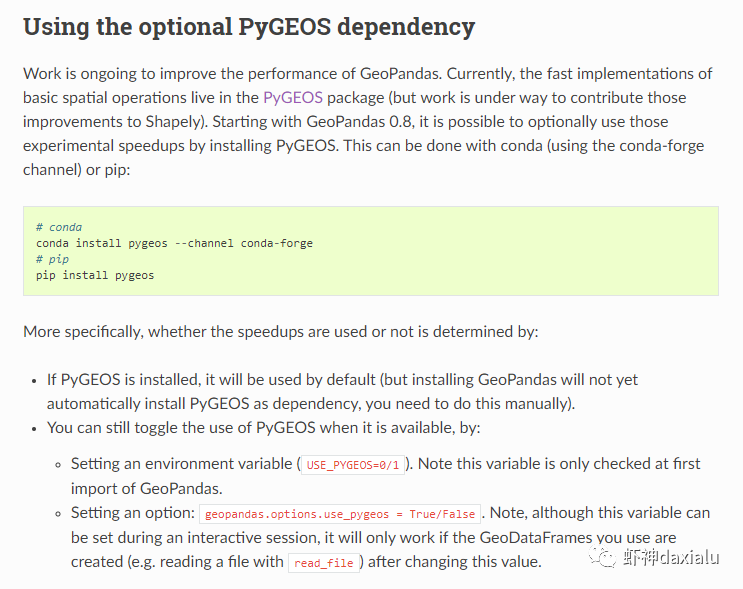
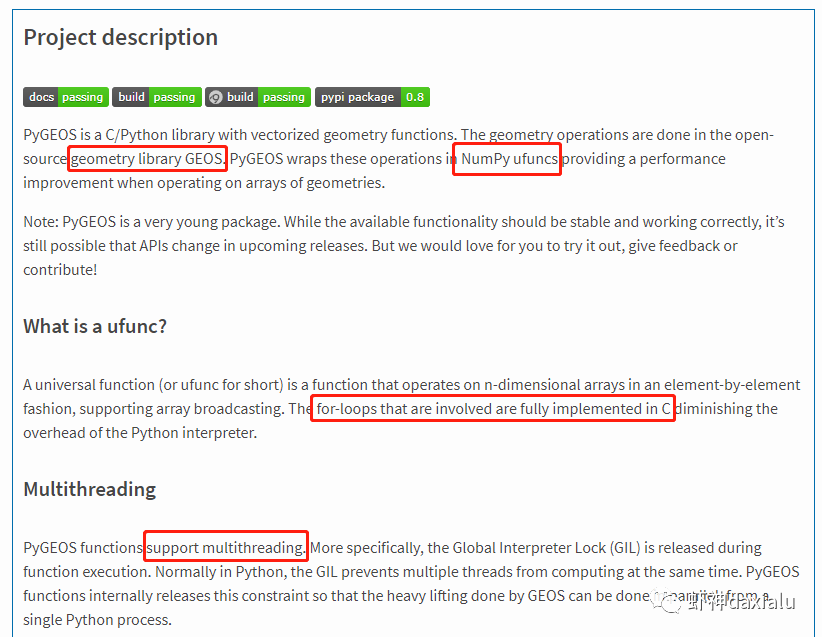
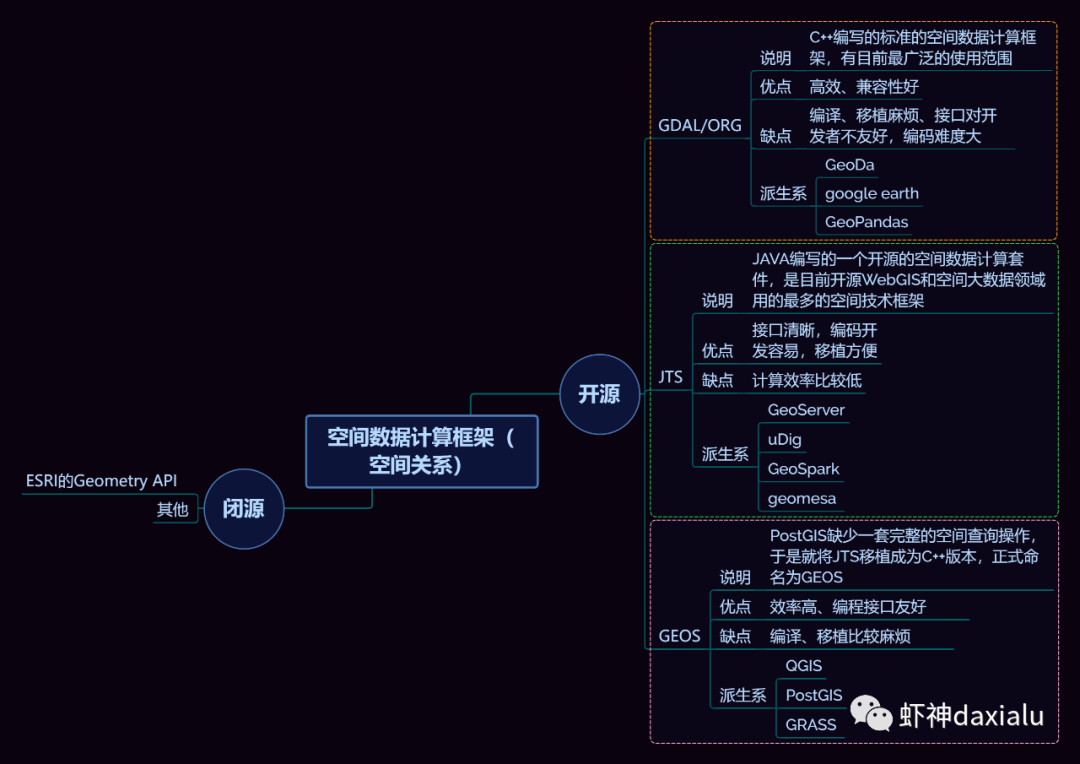
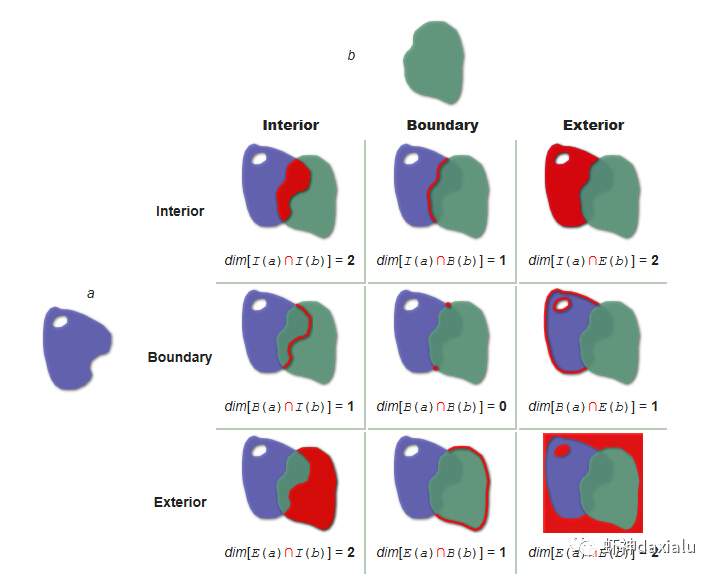
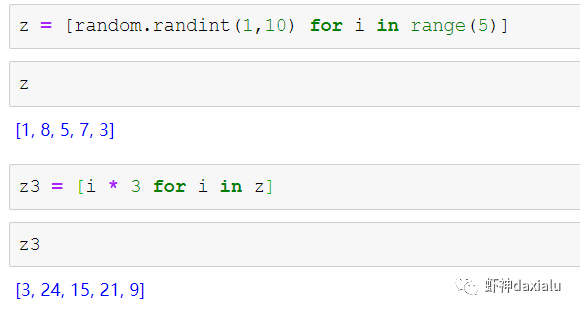
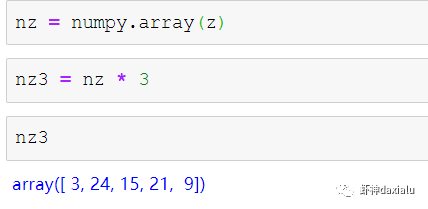
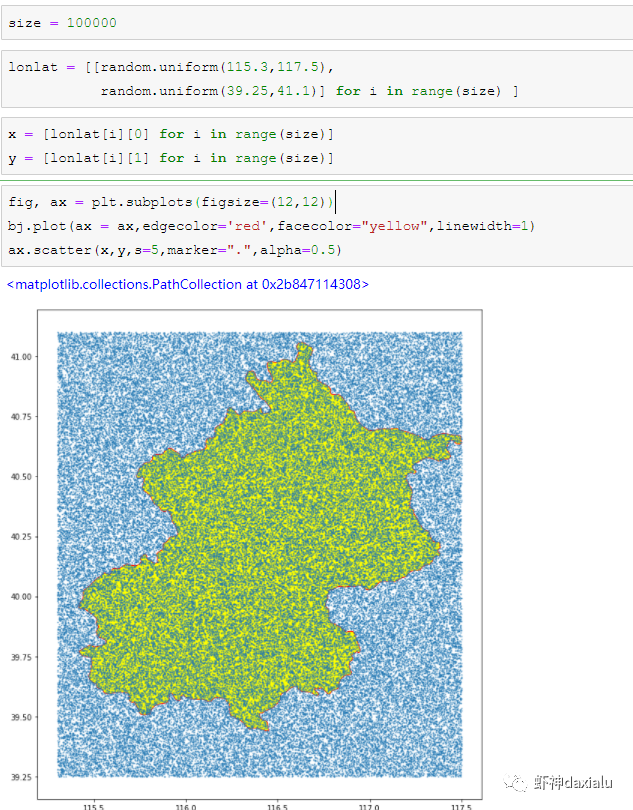
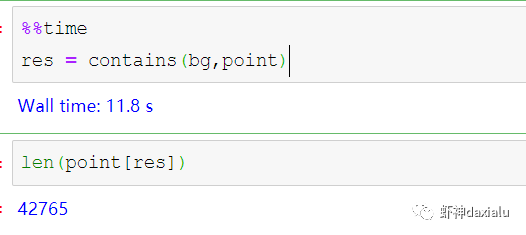
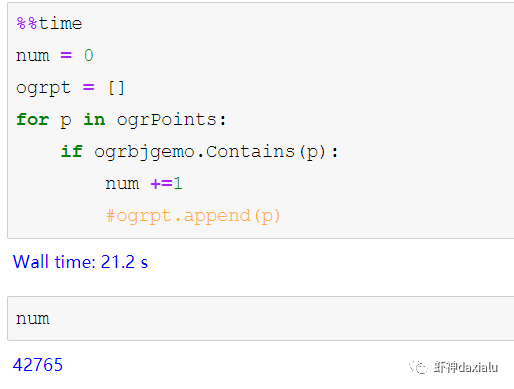
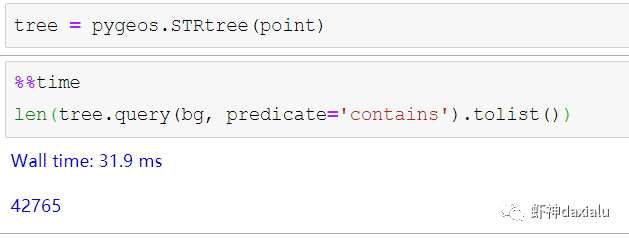
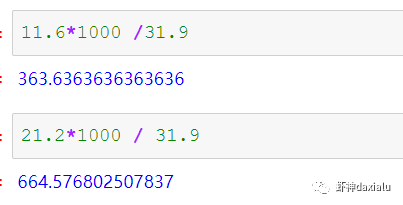
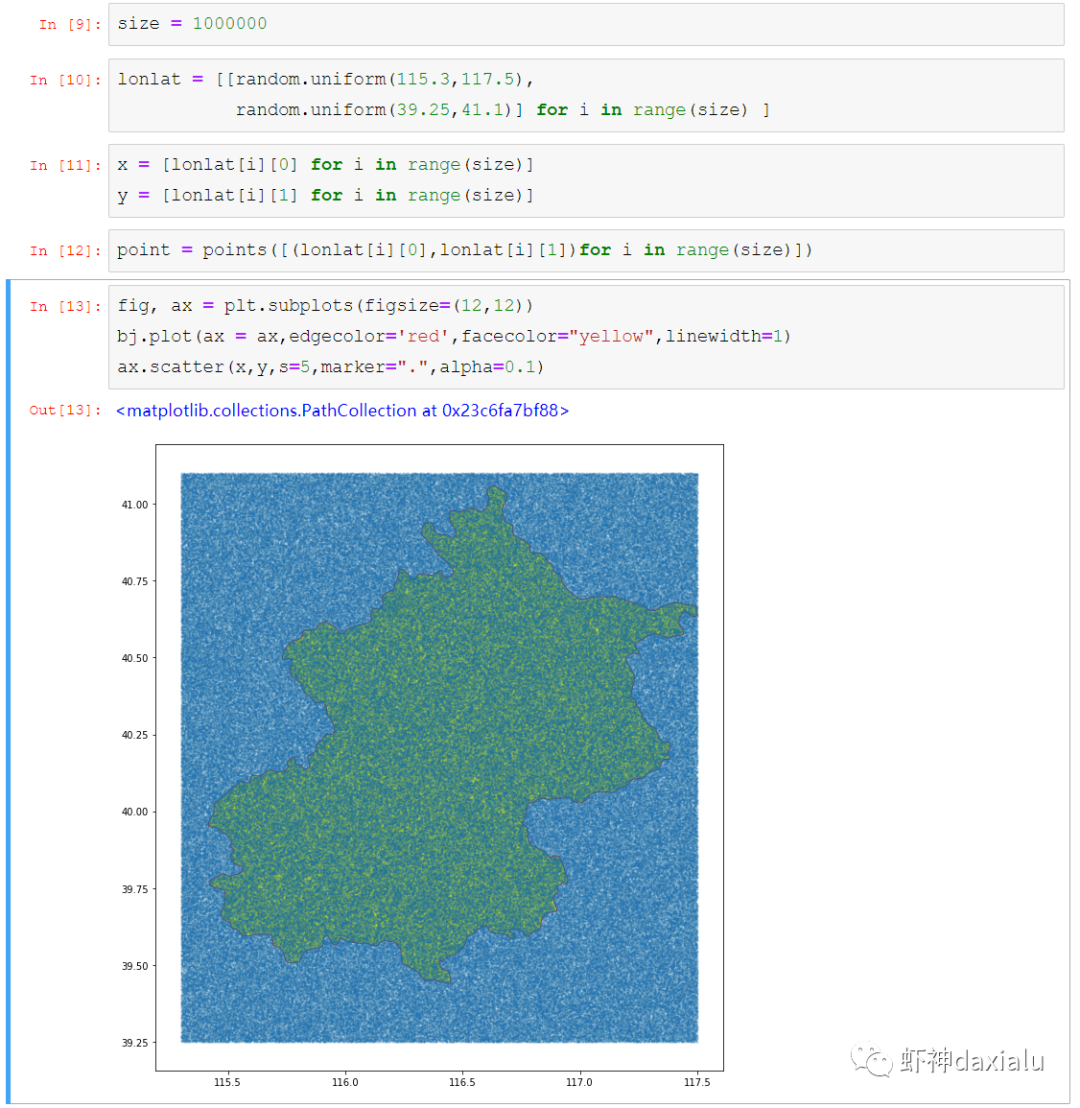
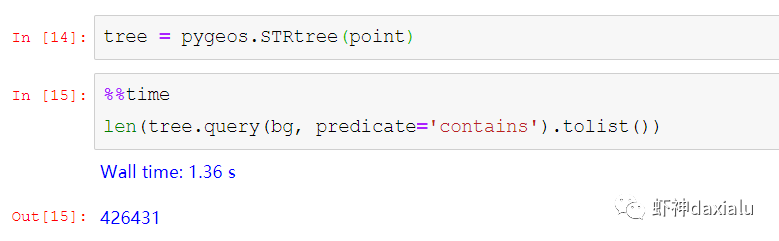
Python高性能空间数据计算包:PyGEOSPython大数据分析关注共 2163字,需浏览 5分钟 ·2021-04-20 01:58 今天早上在查阅GeoPandas文档的时候,发现从0.8版本开始,多了一个新特性:可以在GeoPandas进行空间运算的时候,选用PyGEOS包来实现了。算法渣渣虾看见这个选项的时候,当时的表情那是:好吧,有同学不知道为什么虾神会如此惊讶,因为这个库实在是太流弊了……今天我们就来介绍一下这个神奇的高性能空间数据计算包:PyGEOS话说,对速度的追求,是人类的本能:当然,你可以追求更快,自然也可以追求更慢……但是在对数据进行计算的时候,无疑我们是追求更高更快更强的……而这个包,敢叫做“高性能”,自然有它的两把刷子。我们先来看看官方文档对它的描述:虾神大白话解释如下(英文好的同学自行去读官方文档):第一点,PyGEOS这个包,底层的计算,用的GEOS的空间关系来进行计算,好吧,我知道有同学继续会问,啥是GEOS呢?这个说来就话长了,看下面这张图:闭源的先不看,主要看开源的部分,通常说的就是C/C++写的速度快,但是对于码农来说很不友好,反之JAVA写的,对码农友好,但是速度效率又不咋地……所以,综合了二者的优点以及缺点之和,就出现Geos这个东西……它有着C++底层的运行速度,但是在API保留了JAVA编码友好的特点——but,二者的缺点也一并保留了。目前用GEOS比较出名GIS软件,就是QGIS平台。GEOS搞出了空间关系计算里面最出名的入门图DE-9IM(Dimensionally Extended nine-Intersection Model (DE-9IM),用于描述两个几何图形空间关系:——言归正传,回到PyGeos。因为PyGEOS底层用的是GEOS,所以它具备了空间计算的各种基本以及标准的功能。第二点,PyGEOS计算操作,利用的是numpy的ufunc模式进行编码——所谓的ufunc模式,是一种在n维数组上,以逐个元素处理的方式运行的函数,支持数组广播(广播是指 NumPy 在算术运算期间处理不同形状的数组的能力)。它的机制是使用C语言对底层for循环进行了重写,从而减少了Python解释器的开销。举个例子:传统的迭代计算,比如我这有一个5个元素组成的数组,要把每个元素扩大3倍,正常的代码写法应该是通过for循环,一个个元素来处理:但是在Numpy里面,直接用ufunc方式来实现,直接在数组上乘以3,得到的结果是每个元素依此乘以3了:numpy的速度之所以比传统Python数组快那么多,有个核心原理就是他的ufunc,采用的是C重写了底层,不需要在Python那个蜗牛一样的解释器里面去运行,而PyGEOS 也用了这个原理,来实现快速计算。第三点就是PyGEOS支持多线程。