
【Web技术】972- 纯前端生成海报实践及其性能调优
1 需求背景
接到了一个紧急需求,需要根据 Excel 表格中学生的信息以及考试成绩生成相应的海报。
Excel 数据和需要生成的海报的样式如下:

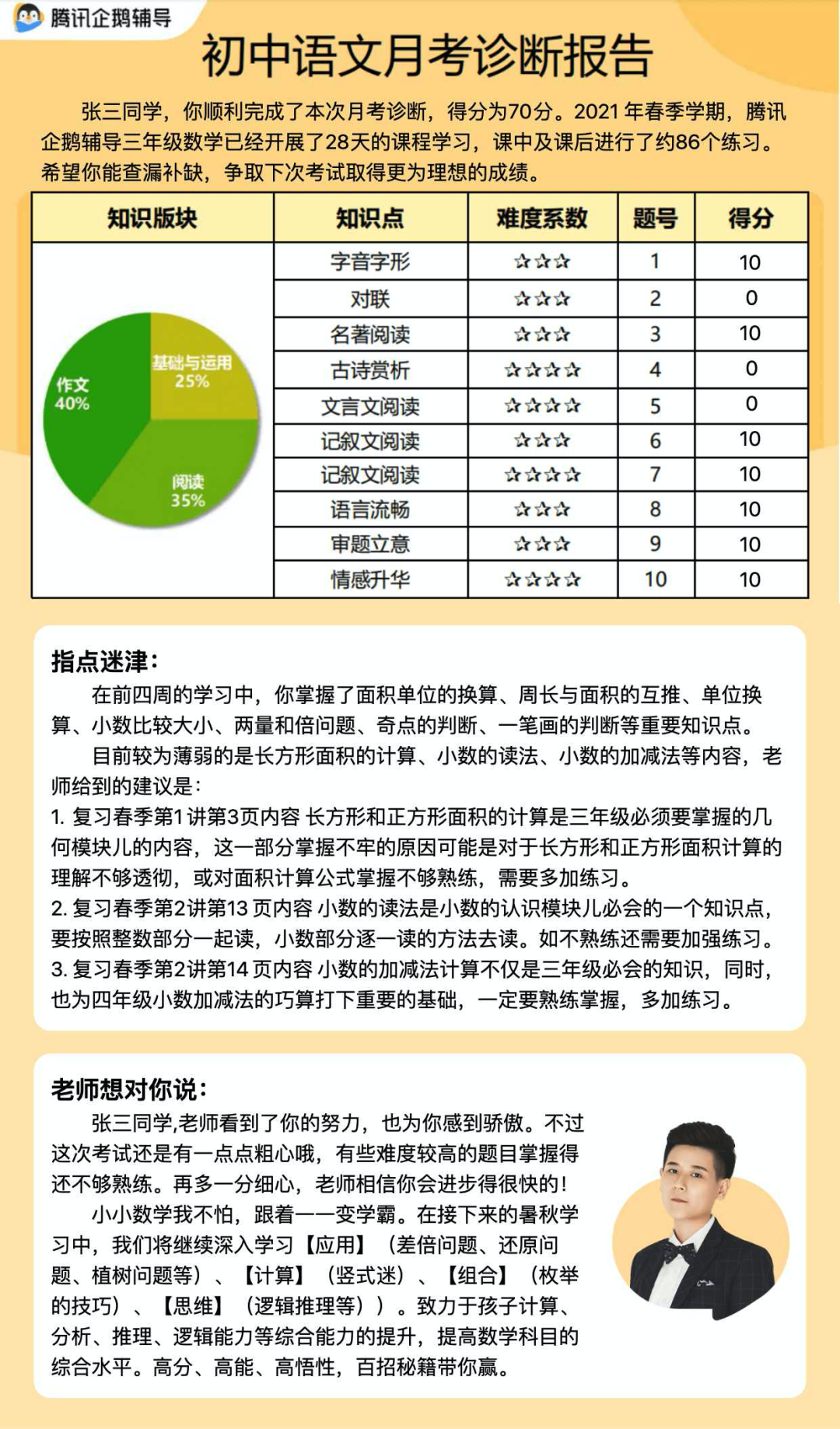
由于需求紧急,没有时间拉上后端同学,所以 Excel 表格的数据解析和海报生成功能都需要由前端开发。
以下几个技术点需要关注:
XLSX.utils.sheet_to_json 将 Excel 中的数据转化为 JSON 格式数据。canvas.toBlob 获得。FileReader.readAsTextapi 能够读取文本的内容,更多用法可以参考 MDN FileReader。在此基础上,确定此需求的总体开发思路:
1. 首先我们需要一个表单,获得海报可变文案的配置信息,例如不同题目考试成绩所对应的评语。
2. 遍历 Excel 中的每一条数据,根据每一条数据和表单的配置信息生成对应海报的 HTML 模板。
3. 根据 HTML 模板生成图片,并将图片数据保存进压缩包的对象中。
4. Excel 中的数据处理完后,下载压缩包,结束流程。
按照这个流程将功能开发完毕后,我在自己的机器上使用 100 条数据量的 Excel 表格进行测试,可以成功生成对应的压缩包,压缩包中的图片也没有问题,给运营同学演示后,她也表示很满意。
2 测试问题
但是当天晚上运营同学在自己的电脑测试这个工具时,悲剧发生了……
在运营同学的电脑上,使用 15 条 Excel 表格数据生成海报时表现正常,当增加到 20 条 Excel 表格数据时,出现了网页崩溃的情况,提示 Out Of Memory。
3 分析问题
3.1 js内存问题
现在让我们来一起分析一下,在哪里出现了问题?
分析发现,最有可能出现问题的地方是步骤 3——最终通过JSZip将图片打包进压缩包中。
压缩包对象所占用的内存在 Excel 表格数据处理完成并下载之前是不会被释放的,会一直增长。
所以我们有了一个简单的方案——分包。每处理 10 条数据就下载一次压缩包,将 JSZip (压缩包对象)所占用的内存释放。
但是事情真的有这么简单吗?20 张图片的数据以每张 1MB 的大小计算也才 20MB,怎么可能会导致网页崩溃呢?
凭空猜测没有作用,我们使用浏览器的 Performance 工具进行分析。
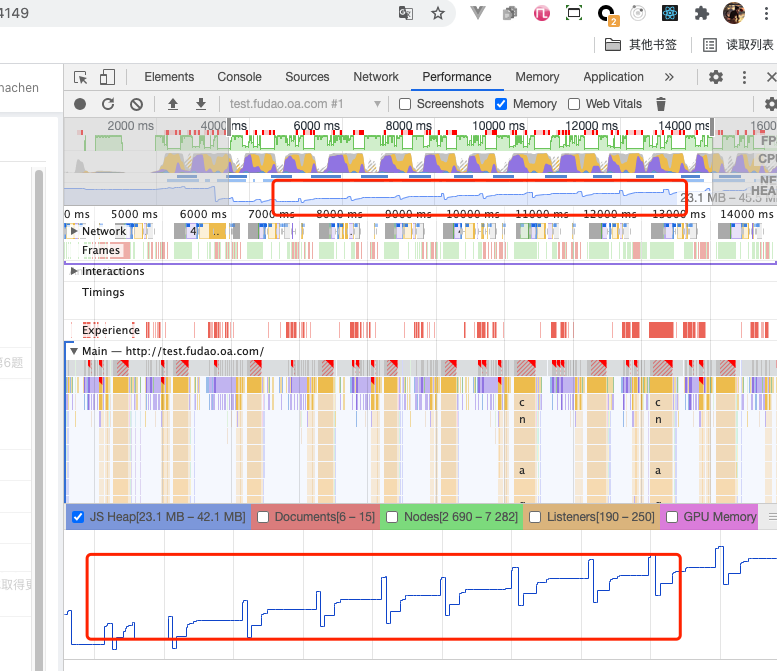
可以看到 JS Heap 在每处理一条 Excel 表格数据后都会增长,没有得到释放,这里没有得到释放的内存占用是上文分析的 JSZip 导致的吗?
继续使用浏览器的 Memory 工具进行分析。
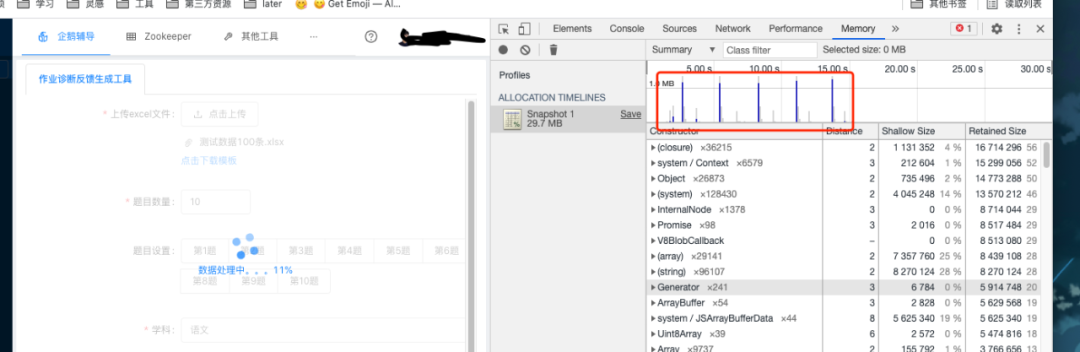
可以看到,内存占用确实是一直在涨,没有得到释放,放大其中的一项。

