
Fluentd 日志拆分
大部分 Kubernetes 应用,我们都会将不同类型的日志记录到 stdout 中,比如在《Fluentd 简明教程》中提到的应用日志和访问日志,这两者都是非常重要的信息,因为他们的日志格式不一样,所以我们需要对他们分别进行解析,这就需要我们使用到 Fluentd 的一些插件来配合。本文我们将介绍如何将这些日志拆分为并行的日志流,以便可以进一步处理它们。
设置
同样使用前面我们配置的仓库 https://github.com/r1ckr/fluentd-simplified,Clone 后会得到如下所示的目录结构:
fluentd/
├── etc/
│ └── fluentd.conf
├── log/
│ └── kong.log
└── output/
其中 output/ 目录是 fluentd 最后输出文件的地方,在 log/kong.log 中,里面是一些运行 kong 容器的日志,日志格式如下所示:
{
"log":"2019/07/31 22:19:52 [notice] 1#0: start worker process 32\n",
"stream":"stderr",
"time":"2019-07-31T22:19:52.3754634Z"
}
etc/fluentd.conf 就是我们的 fluentd 配置文件,里面包含输入和输出配置,首先我们先来运行 fluentd 容器。
# Input
<source>
@type tail
path "/var/log/*.log"
tag "ninja.*"
read_from_head true
<parse>
@type "json"
time_format "%Y-%m-%dT%H:%M:%S.%NZ"
time_type string
parse>
source>
# Filter (grep)
<filter ninja.var.log.kong** >
@type grep
<regexp>
key log
pattern /HTTP/
regexp>
filter>
# Output
<match **>
@type file
path /output/example
append true
<buffer>
timekey 1d
timekey_use_utc true
timekey_wait 1m
buffer>
match>
运行 fluentd
使用下面的命令在项目根目录下面启动一个 fluentd 的 Docker 容器:
$ docker run -u root -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.11-debian-1 -c /fluentd/etc/fluentd-simplified-finished.conf -v
注意上面的运行命令和我们要挂载的卷
etc/是挂载在容器内部的/fluentd/etc/目录下的,以覆盖 fluentd 的默认配置。log/挂载到/var/log/,最后在容器里面挂载到/var/log/kong.log。output/挂载到/output,以便能够看到 fluentd 写入磁盘的内容。
运行容器后,会出现如下所示的信息:
2020-10-16 03:35:28 +0000 [info]: #0 fluent/log.rb:327:info: fluentd worker is now running worker=0
这意味着 fluentd 已经启动并运行了。现在我们知道了 fluentd 是如何运行的了,接下来我们来看看配置文件的一些细节。
拆分日志
现在我们的日志已经在 fluentd 中工作了,我们可以开始对它做一些更多的处理。
现在我们只有一个输入和一个输出,所以我们所有的日志都混在一起,我们想从访问日志中获取更多的信息。要做到这一点,我们首先要确定哪些是访问日志,比方说通过 /^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/ (将查找以 IP 开头的行)来 grepping 我们所有的访问日志,并将排除应用日志,配置如下所示。
<match ninja.var.log.kong**>
@type rewrite_tag_filter
<rule>
key log
pattern /^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/
tag access.log.${tag}
rule>
<rule>
key log
pattern .*
tag app.log.${tag}
rule>
match>
上面的配置信息:
ninja.var.log.kong开头的标签。@type rewrite_tag_filter:我们将要使用的插件类型。第一个 /^(?:[0-9]{1,3}\.){3}[0-9]{1,3}.*/正则表达式,对于找到的每个日志行,添加一个access.log.的标签前缀,比如access.log.ninja.var.log.kong.log这样的标签。第二个 app.log这样的标签前缀,类似于app.log.ninja.var.log.kong.log这样的标签。
