
为什么不建议使用ON DUPLICATE KEY UPDATE?
往期热门文章:
1、3种常见的数据脱敏方案 2、这个队列的思路真的好,现在它是我简历上的亮点了。 3、痛快!SpringBoot终于禁掉了循环依赖! 4、BigDecimal使用不当,造成P0事故! 5、Spring Boot 启动时自动执行代码的几种方式,还有谁不会??
文章来源:https://c1n.cn/BeR1Q
目录
背景
官方资料
进行验证
总结
背景
<update id="updateByIds">
update tb_user
<trim prefix="set" suffixOverrides=",">
<trim prefix="name = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.name,jdbcType=VARCHAR}
</foreach>
</trim>
<trim prefix="weight = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.weight,jdbcType=DECIMAL}
</foreach>
</trim>
<trim prefix="high = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.high,jdbcType=DECIMAL}
</foreach>
</trim>
</trim>
where id in
<foreach collection="list" item="item" open="(" close=")" separator=",">
#{item.id,jdbcType=VARCHAR}
</foreach>
</update>
官方资料
https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
进行验证
CREATE TABLE `t1` (
`a` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键ID',
`b` int(11),
`c` int(11),
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='临时测试表'
| 验证主键插入并更新功能
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;





UPDATE t1 SET c=c+1 WHERE a=1
INSERT INTO t1 (b,c) VALUES (20,30)
ON DUPLICATE KEY UPDATE c=c+1;

| 验证多字段唯一索引问题
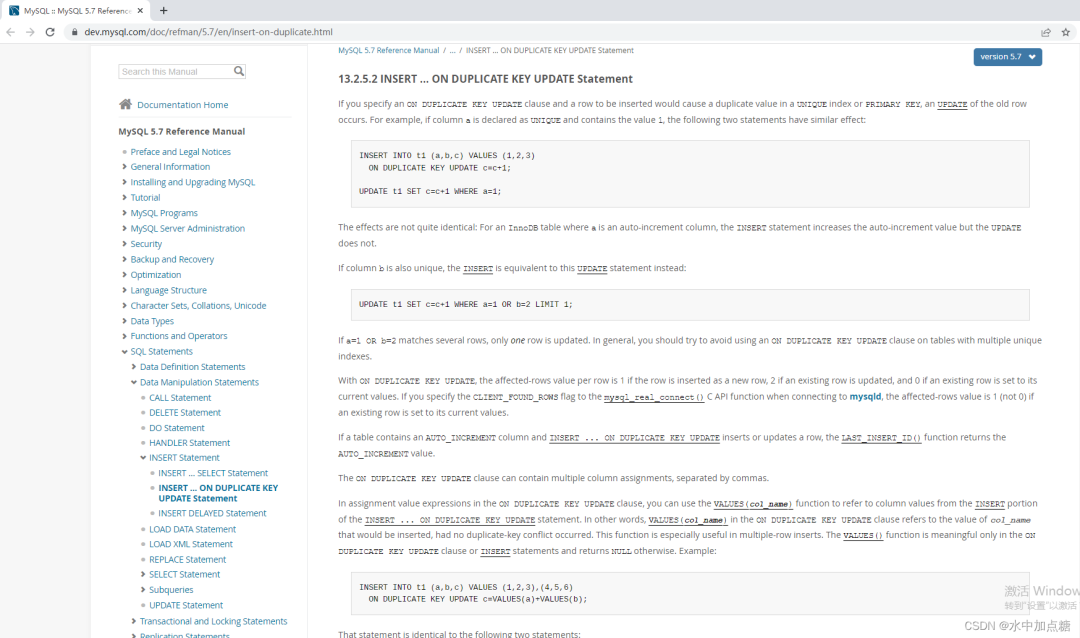
If column b is also unique, the INSERT is equivalent to this UPDATE statement instead:
UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
If a=1 OR b=2 matches several rows, only one row is updated. In general, you should try to avoid using an ON DUPLICATE KEY UPDATE clause on tables with multiple unique indexes.
ALTER TABLE t1 ADD UNIQUE INDEX uniq_b (b ASC);
INSERT INTO t1 (a,b,c) VALUES (3,20,30)
ON DUPLICATE KEY UPDATE c=c+1;

INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
UPDATE t1 SET c=c+1 WHERE a=1;
ALTER TABLE t1 DROP INDEX uniq_b ;
ALTER TABLE ntocc_test.t1
ADD UNIQUE INDEX uniq_b (b ASC);
;
The effects are not quite identical: For an InnoDB table where a is an auto-increment column, the INSERT statement increases the auto-increment value but the UPDATE does not.
UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
If a=1 OR b=2 matches several rows, only one row is updated. In general, you should try to avoid using an ON DUPLICATE KEY UPDATE clause on tables with multiple unique indexes.
| 涉及到的锁说明
An INSERT … ON DUPLICATE KEY UPDATE on a partitioned table using a storage engine such as MyISAM that employs table-level locks locks any partitions of the table in which a partitioning key column is updated. (This does not occur with tables using storage engines such as InnoDB that employ row-level locking.) For more information, see Section 22.6.4, “Partitioning and Locking”.
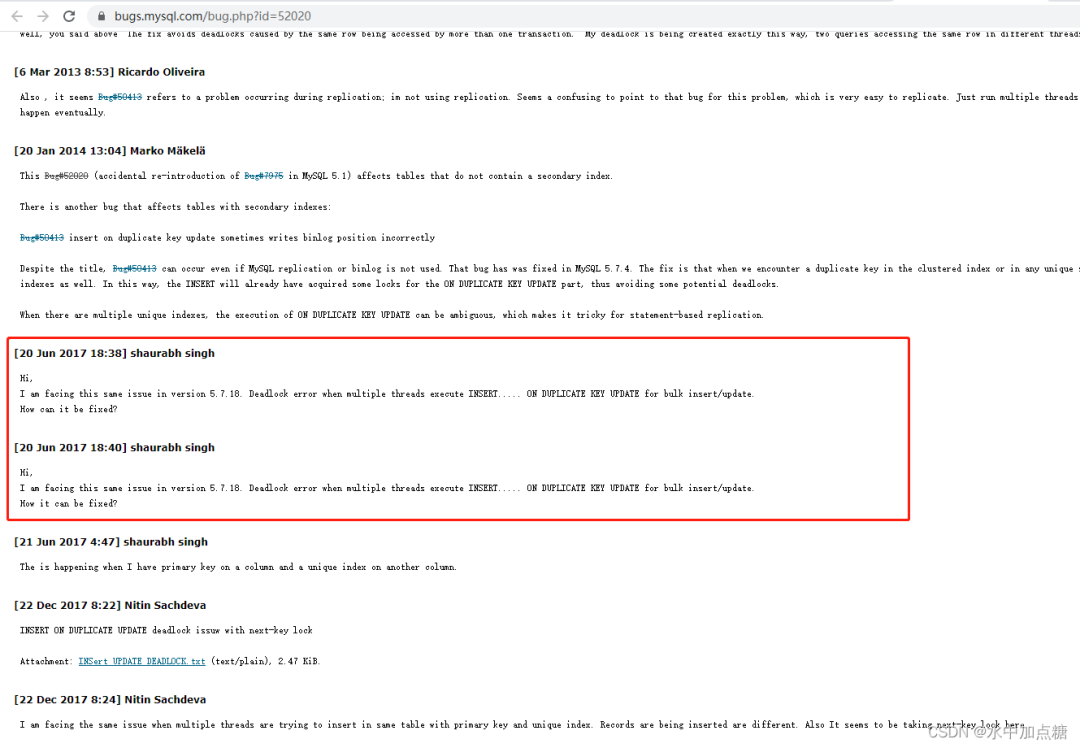
Hi,
I am facing this same issue in version 5.7.18. Deadlock error when multiple threads execute INSERT… ON DUPLICATE KEY UPDATE for bulk insert/update.
How it can be fixed?
I am facing the same issue when multiple threads are trying to insert in same table with primary key and unique index. Records are being inserted are different. Also It seems to be taking next-key lock here.
总结
on duplicate key update 在 MyISAM 存储引擎下使用的是表锁,性能不好。
on duplicate key update 在 InnoDB 下并发事务情况下可能会存在锁表/死锁问题。
应尽量避免在多唯一索引的情况下使用此语句。
往期热门文章:
1、MySQL 暴跌! 2、超越 Xshell!号称下一代 Terminal 终端神器,用完爱不释手! 3、IDEA 官宣全新默认 UI,太震撼了!! 4、让你直呼「卧槽」的 GitHub 项目! 5、Kafka又笨又重,为啥不选Redis? 6、50多个高频免费 API 接口分享 7、IDEA公司再发新神器!超越 VS Code 骚操作! 8、我怀疑这是 IDEA 的 BUG,但是我翻遍全网没找到证据! 9、Spring MVC 中的 Controller 是线程安全的吗? 10、Gitee 倒下了???