from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import requests
import time
import numpy
import cv2
import os
#作者:许文鸿
#未经允许不可转载,转载时注明出处
#创建 WebDriver 对象,指明使用chrome浏览器驱动
web = webdriver.Chrome(r'd:\chromedriver.exe')
web.implicitly_wait(5)
#调用WebDriver 对象的get方法 可以让浏览器打开指定网址
web.get('https://pintia.cn/auth/login')
zh = web.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[2]/form/div[1]/div[1]/div/div/div[1]/input')
mm = web.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[2]/form/div[1]/div[2]/div/div/div[1]/input')
#在PTA的账号密码:
zh.send_keys('******@qq.com')
mm.send_keys('******')
#找到登录按钮并点击
web.find_element_by_xpath('/html/body/div[1]/div[3]/div/div[2]/form/div[2]/button/div/div').click()
#等待两秒,验证码加载完成
time.sleep(2)
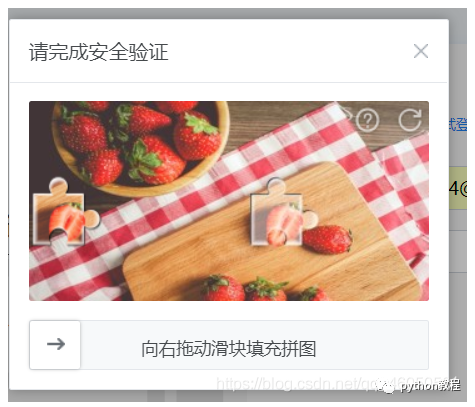
#bg背景图片
bg_img_src = web.find_element_by_xpath(
'/html/body/div[3]/div[2]/div/div/div[2]/div/div[1]/div/div[1]/img[1]').get_attribute('src')
#front可拖动图片
front_img_src = web.find_element_by_xpath(
'/html/body/div[3]/div[2]/div/div/div[2]/div/div[1]/div/div[1]/img[2]').get_attribute('src')
#保存图片
with open("bg.jpg", mode="wb") as f:
f.write(requests.get(bg_img_src).content)
with open("front.jpg", mode="wb") as f:
f.write(requests.get(front_img_src).content)
#将图片加载至内存
bg = cv2.imread("bg.jpg")
front = cv2.imread("front.jpg")
js = 'alert("本人可能将此程序用于python课设,请靓仔靓女不要直接提交本人代码。即将报错,需要删除第42~44行代码即可正常运行");'
web.execute_script(js)
time.sleep(15)
#将背景图片转化为灰度图片,将三原色降维
bg = cv2.cvtColor(bg, cv2.COLOR_BGR2GRAY)
#将可滑动图片转化为灰度图片,将三原色降维
front = cv2.cvtColor(front, cv2.COLOR_BGR2GRAY)
front = front[front.any(1)]
#用cv算法匹配精度最高的xy值
result = cv2.matchTemplate(bg, front, cv2.TM_CCOEFF_NORMED)
#numpy解析xy,注意xy与实际为相反,x=y,y=x
x, y = numpy.unravel_index(numpy.argmax(result), result.shape)
#找到可拖动区域
div = web.find_element_by_xpath('/html/body/div[3]/div[2]/div/div/div[2]/div/div[2]/div[2]')
#拖动滑块,以实际相反的y值代替x
ActionChains(web).drag_and_drop_by_offset(div, xoffset=y // 0.946, yoffset=0).perform()
#至此成功破解验证码,由于算法问题,准确率不能达到100%,可能需要多运行1~2次
for page in range(0, 1000):
time.sleep(1)
#此处的网址为PTA固定网页,仅需要更换page
web.get('https://pintia.cn/problem-sets?tab=1&filter=all&page={page_}'.format(page_=page))
#获取当前页面题目集网址,A_s为a标签的列表,urls用户存放网址
A_s = web.find_elements_by_class_name('name_QIjv7')
urls = []
for a in A_s:
urls.append(a.get_attribute('href'))
#当页面不存在可爬取的网址,则退出程序
if urls.__len__() == 0:
print('爬取完成')
os._exit()
#对刚才获取的网址列表进行遍历
for url in urls:
web.get(url)
#找到对应的题目对象
tm = web.find_elements_by_css_selector("[class='problemStatusRect_3kpmC PROBLEM_ACCEPTED_1Dzzi']")
tm_total = 0
for i in range(0, 1000):
# 遍历该页面的题型
try:
tm_type = web.find_element_by_xpath(
'/html/body/div/div[3]/div[2]/div/div[2]/div[{i_}]/div/div[2]'.format(i_=i * 2 + 2)).text
# 如果题型为编程/函数,记录对应的数量,方便后续爬取
if tm_type == '编程题' or tm_type == '函数题':
tm_total += int(web.find_element_by_xpath(
'/html/body/div/div[3]/div[2]/div/div[2]/div[{i_}]/a/div/div'.format(i_=i * 2 + 2)).text[0])
except:
break
# 根据函数/编程题数量取相应的题目对象,舍弃其他题目
if tm_total != 0:
tm = tm[-tm_total:]
else:
tm = []
# 遍历剩余题目
for tm_index in tm:
try:
tm_index.click()
time.sleep(0.5)
#获取题目中的代码
tm_title = web.find_element_by_css_selector(
"[class='text-center black-3 text-4 font-weight-bold my-3']").text
mycode = web.find_element_by_css_selector('textarea').get_attribute('value')
print('题目:' + tm_title)
print(mycode)
#接下来可以存入
except:
continue