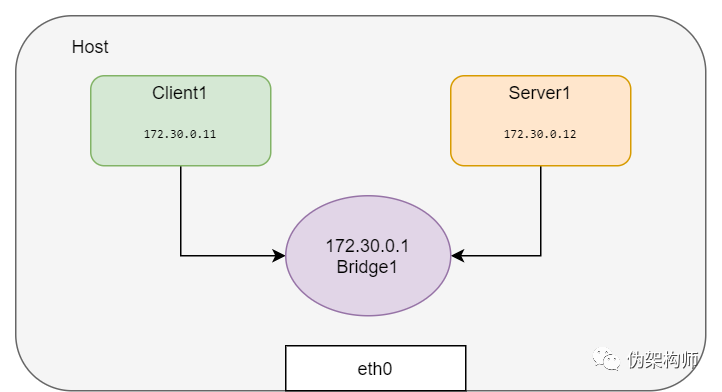
还是用 ping 命令检查两个网络命名空间的连接性:
$ ip netns exec client1 ping 172.30.0.12 -c 5
PING 172.30.0.12 (172.30.0.12) 56(84) bytes of data.
64 bytes from 172.30.0.12: icmp_seq=1 ttl=64 time=0.138 ms
64 bytes from 172.30.0.12: icmp_seq=2 ttl=64 time=0.091 ms
64 bytes from 172.30.0.12: icmp_seq=3 ttl=64 time=0.073 ms
64 bytes from 172.30.0.12: icmp_seq=4 ttl=64 time=0.070 ms
64 bytes from 172.30.0.12: icmp_seq=5 ttl=64 time=0.107 ms从命名空间中 ping 一下主机 IP:
$ ip netns exec client1 ping $HOST_IP -c 2
connect: Network is unreachableNetwork is unreachable 的原因是路由不通,加入一条缺省路由:
$ ip netns exec client1 ip route add default via 172.30.0.1
$ ip netns exec server1 ip route add default via 172.30.0.1
$ ip netns exec client1 ping $HOST_IP -c 5
PING 172.17.0.23 (172.17.0.23) 56(84) bytes of data.
64 bytes from 172.17.0.23: icmp_seq=1 ttl=64 time=0.053 ms
64 bytes from 172.17.0.23: icmp_seq=2 ttl=64 time=0.121 ms
64 bytes from 172.17.0.23: icmp_seq=3 ttl=64 time=0.078 ms
64 bytes from 172.17.0.23: icmp_seq=4 ttl=64 time=0.129 ms
64 bytes from 172.17.0.23: icmp_seq=5 ttl=64 time=0.119 ms
--- 172.17.0.23 ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.053/0.100/0.129/0.029 msdefault 路由打通了网桥的通信,这样这个命名空间就能和外部网络进行通信了:
$ ping 8.8.8.8 -c 2
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=117 time=3.40 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=117 time=3.81 ms
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 3.403/3.610/3.817/0.207 ms从外部服务器连接内网
如你所见,这里演示用的机器已经安装了 Docker,也就是说已经创建了 docker0 网桥。测试场景需要所有网络命名空间的协同,进行 Web Server 的测试有些复杂,因此这里就借用一下 docker0:
docker0 Link encap:Ethernet HWaddr 02:42:e2:44:07:39
inet addr:172.18.0.1 Bcast:172.18.0.255 Mask:255.255.255.0
UP BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)运行一个 nginx 容器并进行观察:
$ docker run -d --name web --rm nginx
efff2d2c98f94671f69cddc5cc88bb7a0a5a2ea15dc3c98d911e39bf2764a556
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
$ docker inspect web --format '{{ .NetworkSettings.SandboxKey }}'
/var/run/docker/netns/c009f2a4be71Docker 创建的 netns 没有保存在缺省位置,所以 ip netns list 是看不到这个网络命名空间的。我们可以在缺省位置创建一个符号链接:
$ container_id=web
$ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
$ mkdir -p /var/run/netns
$ rm -f /var/run/netns/${container_id}
$ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/web' -> '/var/run/docker/netns/c009f2a4be71'
$ ip netns list
web (id: 3)
server1 (id: 1)
client1 (id: 0)看看 web 命名空间的 IP 地址:
$ ip netns exec web ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
11: eth0@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.3/24 brd 172.18.0.255 scope global eth0
valid_lft forever preferred_lft forever然后看看容器里的 IP 地址:
$ WEB_IP=`docker inspect -f "{{ .NetworkSettings.IPAddress }}" web`
$ echo $WEB_IP
172.18.0.3从主机访问一下 web 命名空间的服务:
$ curl $WEB_IP
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...加入端口转发规则,其它主机就能访问这个 nginx 了:
$ iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to-destination $WEB_IP:80
$ echo $HOST_IP
172.17.0.23使用主机 IP 访问 Nginx:
$ curl 172.17.0.23
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>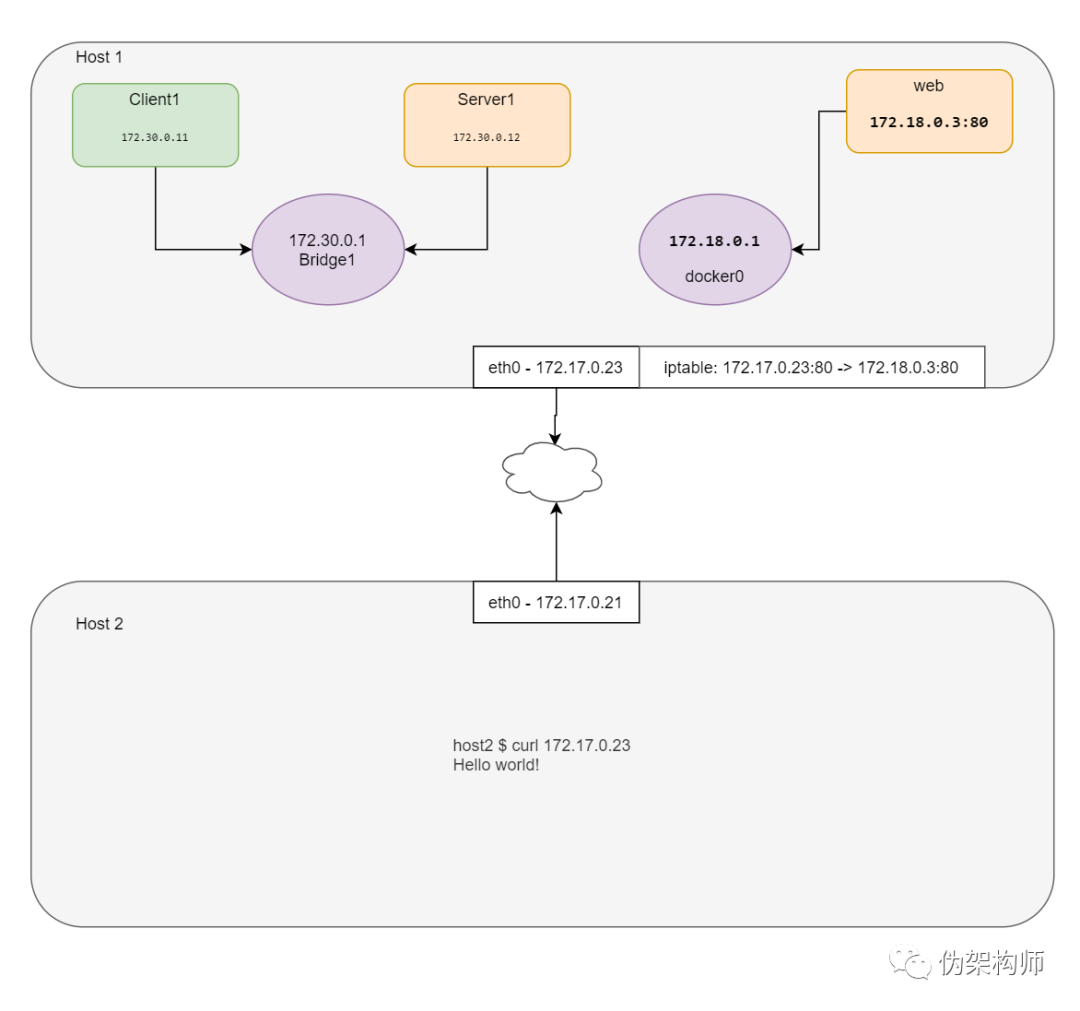
CNI 插件会执行上面的过程(不完全相同,但是类似)来设置 loopback、eth0,并给容器分配 IP。容器运行时调用 CNI 设置 Pod 网络,接下来讨论一下 CNI。
CNI 是什么
CNI 插件负责在容器网络命名空间中插入一个网络接口(也就是
veth对中的一端)并在主机侧进行必要的变更(把veth对中的另一侧接入网桥)。然后给网络接口分配 IP,并调用 IPAM 插件来设置相应的路由。
看起来很眼熟吧?是的,我们在前面的容器网络部分已经说了这些内容。
CNI 是一个 CNCF 项目,其中包含了在 Linux 容器进行网络配置的规范和库。CNI 的主要工作就是容器网络的连接能力,并在容器销毁时移除相应的已分配资源。这种专注性使得 CNI 易于实现,因此被广泛接受。
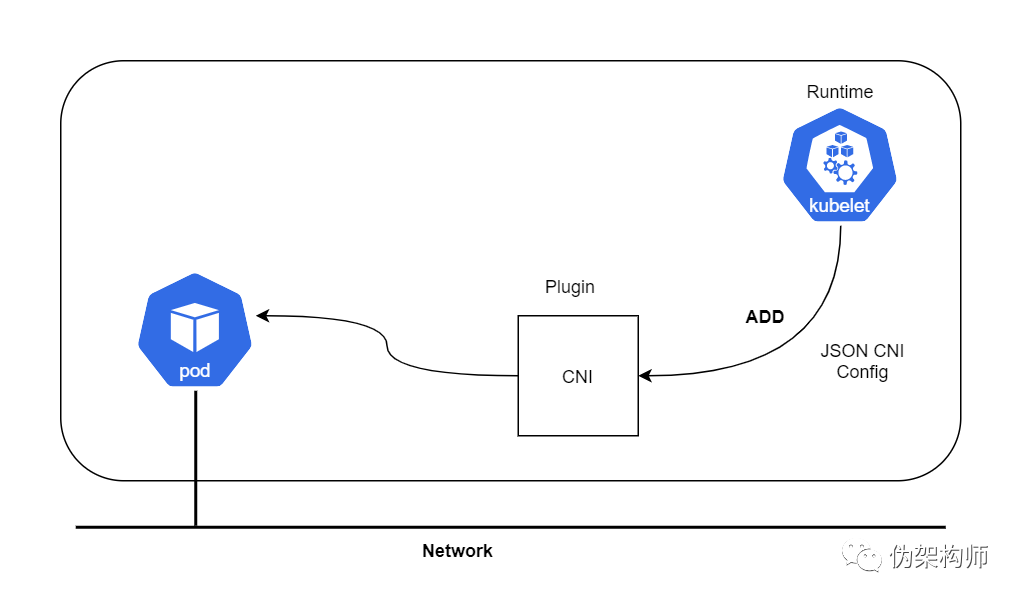
此处所说的运行时可能是 Kubernetes、Podman 等等。
CNI 规范
https://github.com/containernetworking/cni/blob/master/SPEC.md