通过这个配置,我们在管道中增加了一个新的配置。
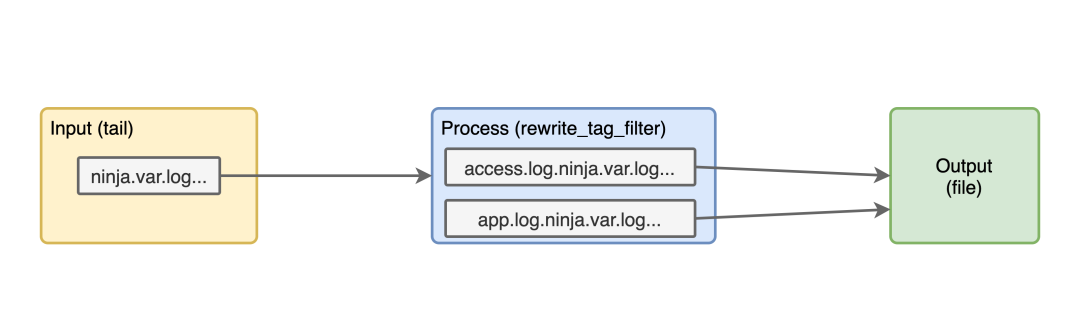
现在,如果我们去运行容器则会报错,因为 rewrite_tag_filter 不是 fluentd 的核心插件,所以我们在运行 fluentd 之前先安装它。
$ docker run -u root -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.11-debian-1 bash -c "gem install fluent-plugin-rewrite-tag-filter && fluentd -c /fluentd/etc/fluentd.conf -v"
我们在运行 fluend 命令之前先执行 gem install fluent-plugin-rewrite-tag-filter 来安装插件。
现在我们应该在输出日志中看到一些不同的新了,让我们检查一下之前同样的6行日志。
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:16 [warn] 35#0: *4 [lua] globalpatches.lua:47: sleep(): executing a blocking 'sleep' (0.004 seconds), context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:16 [warn] 33#0: *2 [lua] globalpatches.lua:47: sleep(): executing a blocking 'sleep' (0.008 seconds), context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:17+00:00 app.log.ninja.var.log.kong.log {"log":"2020/05/10 17:04:17 [warn] 32#0: *1 [lua] mesh.lua:86: init(): no cluster_ca in declarative configuration: cannot use node in mesh mode, context: init_worker_by_lua*\n","stream":"stderr"}
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:04:30 +0000] \"GET / HTTP/1.1\" 404 48 \"-\" \"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:05:38+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:05:38 +0000] \"GET /users HTTP/1.1\" 401 26 \"-\" \"curl/7.59.0\"\n","stream":"stdout"}
2020-05-10T17:06:24+00:00 access.log.ninja.var.log.kong.log {"log":"35.190.247.57 - - [10/May/2020:17:06:24 +0000] \"GET /users HTTP/1.1\" 499 0 \"-\" \"curl/7.59.0\"\n","strea
与之前唯一不同的是,现在访问日志和应用日志有不同的标签l ,这对它们做进一步的处理是非常有用的。
解析访问日志
接下来我们来添加一个解析器插件来从访问日志中提取有用的信息,在 rewrite_tag_filter 之后使用这个配置。
<filter access.log.ninja.var.log.kong.log>
@type parser
key_name log
<parse>
@type nginx
parse>
filter>
我们来分析下这个配置:
我们明确地过滤了 access.log.ninja.var.log.kong.log这个标签过滤器的类型是 parser我们将对日志内容的 log这个 key 的内容进行解析由于这些都是 nginx 的访问日志,所以这里我们使用 @type nginx的解析器进行解析。
这是我们的日志收集管道现在的样子。
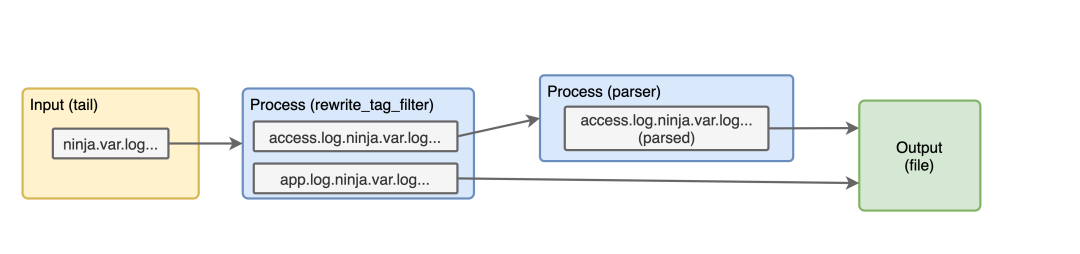
我们再重新运行 docker 容器,查看日志,Kong 的访问日志应该是这样的了。
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"remote":"35.190.247.57","host":"-","user":"-","method":"GET","path":"/","code":"404","size":"48","referer":"-","agent":"curl/7.59.0","http_x_forwarded_for":""}
