
【机器学习】深度剖析 LightGBM vs XGBOOST 哪个更胜一筹
今天就 LightGBM 和 XGBOOST 放在一起对比学习下,以便加深印象。
写在前面
作为一个机器学习研习者,大概会了解 Boosting Machines 及其功能。Boosting Machines 的发展从 AdaBoost 开始,发展到一度很受欢迎的 XGBOOST,因其非常强大而成为在 Kaggle 上赢得比赛的常用算法。但在大量的数据的情况下,XGBOOST 也需要很长时间来训练。
另外一个强大的集成算法 Light Gradient Boosting,他是一种怎样的提升机器算法?是否优于 XGBOOST?这是很多初学者在刚接触这两个算法时,通常是比较迷茫的。
接下来我们就来一起研习 LightGBM 相关问题。并深度对比分析它与XGBOOST的优劣。
01 什么是LightGBM
LightGBM 是一种基于决策树算法的快速、分布式、高性能梯度提升框架,用于排序、分类和许多其他机器学习任务。
虽然它同样是基于决策树算法,而它以最佳拟合方式分割树的叶子,而其他提升算法则是按深度或级别而不是按叶分割树。因此,当在 LightGBM 中的同一片叶子上生长时,leaf-wise 算法比 level-wise 算法在计算损失时将减少的更多,从而达到更好的精度,这是任何现有的 boosting 算法都很难实现的。此外,它的速度非常快,这也是 "light "这个词的由来。
下面是 LightGBM 和 XGBOOST 的树模型生长的示意图,从图中可以清楚地看到它们之间的差异。
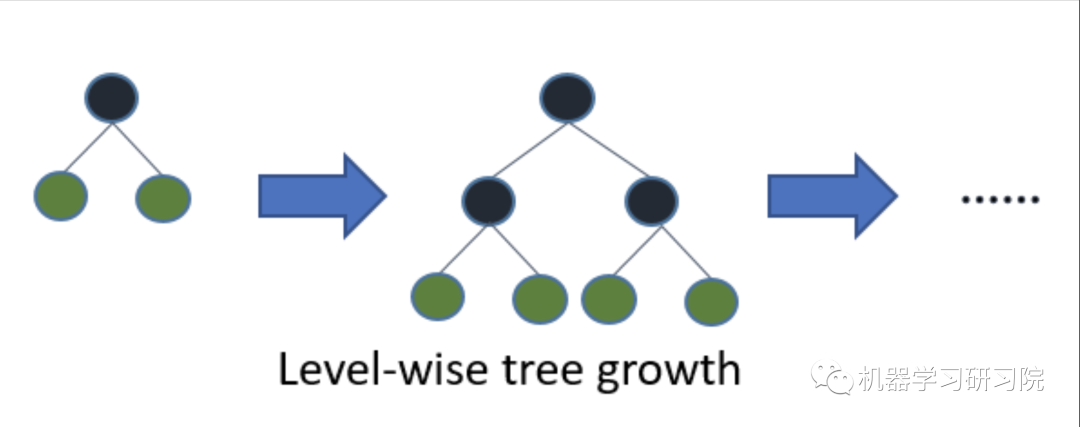
XGBOOST 中的 level-wise 树生长。
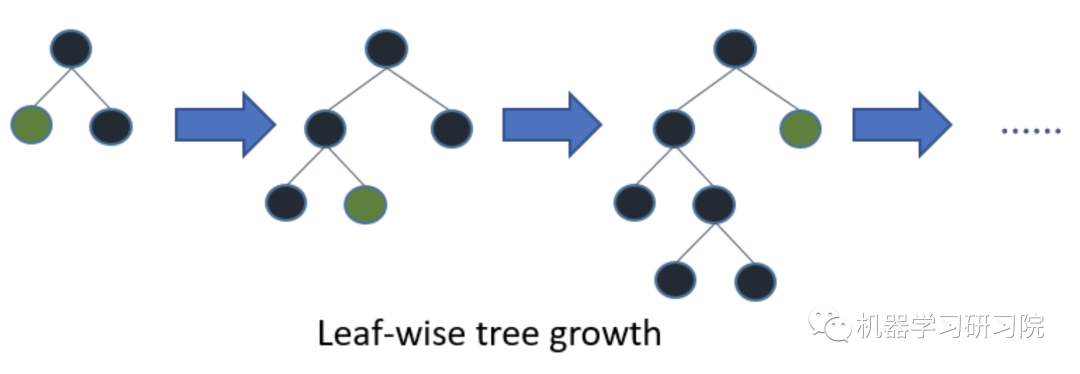
LightGBM 中的leaf-wise 的树生长。
虽然逐叶拆分会导致复杂性增加,并可能导致过度拟合,但可以通过调整参数 max-depth 来克服该问题,该参数设定树叶子节点将发生拆分的深度。
02 安装 Light GBM
下面,我们一起安装 LightGBM 及使用其建立模型的步骤。我们会将其得到的结果与 XGBOOST 的结果进行比较,这样可以对 LightGBM 模型理解更加深刻。
Windows
事先安装 git for windows[1] , cmake[2]
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake -DCMAKE_GENERATOR_PLATFORM=x64 ..
cmake --build . --target ALL_BUILD --config Release
exe 和 dll 将在 LightGBM/Release 文件夹中。
Linux
Light GBM 使用 cmake 构建。
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake ..
make -j4
OSX
LightGBM 依赖 OpenMP 编译,Apple Clang 不支持,请改用 gcc/g++。
brew install cmake
brew install gcc --without-multilib
git clone --recursive https://github.com/Microsoft/LightGBM
cd LightGBM
mkdir build
cd build
cmake ..
make -j4
03 XGBOOST 优势
这种算法在预测模型中引入了提升能力。当我们继续深入探索其高精度背后机制时,会发现不少优点:
引入正则化
标准的 GBM 实现没有像 XGBOOST 那样的正则化,因此它也有助于减少过拟合。
XGBOOST 也被称为 "正则化提升" 技术。
并行处理
XGBOOST 实现了并行处理,并且与 GBM 相比速度要快得多。
XGBOOST 还支持在 Hadoop 上实现。
高灵活性
XGBOOST 允许用户定义自定义优化目标和评估标准,这使得模型的限制更小。
处理缺失值
XGBOOST 有一个内置的方法来处理缺失值。并且可以通过提供与其他观察不同的值并将其作为参数传递,以此处理缺失值。