在我首次阅读时,注意到了一些点:
因为 Docker 等运行时会为每个容器新建一个网络命名空间,所以规范把容器定义为 Linux 网络命名空间;
CNI 的网络定义用 JSON 格式存储;
网络定义通过 STDIN 发送给插件;
换句话说主机上并没有网络配置文件;
其他参数通过环境变量进行传递;
CNI 插件是可执行文件;
CNI 插件负责容器的网络;
换句话说,它需要完成所有容器接入网络所需的工作。
在 Docker 中会包含把容器网络命名空间连回主机的工作;
CNI 插件负责 IPAM 工作,其中包括 IP 地址分配和路由设置。
接下来尝试脱离 Kubernetes 模拟创建 Pod,并使用 CNI 插件而非 CLI 命令进行 IP 分配。完成 Demo 就会更好地理解 Kubernetes 中 Pod 的本质。
第一步:下载 CNI 插件:
$ mkdir cni
$ cd cni
$ curl -O -L https://github.com/containernetworking/cni/releases/download/v0.4.0/cni-amd64-v0.4.0.tgz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 644 100 644 0 0 1934 0 --:--:-- --:--:-- --:--:-- 1933
100 15.3M 100 15.3M 0 0 233k 0 0:01:07 0:01:07 --:--:-- 104k
$ tar -xvf cni-amd64-v0.4.0.tgz
./
./macvlan
./dhcp
./loopback
./ptp
./ipvlan
./bridge
./tuning
./noop
./host-local
./cnitool
./flannel第二步,创建一个 JSON 格式的 CNI 配置(00-demo.conf):
{
"cniVersion": "0.2.0",
"name": "demo_br",
"type": "bridge",
"bridge": "cni_net0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.0.10.0/24",
"routes": [
{ "dst": "0.0.0.0/0" },
{ "dst": "1.1.1.1/32", "gw":"10.0.10.1"}
] }}CNI 配置参数:
-:CNI generic parameters:-
cniVersion: The version of the CNI spec in which the definition works with
name: The network name
type: The name of the plugin you wish to use. In this case, the actual name of the plugin executable
args: Optional additional parameters
ipMasq: Configure outbound masquerade (source NAT) for this network
ipam:
type: The name of the IPAM plugin executable
subnet: The subnet to allocate out of (this is actually part of the IPAM plugin)
routes:
dst: The subnet you wish to reach
gw: The IP address of the next hop to reach the dst. If not specified the default gateway for the subnet is assumed
dns:
nameservers: A list of nameservers you wish to use with this network