原理就是它在函数执行期间主动干掉了GIL(Global Interpreter Lock :全局解释器锁定)。GIL这个东东是C语言里面的一个特性,而我们的CPython天生就带着这个东西出现了(相对的Jython就么有GIL),它主要的作用就是一个全局排他锁,主要是防止多线程并发执行机器码(C语言官方的解释是为了解决线程间数据一致性和状态同步的困难,而解决思路很粗暴:特么我加一把锁锁起来,你们之间就无法同步了,自己跑自己的进程完事——完美解决)。而在 PyGeos中,因为用的是C语言重新写的底层,所以在底层函数在内部释放了此约束,带来的结果就是通过单个Python进程就可以并行完成GEOS计算的任务。下面我们来看看PyGEOS的车速到底有多快:首先,以北京周边为范围,生成了10万个随机点:然后我们分别用PyGEOS和GDAL迭代的方式,来进行一个包含查询:恩,花了11秒,查出来了42765个——好像不怎么快嘛。接下去,我们用GDAL/OGR的方式来做一下:在OGR下面,用了差不多要比PyGEOS多用2倍的时间!!效果卓然拔群!恩,Python本来就比较慢……这个是共识,但是这才10万个点,就算快也得11秒,那也太慢了……还有快点的方法么?做为程序员,当然不能说有问题:下面我们来看,空间数据计算加速的主要方法之一:空间索引——PyGEOS的空间索引能力:——见证奇迹的时刻:只用了39ms!比自身直接查询快了363倍,而比用GDAL/OGR迭代快了664倍。我们来弄个大点的数据,比如100万个点:完成了100万点的包含查询,查询出来了42万6431条数据,耗时为1.36秒(好吧,我觉得有这个速度已经很快,但是还有同学说有些慢,因为我们在这里不是对标以快为标准的数据库——如果是空间数据库,千万点级别的查询,可以控制在零点几秒以内……这个我们就不对标了——别忘记了,我们这是在以慢出名的Python里面)本节打完收工,下一节我们看看在GeoPandas里面怎么用PyGEOS· 推荐阅读 ·关于pip的15个使用小技巧秀啊,用Python快速开发在线数据库更新修改工具99%的Python用户都不知道的f-string隐秘技巧 浏览 55点赞 评论 收藏 分享 手机扫一扫分享分享 举报 评论图片表情视频评价全部评论推荐 Cubert高性能计算引擎Cubert 是一个用于复杂大数据分析的高性能计算引擎。这是为分析师和数据科学家编写的一个框架,提供Cubert高性能计算引擎Cubert是一个用于复杂大数据分析的高性能计算引擎。这是为分析师和数据科学家编写的一个框架,提供“手动编写Java程序的所有效率优势,并提供了一个简单的、类似脚本的用户接口,用于解决各种统计、分析和AMD:高性能计算 (HPC)架构师技术联盟0MPI.NET高性能计算框架.Net实现的MPI高性能计算框架AMD:高性能计算 (HPC)智能计算芯世界0Cinder Python高性能 Python 分支Cinder是Meta基于CPython3.10构建的内部自用高性能分支。Cinder针对性能进行了许多优化,包括JIT、延迟加载模块、预编译静态模块、字节码内联缓存、协程的即时评估,以及实验性字节码Cinder Python高性能 Python 分支Cinder 是 Meta 基于 CPython 3.10 构建的内部自用高性能分支。Cinder Numpile基于 LLVM 的科学计算 Python 包Numpile是极小的,由千行Python代码构成的,基于LLVM的数值科学计算工具。from numpile import autojit@autojitdef dot(a, b): c = Numpile基于 LLVM 的科学计算 Python 包Numpile 是极小的,由千行 Python 代码构成的,基于 LLVM 的数值科学计算工具。fr收藏:应用场景高性能测试方法(高性能计算)智能计算芯世界0点赞 评论 收藏 分享 手机扫一扫分享分享 举报









 下载APP
下载APP