树剪枝
当一个 GBM 在分裂中遇到负损失时,它会停止分裂一个节点。因此它更像是一种贪心算法。
另一方面,XGBOOST 使树分裂达到指定的 max_depth,然后开始向后修剪树并移除没有正增益的分枝。
另一个优点是,有时负损失的拆分可能会跟随正损失的拆分 +10。GBM 会在遇到 -2 时停止。但是 XGBOOST 会更深入,它将看到分裂的 +8 的组合效果并保留两者。
内置交叉验证
XGBOOST 允许在提升过程的每次迭代中运行交叉验证,因此很容易在单次运行中获得准确的最佳提升迭代次数。
这与 GBM 不同,在 GBM 中必须运行网格搜索并且只能测试有限的值。
继续现有模型
用户可以从上次运行的最后一次迭代开始训练 XGBOOST 模型。这在某些特定应用中可能具有显着优势。
04 LightGBM 的优势
更快的训练速度和更高的效率
LightGBM 使用基于直方图的算法(如HGBT),即将连续的特征值存储到离散的 bin 中,从而加快了训练过程。
较低的内存使用量
将连续值替换为离散的 bin,从而降低内存使用量。
比其他 boosting 算法准确性更好
它通过遵循叶方式拆分方法而不是级别方法生成更复杂的树,这是实现更高准确性的主要因素。然而,它有时会导致过度拟合,这可以通过设置 max_depth 参数来避免。
与大型数据集的兼容性
与 XGBOOST 相比,在 大型数据集 上表现更加出色。因为其支持并行学习,显著减少训练时间。
05 LightGBM的参数
在开始构建第一个 LightGBM 模型之前,我们先一起看看 LightGBM 的一些重要参数,以便更好地了解其底层逻辑。
task:value = train,options = train,prediction。指定我们希望执行的任务是训练还是预测。 application:default=regression,type=enum,options=options regression:执行回归任务 binary : 二元分类 multiclass:多类分类 lambdarank : lambdarank 应用程序 data:type=string;训练数据,LightGBM 将根据这些数据进行训练。 num_iterations:default=100,type=int。要执行的 boosting 迭代次数。 num_leaves:default = 31,type=int。叶一个树的数量。 device:default= cpu;options = gpu, cpu。我们要在其上训练模型的设备。可选择 GPU 以加快训练速度。 max_depth:指定树将生长的最大深度。该参数用于处理过拟合。 min_data_in_leaf:一片叶子中的最小数据数。 feature_fraction:default =1。指定每次迭代要采用的特征分数 bagging_fraction:default = 1。指定每次迭代要使用的数据比例,通常用于加速训练并避免过度拟合。 min_gain_to_split:default = 0.1。执行分裂的最小增益。 max_bin:存储特征值的最大 bin 数量。 min_data_in_bin:一个 bin 中的最小数据数。 num_threads:default=OpenMP_default,type=int。LightGBM 的线程数。 label:type=string。指定标签列。 categorical_feature:type=string。指定我们要用于训练模型的分类特征。 num_class:default=1,type=int。仅用于多类分类。
06 调参对比
LightGBM调参的一般方法
对于基于决策树的模型,调参的方法都是大同小异。一般都需要如下步骤:
首先选择较高的学习率(大概0.1附近),以加快收敛速度; 对决策树基本参数调参,以提供模型精度; 正则化参数调参,以防止模型过拟合; 最后降低学习率,最后提高准确率。
LightGBM 使用逐叶分割而不是深度分割,这使它能够更快地收敛,但也会导致过度拟合。所以这里有一个快速指南来调整 LightGBM 中的参数。
default=
- {l2 for regression},