这是之前日志中的第一个访问日志,标签是一样的,但是现在日志内容完全不同了,我们的键从 log 和 stream,变成了 remote、host、user、 method、path、code、size、referer、agent 和 http_x_forwarded_for,如果我们把这个日志输出到 elasticsearch 中,我们就可以通过method=GET 或者其他任何组合方式进行过滤了。
Geoip 插件
此外,我们还可以使用 geoip 插件应用到 remote 字段中,来获取访问我们接口的地理位置。配置如下所示:
# Geoip 过滤器
<filter access.log.ninja.var.log.kong.log>
@type geoip
# 指定一个或多个有 ip 地址的 geoip 查询字段
geoip_lookup_keys remote
# Set adding field with placeholder (more than one settings are required.)
<record>
city ${city.names.en["remote"]}
latitude ${location.latitude["remote"]}
longitude ${location.longitude["remote"]}
country ${country.iso_code["remote"]}
country_name ${country.names.en["remote"]}
postal_code ${postal.code["remote"]}
record>
# 避免 elasticsearch 的 stacktrace 错误
skip_adding_null_record true
filter>
再来分析下这个配置:
明确过滤 access.log.ninja.var.log.kong.log这个标签的日志。过滤器的类型是 geoip 我们将使用日志中的 remote 这个 key 来进行 geoip 查找 其余的都是标准配置
同样要在 docker 容器中使用 geoip 这个插件,我们需要首先安装,但是这个插件的安装稍微麻烦一点,因为我们需要安装一些 debian 依赖包,我们可以使用如下所示的命令来进行安装配置(当然也可以重新自定义一个 Docker 镜像):
$ docker run -u root -ti --rm \
-v $(pwd)/etc:/fluentd/etc \
-v $(pwd)/log:/var/log/ \
-v $(pwd)/output:/output \
fluent/fluentd:v1.11-debian-1 bash -c "apt update && apt install -y build-essential libgeoip-dev libmaxminddb-dev && gem install fluent-plugin-rewrite-tag-filter fluent-plugin-geoip && fluentd -c /fluentd/etc/fluentd.conf -v"
我们可以看到在启动命令中我们添加了额外的 apt 命令,并添加了一个 fluent-plugin-geoip 插件,运行该命令后,我们可以在日志中看到一些额外的字段,这就是 geoip 插件的配置结果:
2020-05-10T17:04:30+00:00 access.log.ninja.var.log.kong.log {"remote":"35.190.247.57","host":"-","user":"-","method":"GET","path":"/","code":"404","size":"48","referer":"-","agent":"curl/7.59.0","http_x_forwarded_for":"","city":"Mountain View","latitude":37.419200000000004,"longitude":-122.0574,"country":"US","country_name":"United States","postal_code":"94043"}
总结
在这篇文章中,我们使用 fluent-plugin-retwrite-tag-filter 插件来拆分我们的日志,并使用 fluent-plugin-geoip 插件来获取访问我们接口的客户端地理位置信息,fluentd 功能是非常强大的,有着丰富的插件可以帮助我们实现很多强大的需求。
原文链接:https://medium.com/swlh/fluentd-splitting-logs-2a778cd6bdfa
训练营推荐


 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习