
复旦大学自然语言处理实验室发布模型鲁棒性评测平台TextFlint
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
复旦大学自然语言处理实验室发布模型鲁棒性评测平台 TextFlint。该平台涵盖 12 项 NLP 任务,囊括 80 余种数据变形方法,花费超 2 万 GPU 小时,进行了 6.7 万余次实验,验证约 100 种模型,选取约 10 万条变形后数据进行了语言合理性和语法正确性人工评测,为模型鲁棒性评测及提升提供了一站式解决方案。
项目地址:
https://github.com/textflint
官方网站:
http://textflint.io/
论文链接:
https://arxiv.org/pdf/2103.11441.pdf (点击阅读原文获取)

引言
近年来,随着自然语言处理技术的不断突破,深度学习模型在各项 NLP 任务中的表现正在稳步攀升。2018 年 1 月,在斯坦福大学发起的 SQuAD 阅读理解评测任务中,来自微软亚洲研究院的自然语言计算组所提出的算法率先赶超了人类。短短三年后,微软的 DeBERTa 和谷歌的 T5+Meena 模型在包含了多种自然语言处理任务的综合评测集合 SuperGLUE 上再次超越了人类。近日 IBM 号称“首个能在复杂话题上与人类辩论的 AI 系统”的 Project Debater 登上了 Nature 杂志的封面,该系统在 78 类辩题中获得了接近人类专业辩手的平均评分。我们不禁要问,人类真的被打败了吗?
事实上,纵使这些 NLP 模型在实验数据集上的表现十分惊人,在实际应用中我们却很难感知到自然语言处理系统“超越人类”的语言理解水平。难倒这些看似“聪明”的模型,只需要一个简单的“逗号”,即便是基于赫赫有名的预训练语言模型 BERT 的算法也不例外。
例如,“汉堡很好吃薯条一般”对汉堡的评价是正面的,但当我们插入“,”时,一些模型就会将“汉堡很好吃,薯条一般”判别为对汉堡的负面评价。一个微小且无关紧要的改动就能使自然语言处理系统失效,诸如此类的例子屡见不鲜。


鲁棒性何为
为何大杀四方的优秀模型在纷繁复杂的现实场景中纷纷折戟沉沙?其中一个很重要的原因是此前缺乏对模型鲁棒性的重视和深入探讨,导致模型只能在特定语料中圈地为王,在模型的效果评测中也仅仅关心在特定测试语料上的性能。如何帮助模型走出这样的困局,给自然语言处理领域带来质的飞跃,是实现下一步技术发展的紧要任务。
鲁棒性是机器学习模型的一项重要评价指标,主要用于检验模型在面对输入数据的微小变动时,是否依然能保持判断的准确性,也即模型面对一定变化时的表现是否稳定。鲁棒性的高低直接决定了机器学习模型的泛化能力。在研究领域中,许多模型只能在某一特定的数据集上呈现准确的结果,却不能在其他数据集上复刻同样优异的表现,这就是由于模型对新数据中的不同过于敏感,缺乏鲁棒性。
在现实世界的应用场景中,模型要面对的是更加纷繁复杂的语言应用方式,待处理的数据里包含着更加庞杂的变化。一旦缺乏鲁棒性,模型在现实应用中的性能就会大打折扣。在测试数据集上获得高分是远远不够的,机器学习模型的设计目标是让模型在面对新的外部数据时依然维持精准的判断。因此,为了确保模型的实际应用价值,对模型进行鲁棒性评测是不可或缺的。

方法 & 实验
目前已有一些正在关注模型鲁棒性的工作,但大多只针对单个的 NLP 任务,或是只使用了少量的数据变形方法,缺乏系统性的工具集合。针对这一问题,复旦大学自然语言处理实验室展开了大规模的鲁棒性测评工作,在桂韬博士、王枭博士、张奇教授、黄萱菁教授的主导下,20 余位博士生和硕士生共同参与,历时 9 个月,开发了面向自然语言处理的多语言鲁棒性测评一站式平台 TextFlint。
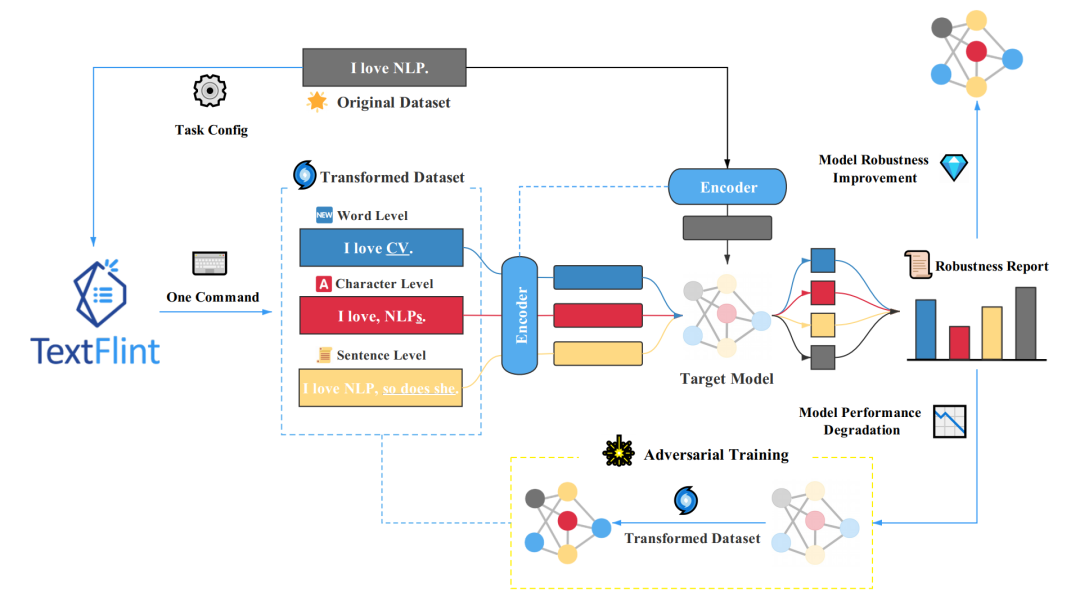
TextFlint 包含针对 12 项 NLP 任务,设计了 80 余种数据变形方法(20 余种任务通用变形、60 余种领域特有变形),涵盖了领域相关黑盒变形、领域无关黑盒变形、白盒变形、分组抽样、分析报告等等一系列功能。为了确保数据变形方法符合语言使用,针对不同任务上的所有变形选取约 10 万条变形后的语料进行了语言合理性(Plausibility)和语法正确性(Grammaticality)人工评测,确保了变形方法的可用性。使用者仅仅需要添加几行代码,就可以完成模型鲁棒性的详细检测。
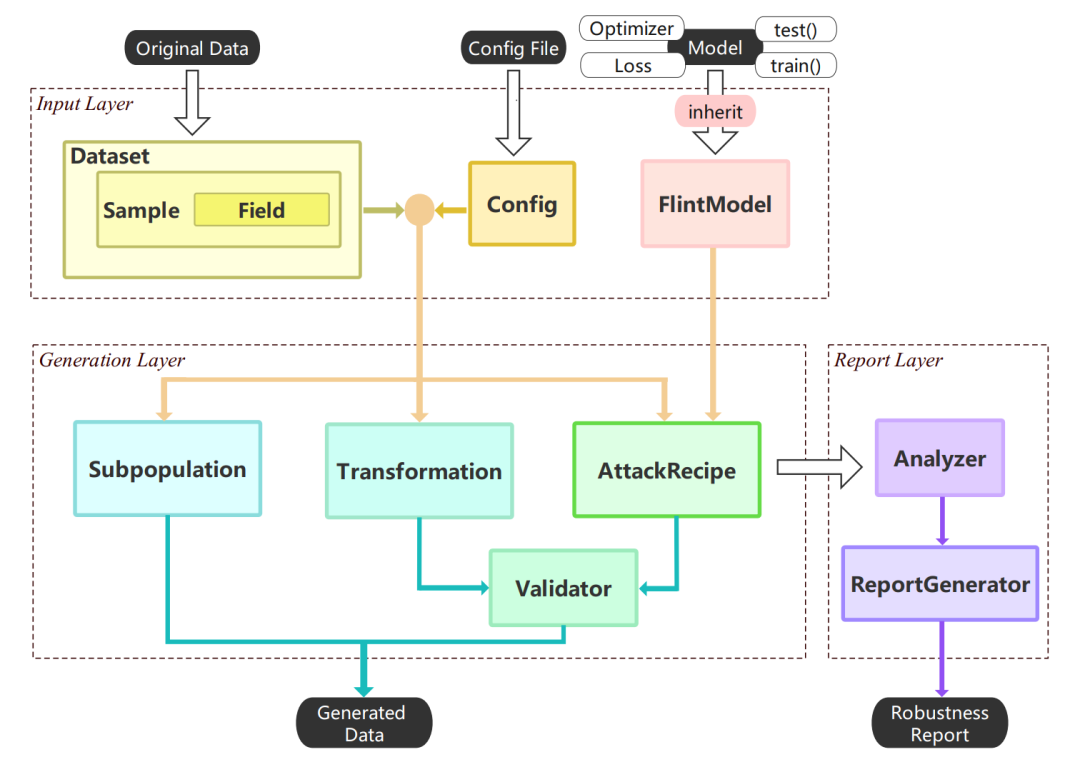
对于绝大多数的研究人员,使用 TextFlint 默认参数就可以一键化生成全方位的鲁棒性验证数据,几乎没有任何学习成本。对于有复杂定制需求的用户(例如对数据进行多个变形的组合操作),通过编写配置文件即可满足需求。此外,TextFlint 还提供便捷的鲁棒性可视化报告功能,多维度的鲁棒性分析报告,可以为开发者指引了模型进一步优化方向。用户可以根据报告结果,为模型生成扩展样本或对抗样本,从而直接提升 NLP 模型鲁棒性。
利用 TextFlint,复旦大学自然语言处理实验室还对包括分词、词性标注、句法分析、命名实体识别等在内的 12 项自然语言处理任务的约 100 个模型进行了复现和验证。部分任务还验证了 Microsoft、Amazon 以及 Google 的商业 API 接口结果,共计花费了 2 万多个 GPU 小时,完成了 6.7 万余次实验(全部评测结果可访问 TextFlint.io 获取)。