domain: The search domain to use for DNS requests
search: A list of search domains
options: A list of options to be passed to the receiver第三步:创建一个网络为 none 的容器,这个容器没有网络地址。可以用任意的镜像创建该容器,这里我用 pause 来模拟 Kubernetes:
$ docker run --name pause_demo -d --rm --network none kubernetes/pause
Unable to find image 'kubernetes/pause:latest' locally
latest: Pulling from kubernetes/pause
4f4fb700ef54: Pull complete
b9c8ec465f6b: Pull complete
Digest: sha256:b31bfb4d0213f254d361e0079deaaebefa4f82ba7aa76ef82e90b4935ad5b105
Status: Downloaded newer image for kubernetes/pause:latest
763d3ef7d3e943907a1f01f01e13c7cb6c389b1a16857141e7eac0ac10a6fe82
$ container_id=pause_demo
$ container_netns=$(docker inspect ${container_id} --format '{{ .NetworkSettings.SandboxKey }}')
$ mkdir -p /var/run/netns
$ rm -f /var/run/netns/${container_id}
$ ln -sv ${container_netns} /var/run/netns/${container_id}
'/var/run/netns/pause_demo' -> '/var/run/docker/netns/0297681f79b5'
$ ip netns list
pause_demo
$ ip netns exec $container_id ifconfig
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)第四步:用前面的配置来调用 CNI 插件:
$ CNI_CONTAINERID=$container_id CNI_IFNAME=eth10 CNI_COMMAND=ADD CNI_NETNS=/var/run/netns/$container_id CNI_PATH=`pwd` ./bridge </tmp/00-demo.conf
2020/10/17 17:32:37 Error retriving last reserved ip: Failed to retrieve last reserved ip: open /var/lib/cni/networks/demo_br/last_reserved_ip: no such file or directory
{
"ip4": {
"ip": "10.0.10.2/24",
"gateway": "10.0.10.1",
"routes": [
{
"dst": "0.0.0.0/0"
},
{
"dst": "1.1.1.1/32",
"gw": "10.0.10.1"
}
]
},
"dns": {}CNI_COMMAND=ADD:动作,可选范围包括
ADD、DEL和CHECK;CNI_CONTAINER=pause_demo:通知 CNI 对
pause_demo网络命名空间进行操作;CNI_NETNS=/var/run/netns/pause_demo:命名空间所在路径;
CNI_IFNAME=eth10:在容器端创建的网络接口名称;
CNI_PATH=`pwd`:CNI 插件的可执行文件的位置,在本例中我们的当前目录已经是
cni目录,因此这个环境变量设置为`pwd`即可.
