
用上 RNN,这个视频抠像工具效果绝了

来源:HyperAI超神经 本文约1100字,建议阅读5分钟
本文为字节跳动团队发布的视频抠像工具 RVM 代码解析及论文《Robust High-Resolution Video Matting with Temporal Guidance》概要。


RVM 项目开放线上公开测试
项目 GitHub
https://github.com/PeterL1n/RobustVideoMatting
项目论文
https://arxiv.org/abs/2108.11515
墙内 Colab
https://openbayes.com/console/open-tutorials/containers/oqv42tbd8ko
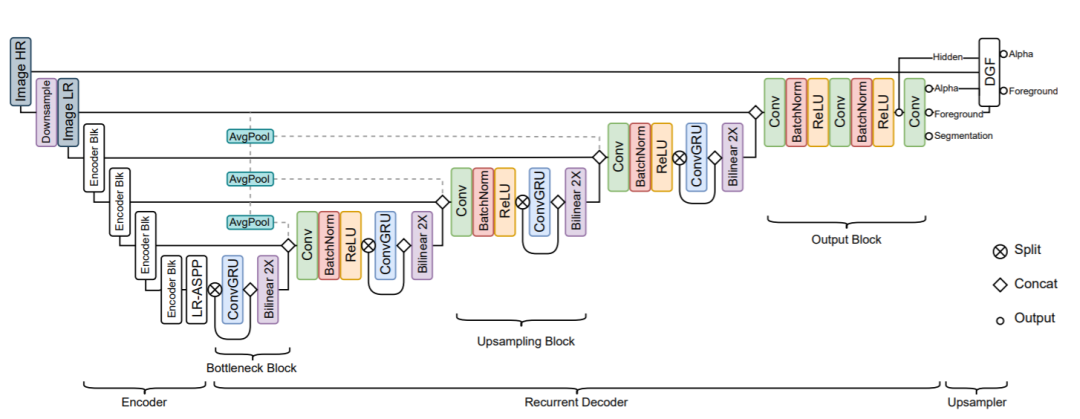
特征提取编码器:提取单帧特征;
循环解码器:综合时间信息;
深度引导滤波(DGF)模块:高分辨率采样。
import torchfrom model import MattingNetworkmodel = MattingNetwork(variant='mobilenetv3').eval().cuda() # 或 variant="resnet50"model.load_state_dict(torch.load('rvm_mobilenetv3.pth'))
from torch.utils.data import DataLoaderfrom torchvision.transforms import ToTensorfrom inference_utils import VideoReader, VideoWriterreader = VideoReader('input.mp4', transform=ToTensor())writer = VideoWriter('output.mp4', frame_rate=30)bgr = torch.tensor([.47, 1, .6]).view(3, 1, 1).cuda() # 绿背景rec = [None] * 4 # 初始记忆with torch.no_grad():for src in DataLoader(reader):fgr, pha, *rec = model(src.cuda(), *rec, downsample_ratio=0.25) # 将上一帧的记忆给下一帧writer.write(fgr * pha + bgr * (1 - pha))
from inference import convert_videoconvert_video(model, # 模型,可以加载到任何设备(cpu 或 cuda)input_source='input.mp4', # 视频文件,或图片序列文件夹input_resize=(1920, 1080), # [可选项] 缩放视频大小downsample_ratio=0.25, # [可选项] 下采样比,若 None,自动下采样至 512pxoutput_type='video', # 可选 "video"(视频)或 "png_sequence"(PNG 序列)output_composition='com.mp4', # 若导出视频,提供文件路径。若导出 PNG 序列,提供文件夹路径output_alpha="pha.mp4", # [可选项] 输出透明度预测output_foreground="fgr.mp4", # [可选项] 输出前景预测output_video_mbps=4, # 若导出视频,提供视频码率seq_chunk=12, # 设置多帧并行计算num_workers=1, # 只适用于图片序列输入,读取线程progress=True # 显示进度条
import tensorflow as tfmodel = tf.keras.models.load_model('rvm_mobilenetv3_tf')model = tf.function(model)rec = [ tf.constant(0.) ] * 4downsample_ratio = tf.constant(0.25)for src in YOUR_VIDEO:out = model([src, *rec, downsample_ratio])fgr, pha, *rec = out['fgr'], out['pha'], out['r1o'], out['r2o'], out['r3o'], out['r4o']
项目 GitHub
https://github.com/PeterL1n/RobustVideoMatting
项目论文
https://arxiv.org/abs/2108.11515
墙内 Colab
https://openbayes.com/console/open-tutorials/containers/oqv42tbd8ko
评论