
为什么不建议使用ON DUPLICATE KEY UPDATE?

阅读本文大概需要 4.5 分钟。
来自:https://c1n.cn/BeR1Q
背景
<update id="updateByIds">
update tb_user
<trim prefix="set" suffixOverrides=",">
<trim prefix="name = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.name,jdbcType=VARCHAR}
</foreach>
</trim>
<trim prefix="weight = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.weight,jdbcType=DECIMAL}
</foreach>
</trim>
<trim prefix="high = case" suffix="end,">
<foreach collection="list" item="i" index="index">
when id= #{i.id,jdbcType=VARCHAR} then #{i.high,jdbcType=DECIMAL}
</foreach>
</trim>
</trim>
where id in
<foreach collection="list" item="item" open="(" close=")" separator=",">
#{item.id,jdbcType=VARCHAR}
</foreach>
</update>
官方资料
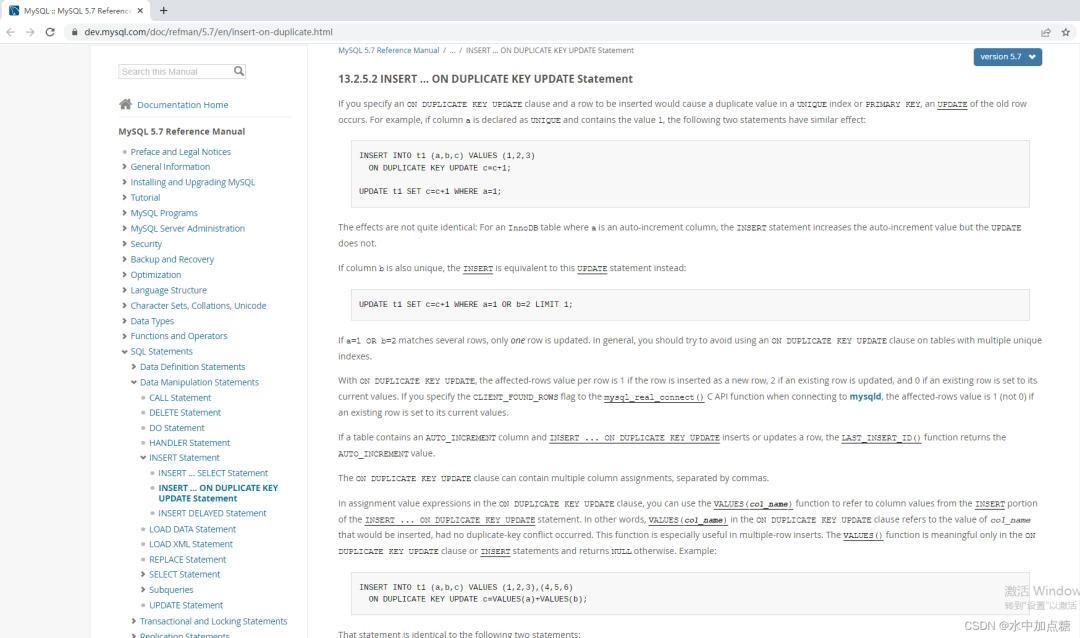
https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
进行验证
CREATE TABLE `t1` (
`a` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键ID',
`b` int(11),
`c` int(11),
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='临时测试表'
| 验证主键插入并更新功能
INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;





UPDATE t1 SET c=c+1 WHERE a=1
INSERT INTO t1 (b,c) VALUES (20,30)
ON DUPLICATE KEY UPDATE c=c+1;

| 验证多字段唯一索引问题
If column b is also unique, the INSERT is equivalent to this UPDATE statement instead:
UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
If a=1 OR b=2 matches several rows, only one row is updated. In general, you should try to avoid using an ON DUPLICATE KEY UPDATE clause on tables with multiple unique indexes.
ALTER TABLE t1 ADD UNIQUE INDEX uniq_b (b ASC);
INSERT INTO t1 (a,b,c) VALUES (3,20,30)
ON DUPLICATE KEY UPDATE c=c+1;

INSERT INTO t1 (a,b,c) VALUES (1,2,3)
ON DUPLICATE KEY UPDATE c=c+1;
UPDATE t1 SET c=c+1 WHERE a=1;
ALTER TABLE t1 DROP INDEX uniq_b ;
ALTER TABLE ntocc_test.t1
ADD UNIQUE INDEX uniq_b (b ASC);
;
The effects are not quite identical: For an InnoDB table where a is an auto-increment column, the INSERT statement increases the auto-increment value but the UPDATE does not.
UPDATE t1 SET c=c+1 WHERE a=1 OR b=2 LIMIT 1;
If a=1 OR b=2 matches several rows, only one row is updated. In general, you should try to avoid using an ON DUPLICATE KEY UPDATE clause on tables with multiple unique indexes.
| 涉及到的锁说明
An INSERT … ON DUPLICATE KEY UPDATE on a partitioned table using a storage engine such as MyISAM that employs table-level locks locks any partitions of the table in which a partitioning key column is updated. (This does not occur with tables using storage engines such as InnoDB that employ row-level locking.) For more information, see Section 22.6.4, “Partitioning and Locking”.
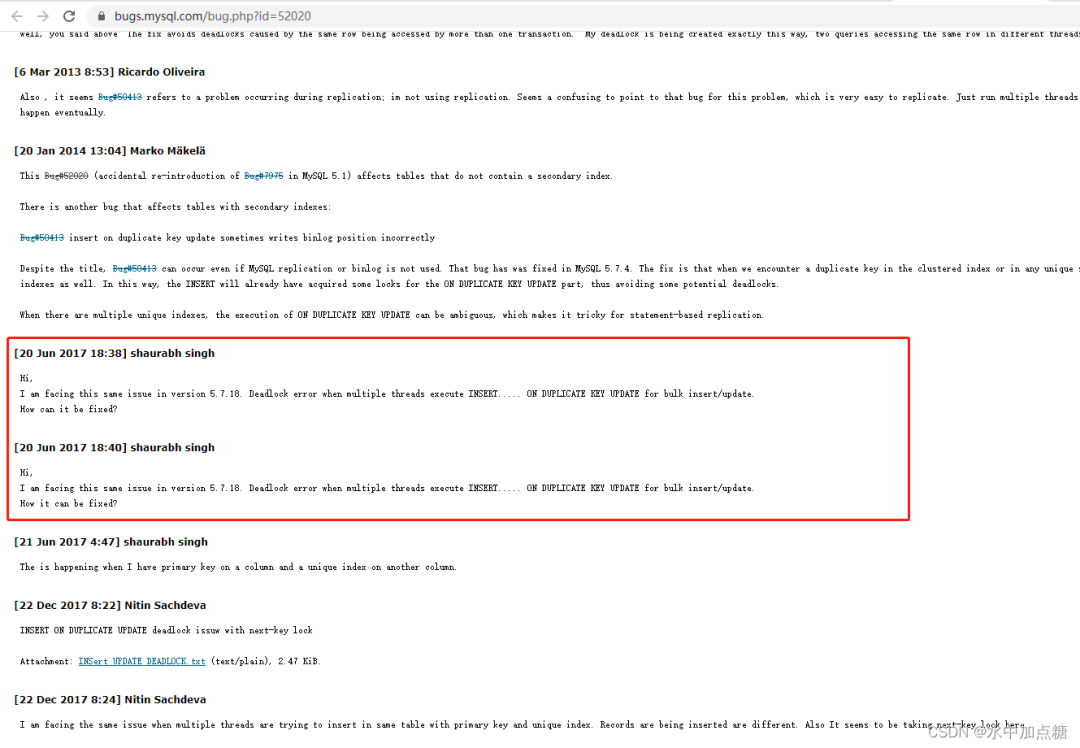
Hi,
I am facing this same issue in version 5.7.18. Deadlock error when multiple threads execute INSERT… ON DUPLICATE KEY UPDATE for bulk insert/update.
How it can be fixed?
I am facing the same issue when multiple threads are trying to insert in same table with primary key and unique index. Records are being inserted are different. Also It seems to be taking next-key lock here.
总结
on duplicate key update 在 MyISAM 存储引擎下使用的是表锁,性能不好。
on duplicate key update 在 InnoDB 下并发事务情况下可能会存在锁表/死锁问题。
应尽量避免在多唯一索引的情况下使用此语句。
推荐阅读:
Mybatis查询结果为空时,为什么返回值为NULL或空集合?
互联网初中高级大厂面试题(9个G) 内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取! 朕已阅