强烈建议阅读 CNI 规范以获知更多 CNI 插件及其功能的信息。在同一个 JSON 文件中可以使用多个插件形成调用链,可以用于建立防火墙规则等类似操作。
第五步,运行上面的命令会返回一些内容。
首先是因为 IPAM 驱动在本地找不到保存 IP 信息的文件而报错。但是因为第一次运行插件时会创建这个文件,所以在其他命名空间再次运行这个命令就不会出现这个问题了。
其次是得到一个说明插件已经完成相应 IP 配置的 JSON 信息。在本例中,网桥的 IP 地址应该是 10.0.10.1/24,命名空间网络接口的地址则是 10.0.10.2/24。另外还会根据我们的 JSON 配置文件,加入缺省路由以及 1.1.1.1/32 路由。检查一下:
$ ip netns exec pause_demo ifconfig
eth10 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:02
inet addr:10.0.10.2 Bcast:0.0.0.0 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:18 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1476 (1.4 KB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
$ ip netns exec pause_demo ip route
default via 10.0.10.1 dev eth10
1.1.1.1 via 10.0.10.1 dev eth10
10.0.10.0/24 dev eth10 proto kernel scope link src 10.0.10.2CNI 创建了网桥并根据 JSON 信息进行了相应配置:
$ ifconfig
cni_net0 Link encap:Ethernet HWaddr 0a:58:0a:00:0a:01
inet addr:10.0.10.1 Bcast:0.0.0.0 Mask:255.255.255.0
inet6 addr: fe80::c4a4:2dff:fe4b:aa1b/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:7 errors:0 dropped:0 overruns:0 frame:0
TX packets:20 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1174 (1.1 KB) TX bytes:1545 (1.5 KB)第六步,启动 Web Server 并共享 pause 容器命名空间:
$ docker run --name web_demo -d --rm --network container:$container_id nginx
8fadcf2925b779de6781b4215534b32231685b8515f998b2a66a3c7e38333e30第七步,使用 pause 容器的 IP 地址访问 Web Server:
$ curl `cat /var/lib/cni/networks/demo_br/last_reserved_ip`
<!DOCTYPE html>
<html>
<head>
<title>Welcome to ngi,nx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
...接下来看看 Pod 的定义。
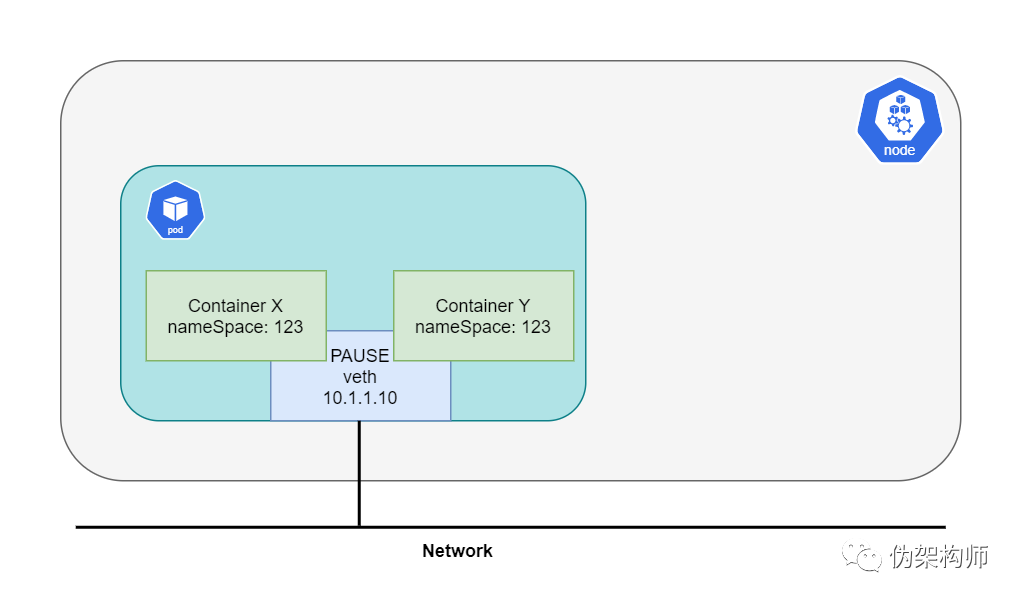
Pod 网络命名空间
接触 Kubernetes 最应该知道的一个问题就是,Pod 不等于容器,而是一组容器。这一组容器会共享同一个网络栈。每个 Pod 都会包含有 pause 容器,Kubernetes 通过这个容器来管理 Pod 的网络。所有其他容器都会附着在 pause 容器的网络命名空间中,而 pause 除了网络之外,再无其他作用。因此同一个 Pod 中的不同容器,可以通过 localhost 进行互访: