
注意力机制work的原因在于噪声的调节?较轻量的批归一化技术IBEN(AAAI)

极市导读
本篇文章介绍一篇发表在AAAI2020的工作IBENpaper,本文主要尝试探究的是如SENet这样的注意力机制结构提升模型性能的原因。并根据分析的结果提出了一种较轻量的批归一化(batch normalization)技术IBEN。>>加入极市CV技术交流群,走在计算机视觉的最前沿

论文链接:https://ojs.aaai.org/index.php/AAAI/article/download/5917/5773
代码链接:https://github.com/gbup-group/IEBN
本篇文章介绍我们发表在AAAI2020的工作IBENpaper,本文主要尝试探究的是如SENet这样的注意力机制结构提升模型性能的原因。根据分析的结果,我们提出了IBEN这种较轻量的批归一化(batch normalization)技术,实现非常简单,使用方便。如果你的工作需要用到BN,那么也欢迎试试使用IEBN~
本文的主要看点:
如SENet这样的注意力机制结构和批归一化作用形式实际上很接近; 文章给出了两种噪声影响的实验,包括常数噪声攻击,混合数据噪声攻击; 认为如SENet这样的注意力机制结构work的原因可能是对数据中噪声的有效自适应调节; 根据上述观察,提出了一种较轻量的批归一化技术,即IEBN。
SENet (squeeze-and-excitation networks) 是计算机视觉领域中注意力机制的重量级文章,在本文章撰写的时候谷歌学术引用已经高达12500+,可见其影响力,具体的介绍可以看看这篇简介:【CV中的Attention机制】SENet中的SE模块(https://zhuanlan.zhihu.com/p/102035721)。如果用一句话来尝试总结SENet的话,可以认为是
如下图所示,它在神经网络的某个位置,通过"某种作用"对这个位置的feature map按channel为维度,每个channel乘上一个系数。
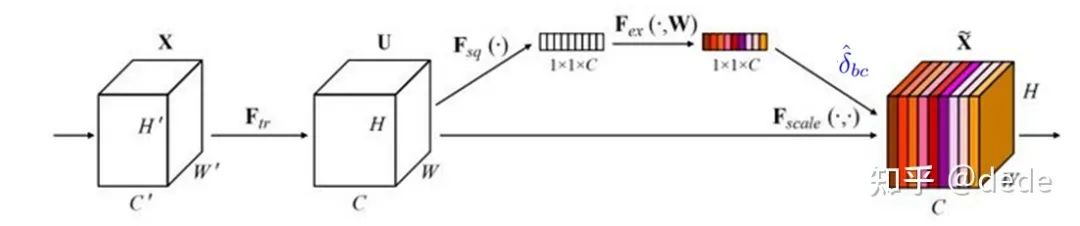
根据不同的"某种作用",除了SENet之外,后续提出了BAM, CBAM, DIANet,GENet, FcaNet, DANet等等不同的工作,有兴趣的可以看看这个github锦集:https://link.zhihu.com/?target=https%3A//github.com/pprp/awesome-attention-mechanism-in-cv。不过不管是怎么样的"某种作用", 他们最终都是为了生成一个好的系数去乘在feature map上,这个系数我们用 来表示。
注意到,实际上这种说法也同样比较符合包括batch normalization在内的各种归一化方法(BN, IN,GN等等),以batch normalization为例,
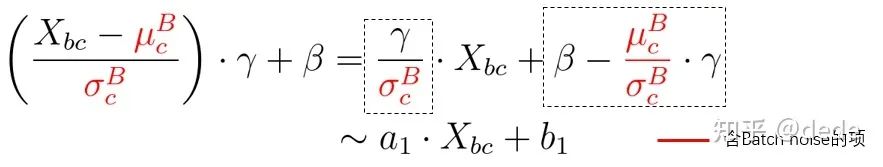
特征 通过batch维度的均值 和方差 做归一化后,再作用两个可学习参数 和 。实际上,最终它对特征 是做了一个线性变换 。从这个角度上看,SENet等注意力机制也是对特征做一个线性变换,其中 , 。他们的差别仅仅在 和 的信息的来源不同,如来自于样本自身的信息(这里的b表示样例本身,均值 和方差 来源于batch的信息,可学习参数 和 主要来源于batch的信息来训练等等)。
至此,我们从这个统一的观点出发,探究如SENet这样的注意力机制work的可能的原因。实际上在很多工作中,SENet的作用位点跟在BN的后面,即如下所示:
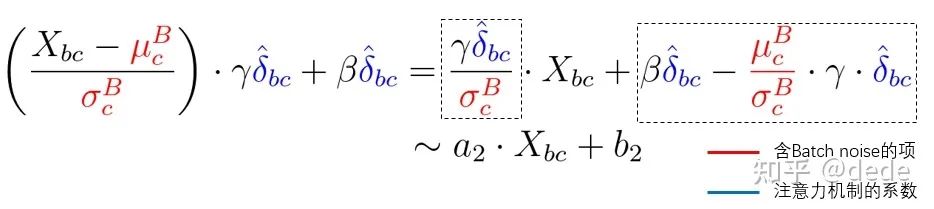
注意力机制的噪声调节(以风格迁移为例)
以风格迁移任务作为探究对象,如下图所示,我们发现带有BN的网络在风格迁移的结果中有一些奇怪。这是因为风格迁移任务是噪声敏感的(Salimans and Kingma 2016),BN的操作 引入了batch上的噪声,因此在风格迁移中常用的归一化方法是IN(Instance normalization),IN在归一化的 时候,均值和方差都仅仅从local的sample中计算,因此不会混入batch上的噪声。从风格迁移的结果来看, IN的结果确实比BN好(就。。就感觉比较和谐,没有一坨一坨的感觉?我也不知道应该怎么说风格迁移 的好和不好┑( ̄Д  ̄)┍)
此时,当我们在BN上加入SE模块后,惊奇地发现,SE+BN的结果和IN非常相似。尽管仍然使用了BN,引入了batch的噪声,但是由于SE接在BN后面,这样的”噪声“竟然被消除(或者说缓解)了!

从loss的角度的话,SE+BN也更加接近于没有batch noise的IN的曲线,并远离BN的训练loss,
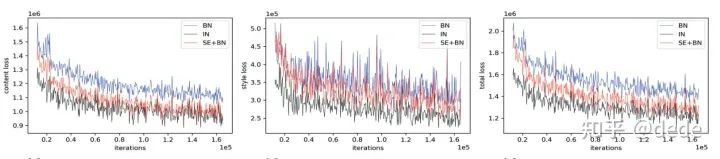
如果从上公式来看,含有batch noise的项(红色),似乎都有注意力机制的系数 (蓝色)相作用。有理由猜想,注意力机制的系数 在自适应地对batch noise进行调节!如果用前面提到的统一的观点来说,那么
注意力机制的系数在针对任务自适应调节由BN带来的噪声,给出更好的线性变换系数 , 。而对于风格迁移来说,好的 , 至少是没有batch noise的
噪声攻击
为了进一步说明注意力机制对噪声的调节,本节在图像分类任务上给出两种混入噪声的方式。
1. 常数噪声攻击
这种攻击方式,即在进行BN的归一化的时候,我们给定两个和任务完全无关的常数 和 ,做如下的“添油加醋”:
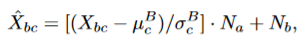
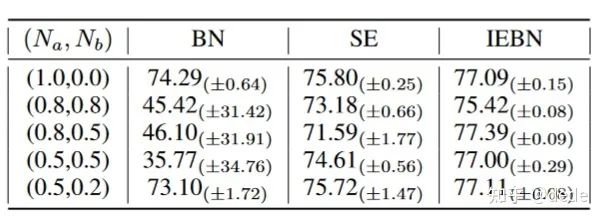
从不同的常数攻击的结果来看,SENet这样的注意力机制能很好的缓解常数噪声的影响,使得模型的性能更加稳定(相比BN方差显著变小)。按道理来说,BN的可学习参数 和 应该也可以轻松地消除常数,比如 只需要学习一个 带有项的系数就能轻松消除 的影响(分析可以看论文公式12-15),然而从实验结果来看,BN似乎并没有能消除噪声影响。仍然需要注意力机制的系数来帮一把,进行噪声调节。
2. 混合数据噪声攻击
混合数据噪声攻击,即在某数据集的基础上,在训练的时候每个batch混入类型完全不同的其他数据集,以达到干扰BN的均值 和方差 。在本文中,我们考虑在CIFAR100中混入MINIST或者FashionMINIST,用" "来表示,其中 表示混入多少数量的MINIST或者FashionMINIST数据。
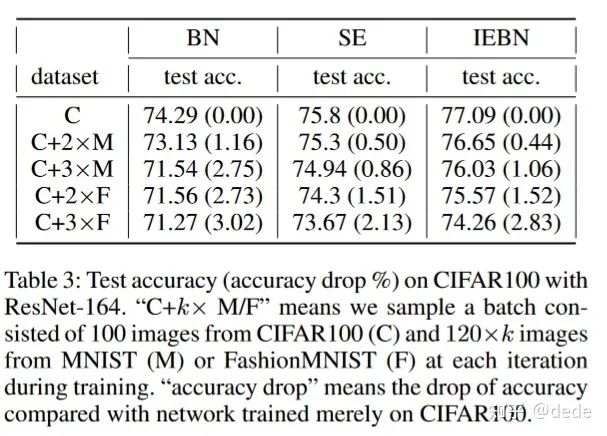
结果如上图所示,再次说明了注意力机制在对噪声调节的优越性!
IBEN模块的提出
至此,我们知道了注意力机制work的可能的原因是对噪声的自适应调节。BN这样的操作所带来的噪声不一定完美的噪声(人为规则),它也需要一定的微调(而纯粹的 和 的调节仍然不够,如常数噪声攻击部分所提到的情况)。这也可能是在深度学习各种任务中注意力机制成功的原因。
既然BN需要一个有力的噪声调整,我们为何不直接在BN上接一个注意力机制的系数(本质上仍然是注意力机制的模块)以得到一个新的归一化方法,即一个拥有自适应调节噪声的BN呢?不过注意到的是,这个产生注意力机制系数的过程一定要是轻量级的,否则在替换BN的过程中会产生很多的参数量,因此,我们设计了如下的归一化过程:
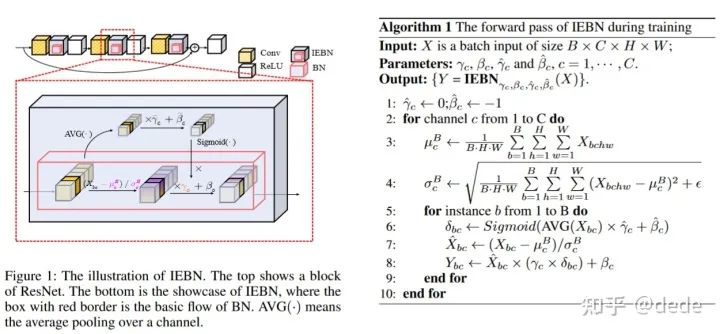
不需要像SENet那样来一个FC,而只需要每一个channel给予两个系数做线性变换即可,实验发现IBEN的不仅参数少,而且性能强劲~值得一试。更多的实验和分析欢迎大家到文章中查阅。
未来的工作
对于注意力如何提升网络性能的原理的探究目前工作还是比较少。我们提出的注意力机制对噪声的控制的论点,有潜力在一些关注噪声的领域,例如生成模型,对抗攻击中应用,domaim shifting相关工作中; 针对一些使用了BN网络的应用,可以考虑使用IEBN等带有注意力模块的批归一化方法; 一些未有解决的问题也可以进一步讨论,如为什么BN不能处理如常数攻击这样的简单干扰?
公众号后台回复“96”获取NTIRE2022冠军方案直播链接~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
