从一个小白的角度理解GAN网络

来自 | CSDN博客 作者 | JensLee
本文仅作学术交流,如有侵权,请联系后台删除
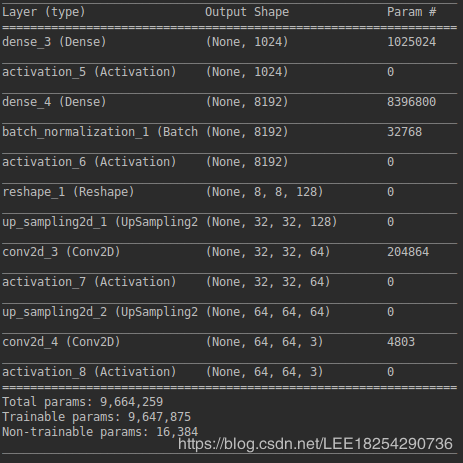
def generator_model():model = Sequential()model.add(Dense(input_dim=1000, output_dim=1024))model.add(Activation('tanh'))model.add(Dense(128 * 8 * 8))model.add(BatchNormalization())model.add(Activation('tanh'))model.add(Reshape((8, 8, 128), input_shape=(8 * 8 * 128,)))model.add(UpSampling2D(size=(4, 4)))model.add(Conv2D(64, (5, 5), padding='same'))model.add(Activation('tanh'))model.add(UpSampling2D(size=(2, 2)))model.add(Conv2D(3, (5, 5), padding='same'))model.add(Activation('tanh'))return model
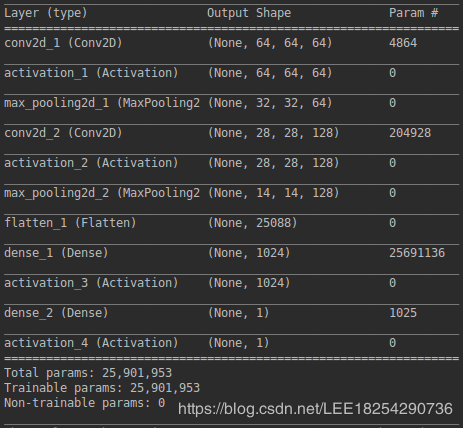
def discriminator_model():model = Sequential()model.add(Conv2D(64, (5, 5), padding='same', input_shape=(64, 64, 3)))model.add(Activation('tanh'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Conv2D(128, (5, 5)))model.add(Activation('tanh'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten())model.add(Dense(1024))model.add(Activation('tanh'))model.add(Dense(1))model.add(Activation('sigmoid'))return model
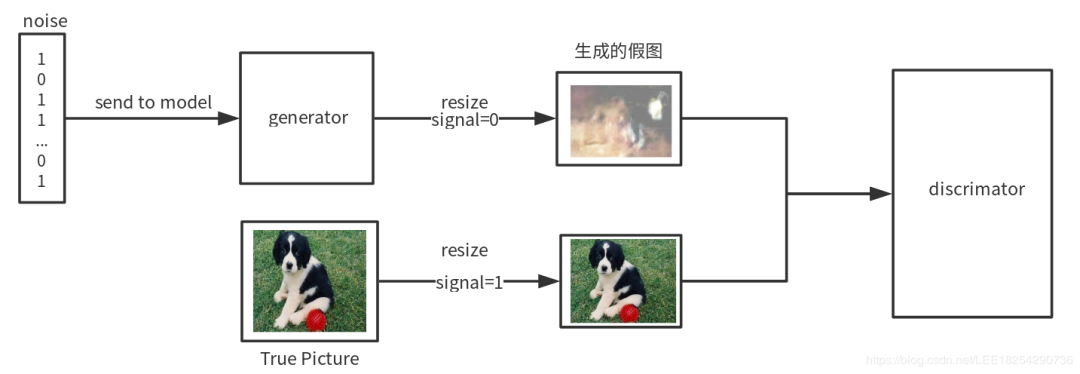
# 随机生成的1000维的噪声noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 1000))# X_train是训练的图片数据,这里取出一个batchsize的图片用于训练,这个是真图(64张)image_batch = X_train[index * BATCH_SIZE:(index + 1) * BATCH_SIZE]# 这里是经过生成器生成的假图generated_images = generator_model.predict(noise, verbose=0)# 将真图与假图进行拼接X = np.concatenate((image_batch, generated_images))# 与X对应的标签,前64张图为真,标签是1,后64张图是假图,标签为0y = [1] * BATCH_SIZE + [0] * BATCH_SIZE# 把真图与假图的拼接训练数据1送入判别器进行训练判别器的准确度d_loss = discriminator_model.train_on_batch(X, y)
def generator_containing_discriminator(g, d):model = Sequential()model.add(g)# 判别器参数不进行修改d.trainable = Falsemodel.add(d)return model

# 训练一个batchsize里面的数据for index in range(int(X_train.shape[0]/BATCH_SIZE)):# 产生随机噪声noise = np.random.uniform(-1, 1, size=(BATCH_SIZE, 1000))# 这里面都是真图片image_batch = X_train[index*BATCH_SIZE:(index+1)*BATCH_SIZE]# 这里产生假图片generated_images = g.predict(noise, verbose=0)# 将真图片与假图片拼接在一起X = np.concatenate((image_batch, generated_images))# 前64张图片标签为1,即真图,后64张照片为假图y = [1] * BATCH_SIZE + [0] * BATCH_SIZE# 对于判别器进行训练,不断提高判别器的识别精度d_loss = d.train_on_batch(X, y)# 再次产生随机噪声noise = np.random.uniform(-1, 1, (BATCH_SIZE, 1000))# 设置判别器的参数不可调整d.trainable = False# ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××# 在此我们送入噪声,并认为这些噪声是真实的标签g_loss = generator_containing_discriminator.train_on_batch(noise, [1] * BATCH_SIZE)# ××××××××××××××××××××××××××××××××××××××××××××××××××××××××××# 此时设置判别器可以被训练,参数可以被修改d.trainable = True# 打印损失值print("batch %d d_loss : %s, g_loss : %f" % (index, d_loss, g_loss))
g_loss = generator_containing_discriminator.train_on_batch(noise, [1] * BATCH_SIZE)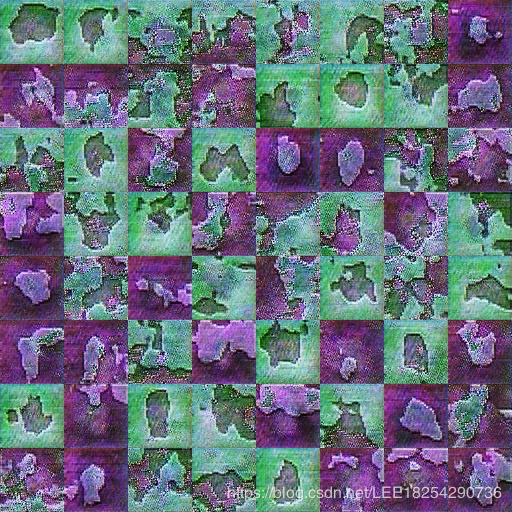
—完—