- {binary_logloss for binary classification},
- {ndcg for lambdarank},
- type=multi-enum,
options=l1, l2, ndcg, auc, binary_logloss, binary_error …
为了更好的拟合
num_leaves:此参数用于设置要在树中形成的叶子数。 num_leaves和max_depth之间的理论上关系是num_leaves= 2^(max_depth)。然而这并不太适合 Light GBM ,因为分裂发生在叶方向而不是深度方向。因此num_leaves必须设置小于2^(max_depth),否则可能会导致过拟合。Light GBM 在num_leaves和max_depth之间没有直接关系,因此两者不能相互关联。min_data_in_leaf:也是处理过拟合的重要参数之一。将其值设置得较小可能会导致过拟合。大型数据集中,它的值应该是数百到数千,具体需要根据实际情况调整。 max_depth:它指定树可以生长的最大深度。
为了更快的速度
bagging_fraction:用于执行袋装以获得更快的结果 feature_fraction:设置要在每次迭代中使用的特征的分数 max_bin:较小的 max_bin值可以节省很多时间,因为它将特征值存储在离散的容器中,计算成本较低。
为了更好的准确性
使用更大的训练数据。 num_leaves:将其设置为高值会产生更深的树,并提高准确性,但会导致过度拟合。因此,不优选其较高的值。 max_bin:将其设置为高值与增加 num_leaves值产生的效果类似,也会减慢我们的训练过程。
XGBOOST 调参的一般方法
我们将在这里使用类似于 GBM 的方法。要执行的各个步骤是:
选择一个比较高的学习率。一般来说,0.1 的学习率是较为常用的,而根据不同的问题,学习率的选用范围一般在 0.05 到 0.3 之间。 接下来需确定此学习率的最佳集成树数。XGBOOST 有一个非常有用的函数,称为“cv”,它在每次提升迭代时执行交叉验证,从而返回所需的最佳树数。 调整特定于树的参数 ( max_depth、min_child_weight、gamma、subsample、colsample_bytree)以决定学习率和树的数量。调整正则化参数( lambda、alpha),这有助于降低模型复杂性并提高性能。降低学习率并决定最优参数。
07 应用对比
现在我们通过将这两种算法应用于数据集,通过比较其性能优劣,以此来比较 LightGBM 和 XGBoost 两个算法。
该数据集包含来自不同国家的个人信息。其目标是根据其他可用信息预测一个人的年收入是小于或等于50k还是大于50k。该数据集由 32561 个样本和 14 个特征组成。需要数据集的读者在公众号【机器学习研习院】后台联系作者获取。
数据探索
# 导入库
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import lightgbm as lgb
import xgboost as xgb
# 使用pandas加载我们的训练数据集'adult.csv',名称为'data'
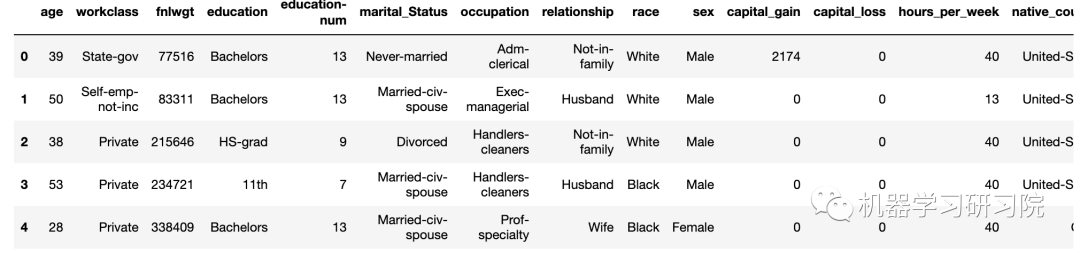
data=pd.read_csv('adult.csv',header=None)
# 为列分配名称
data.columns=['age','workclass','fnlwgt','education',
'education-num','marital_Status','occupation',
'relationship','race','sex','capital_gain',
'capital_loss','hours_per_week','native_country','Income']
data.head()
对目标变量进行编码
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
l=LabelEncoder()
l.fit(data.Income)
l.classes_
array([' <=50K', ' >50K'], dtype=object)