例如针对细粒度情感倾向分析 SemEval 2014 Restaurant 数据集,将 847 个带有明显情感词的测试用例进行文本变换,使用转换评论对象倾向性极性(RevTgt),转换非评论对象倾向性极性(RevNon)和原句后增加干扰句(AddDiff)三种不同的变形分别生成了 847、582 和 847 个测试实例。10 种不同模型在上述变形语料上的分析结果如下所示:
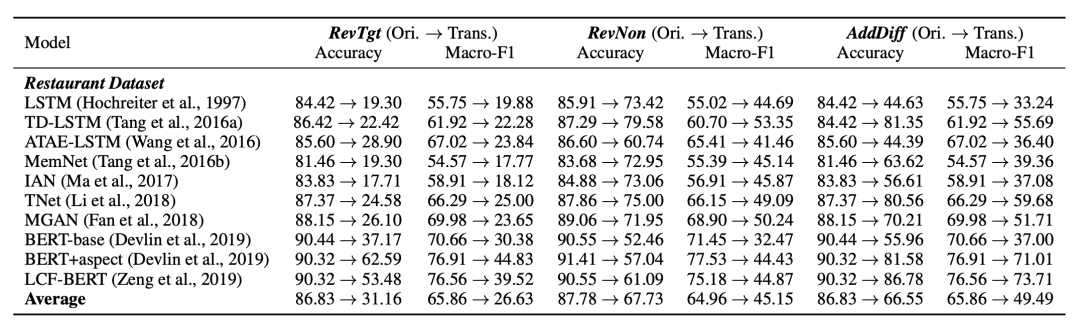
从结果中可以看到,原始测试集上所有模型的精度(Accuracy)和宏平均 F1(Macro-F1)得分都非常高,平均精度接近 86%,平均宏平均 F1 达到 65%。但是,这些指标在变形后的三个新测试集上均有显著下降。转换评论对象倾向性极性变形使得模型的性能下降最多,因为它要求模型更精准地关注目标情感词。原句后增加干扰句变形导致非 BERT 模型的性能下降显著,这表明大多数非预训练模型缺乏将相关方面与无关方面进行区分的能力。

总结
大规模的其他领域测评结果也同样显示,现有算法在大多数任务的测评数据集上的表现都较原始结果有所下降。即便是基于大规模预训练模型 BERT 的算法在一些任务的精度指标上也呈现了超过 50% 的降幅,这意味着这些算法在真实场景中几乎是不可用的。从以上大规模的评测结果可以看出,目前绝大多数算法模型的鲁棒性都亟待提升,这是一场无可回避的技术攻坚。
复旦大学自然语言处理实验室希望通过 TextFlint 这一面向自然语言处理的鲁棒性评测工具集合,为研究人员提供一个便捷的模型鲁棒性验证方法,从而推动自然语言处理算法更好地应用于真实场景。同时,也呼吁将模型鲁棒性纳入模型评估的必要维度,推动自然语言处理技术实现有效良性的发展。在未来,复旦大学自然语言处理实验室也将投入更多的人力和算力,进一步完善 TextFlint 工具的任务覆盖范围和模型验证数量,并开展面向 NLP 任务的高鲁棒可解释模型的原创研究。

点个在看 paper不断!