什么?竟然是 system.context ?作为一个前端开发,相信你看到这个词脑子里第一个冒出的念头应该就是上下文。检查代码,发现代码中使用了递归,所以造成了大量内存的使用,这里就不展示问题代码了。
将代码修改为循环语句后,再进行测试。

可以看到内存的增长已经正常。让运营同学再次进行测试。
3.2 DOM 问题
问题就这样被解决了吗?
信心满满的找到运营同学进行测试,结果出乎意料,运营同学的电脑依然处理不了 40 条以上的 Excel 表格数据,而且在测试中还出现了一个问题,数据处理到某个阶段时,会卡住很久!
为了解决问题,我们继续进行分析。
排查内存溢出的问题可以从两方面入手——JS 和 DOM。既然 JS 的问题我们已经解决,那就看看 DOM。
整体流程中,对 DOM 进行操作的地方有两点:
1. 根据 Excel 表格数据生成对应海报的 HTML 模板。
2. 根据 HTML 模板生成图片。
第一点应该不存在内存溢出问题,因为我们既没有在 HTML 模版上添加事件,在处理下一条数据时也是直接覆盖上一次生成的HTML 模板,不会导致 DOM 节点不停增加。
继续分析第二点,我使用了第三方库 html2canvas ,由对应的节点生成 canvas 对象,之后由 canvas 对象生成图片的二进制数据。
根据 html2canvas 文档的指引,设置 removeContainer 属性保留其生成 canvas 对象时所克隆的 DOM 元素并查看。

结果出乎意料,html2canvas 完整的克隆了我们的 DOM 结构,除目标节点外还克隆了 React 的根结点,script 标签,link 标签。
此时,数据处理慢以及在处理某条数据时卡慢的问题就清楚了,由于 html2canvas 完整的克隆了我们的 DOM 结构,不仅复制了很多没用的节点,而且由于克隆了 script 标签,link 标签,还会发起网络请求下载相关的资源。
我们需要把进行操作的节点插入在 body 标签下,根据文档指引,可以使用 html2canvas 提供的ignoreElements属性解决以上问题:
const canvas = await html2canvas(root, {
imageTimeout: 10000,
ignoreElements: (ele) => ele.id === 'root' || ele.tagName.toUpperCase() === 'IFRAME' || ele.tagName.toUpperCase() === 'SCRIPT' || ele.tagName.toUpperCase() === 'LINK',
});
通过以上代码,我们将无用的节点和会造成网络请求的标签进行了过滤。
优化过后,再让运营同学进行测试,这时处理一千条数据的 Excel 表格数据也不会再出现网页崩溃的问题了,同时处理速度也大大提升,1000 条数据在 4 分钟内可以处理完毕。
4 小结
回到最开始,JSZip 占用的问题依然存在,我们依然需要进行分包,不过分包的大小可以提升到1000条数据。
但是我们可以看到,如果不能找到问题的根本所在,一开始就进行分包也无济于事。
网页显示“喔唷,崩溃啦!”怎么办?请别着急,仔细分析才能解决问题。

回复“加群”与大佬们一起交流学习~
点击“阅读原文”查看 120+ 篇原创文章