一个热编码的分类特征
one_hot_workclass=pd.get_dummies(data.workclass)
one_hot_education=pd.get_dummies(data.education)
one_hot_marital_Status=pd.get_dummies(data.marital_Status)
one_hot_occupation=pd.get_dummies(data.occupation)
one_hot_relationship=pd.get_dummies(data.relationship)
one_hot_race=pd.get_dummies(data.race)
one_hot_sex=pd.get_dummies(data.sex)
one_hot_native_country=pd.get_dummies(data.native_country)
# 删除分类特征
data.drop(['workclass','education','marital_Status',
'occupation','relationship','race','sex',
'native_country'],axis=1,inplace=True)
# 与我们的数据集'data'合并一个热编码特性
data=pd.concat([data,one_hot_workclass,one_hot_education,
one_hot_marital_Status,one_hot_occupation,
one_hot_relationship,one_hot_race,one_hot_sex,
one_hot_native_country],axis=1)
# 删除dulpicate列
_, i = np.unique(data.columns, return_index=True)
data=data.iloc[:, i]
data
这里我们的目标变量是"Income",其值为1或0。然后将数据分为特征数据集x和目标数据集y。
x=data.drop('Income', axis=1)
y=data.Income
# 将缺失的值输入到目标变量中
y.fillna(y.mode()[0],inplace=True)
# 现在将我们的数据集分为test和train
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=.3)
XGBOOST 应用
数据存储在一个 DMatrix 对象中,参数 label 用于定义结果变量。
dtrain=xgb.DMatrix(x_train,label=y_train)
dtest=xgb.DMatrix(x_test)
#设置xgboost
parameters={'max_depth':7, 'eta':1, 'silent':1,
'objective':'binary:logistic',
'eval_metric':'auc','learning_rate':.05 }
# 训练模型
num_round=50
from datetime import datetime
start = datetime.now()
xg=xgb.train(parameters,dtrain,num_round)
stop = datetime.now()
# 模型执行时间
execution_time_xgb = stop-start
execution_time_xgb
datetime.timedelta(seconds=3,
microseconds=721741)
datetime.timedelta( , , ) 表示( 天, 秒, 微秒)。现在用模型对测试集进行预测。
ypred=xg.predict(dtest)
ypred
array([0.0600442, 0.1247908, 0.6246425, ...,
0.157481 , 0.0610904, 0.6457621 ],
dtype=float32)
将概率转换为1 或 0 ,将阈值设置为 0.5 ,并模型的计算精度。
for i in range(0,9769):
if ypred[i]>=.5:
ypred[i]=1
else:
ypred[i]=0
from sklearn.metrics import accuracy_score
accuracy_xgb = accuracy_score(y_test,ypred)
accuracy_xgb
0.8626266762206981
LightGBM 应用
准备训练数据及设置 LightGBM 的参数,并训练模型。这里将 XGBOOST 和 LightGBM 中的 max_depth 设置均为 7,这样运用控制变量思想以更好地比较两个算法。
train_data=lgb.Dataset(x_train,label=y_train)
param = {'num_leaves':150, 'objective':'binary',
'max_depth':7,'learning_rate':.05,'max_bin':200}
param['metric'] = [' auc', 'binary_logloss']
num_round=50
start=datetime.now()
lgbm=lgb.train(param,train_data,num_round)
stop=datetime.now()
#模型执行时间
execution_time_lgbm = stop-start
execution_time_lgbm

在测试集上预测数据
ypred2=lgbm.predict(x_test)
# ypred2[0:5]
# 显示前 5 个预测
# 将概率转换为 0 或 1
for i in range(0,9769):
if ypred2[i]>=.5: # 将阈值设置为 .5
ypred2[i]=1
else:
ypred2[i]=0
# 计算精度
accuracy_lgbm =accuracy_score(ypred2,y_test)
y_test.value_counts()
0 7376
1 2393
Name: Income, dtype: int64
计算 XGBOOST 的 roc_auc_score
from sklearn.metrics import roc_auc_score
auc_xgb = roc_auc_score(y_test,ypred)
auc_xgb
0.7670270211471818
计算 LightGBM 的 roc_auc_score
auc_lgbm = roc_auc_score(y_test,ypred2)
auc_lgbm
0.761978912192376
comparison_dict = {'accuracy score':(accuracy_lgbm,accuracy_xgb),
'auc score':(auc_lgbm,auc_xgb),
'execution time':(execution_time_lgbm,execution_time_xgb)}
# 创建一个数据帧'comparison_df'来比较Lightgbm和xgb的性能。
comparison_df =DataFrame(comparison_dict)
comparison_df.index = [ 'LightGBM', 'xgboost']
性能对比
通过在 XGBOOST 上应用 LightGBM,准确性和 auc 分数仅略有增加,但训练过程的执行时间存在显着差异。LightGBM 比 XGBOOST 快近 7 倍,并且在处理大型数据集时是一种更好的方法。
当在限时比赛中处理大型数据集时,这将是一个巨大的优势。
08 写在最后
本文简单介绍了 LightGBM 的基本概念。LightGBM 算法除了比 XGBOOST 更准确和更省时外,还优于现有的其他 boosting 算法。比较建议你在使用其他 boosting 算法时,也尝试使用 LightGBM 算法,然后比较它们的优劣。
参考资料
git for windows: https://git-scm.com/download/win
[2]cmake: https://cmake.org/
往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: