
记一次 .NET 程序的性能优化实战(2)—— 使用 perfview 找出 Regex 慢的根本原因
前言
我在上一篇文章《记一次 .NET 程序的性能优化实战(1)—— 使用 process explorer 快速定位问题代码》中用 process explorer 定位到了导致程序运行缓慢的原因——使用了 .NET 中的正则表达式。.NET 中的正则表达式真这么慢吗?带着疑问,开始了本次的探索之旅。喜欢刨根问底的小伙伴儿快来一起看看吧!
在开始之前,我还是把关键函数贴一下,大家也可以看看到底哪里写的有问题。代码如下:
private static bool IsSplitter(string curLine)
{
var splitterRegex = new Regex(@"-{100,}", RegexOptions.Compiled | RegexOptions.IgnoreCase);
MatchCollection matches = splitterRegex.Matches(curLine);
return (matches.Count > 0);
}
选择优化工具
不知道都使用过哪些性能优化工具呢?我主要专注于 windows 下的 c/c++/c# 开发,不涉及其它语言,也不涉及其它平台。这里列举几个我用过的性能优化工具。
intel vtune
intel出品的性能优化工具。优点:功能强大,跨平台,支持多种编程语言。缺点:占用空间太大,对硬件要求高,有一定的使用门槛,不免费。visual studio高版本的
vs自带性能分析工具(应该从vs2013就有了?),但是我很少用vs来分析性能问题。process monitor 嗯,你没看错,
process monitor不仅可以用来排错,也可以用来做性能分析,只不过不适合源码级别的性能分析。我也很少用它来分析性能问题,主要用来排错。.NET相关的性能优化工具。JetBrains dotTrace
JetBrains dotMemory
对这两个工具不熟悉?没关系,相信做
.NET开发的小伙伴儿一定听过或者用过大名鼎鼎的 ReShaper。这几个工具是同一个公司出品的。BTW,这个公司还开发了一个非常好用的反编译工具 dotPeek。.NET Memory Profiler
基于
ETW(Event Trace for Windows) 的各种工具,适用于原生和托管程序。perfmonwindows系统自带的基于ETW的性能分析工具,真正的免安装。WPR/WPRUI/xperf微软性能分析工具集(Windows Performance Toolkit)提供的
ETW捕获工具,可以使用WPA等性能分析工具进行查看。WPA(Windows Performance Analyzer)微软性能分析工具集提供性能分析工具,与
WPR等抓取工具同时使用。图形界面极其强大,但是学习曲线比较陡峭,不容易上手。UIforETW
google大佬Bruce Dawson基于WPT开发的ETW捕获工具。开源免费。对WPT做了一层封装,额外提供了的按键记录功能。他的博客 Random ASCII 有大量高质量的关于性能优化的文章,强烈推荐阅读。
PerfView
微软开发的基于
ETW的性能分析工具,集抓取和分析于一身的工具。开源免费,绿色免安装,体积小,分析功能强大,虽然图形界面相对薄弱,但是分组过滤功能非常强大。与WPA一样不太容易上手,但是可以非常方便的获取提示信息,而且有配套的视频教程。尤其适合分析.NET程序的性能问题。说明:基于
ETW机制的工具有一个弊端,一般情况下,ETW是针对整个系统进行收集的,不太适合长时间采集,在采集之前一定要想好要收集哪些信息。
我电脑中必备的工具有 PerfView, WPT, UIforETW, vs, sysinternals。因为本次优化的是 .NET 程序,所以首选 PerfView。
采集性能数据
运行 PerfView.exe,点击 Collect 菜单,然后点击 Collect 菜单项(会有提升权限的提示),在弹出的采集界面中保持默认设置,点击 Start Collection 按钮即可开始采集。采集开始后,执行 ParseTfsLog.exe -b bug.csv,ParseTfsLog.exe 。程序执行完毕后,在 PerfView 中点击 Stop Collection 即可停止采集。
耐心等待一会,就可以在 PerfView 主界面的左侧看到刚刚采集到的日志文件了。
初步分析
双击日志文件(PerfViewData.etl.zip),可以看到几个视图,如下图所示:
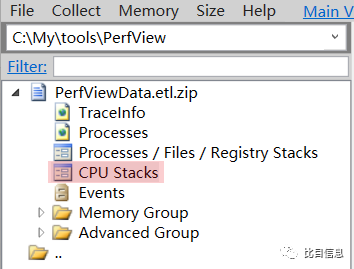
因为 ParseTfsLog 这个简单的小程序只使用了单线程,在执行过程中基本占满了一个 CPU(运行在 8 核心的机器上,CPU 占用率大概是 12.5%)。

根据以上信息,猜测这是一个 CPU 占用率过高的问题,优先关注 CPU 使用率问题,双击 CPU Stacks 视图进行查看。
说明:
PerfView中的CPU Stacks视图相当于WPA中的CPU Usage (Sample)视图。记录的是CPU采样数据,默认是1毫秒采样一次(采样频率最快可以调整到1/8毫秒)。也就是一条数据基本上等于1毫秒。
在弹出的 Select Process Window 窗口中,列出了系统中所有的进程,可以看到 ParseTfsLog 排在第 1 位。
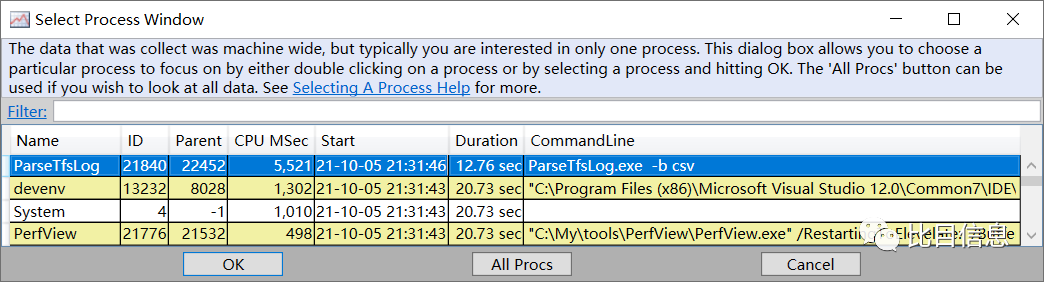
双击 ParseTfsLog 所在的行,即可查看 ParseTfsLog 进程的事件,如下图:
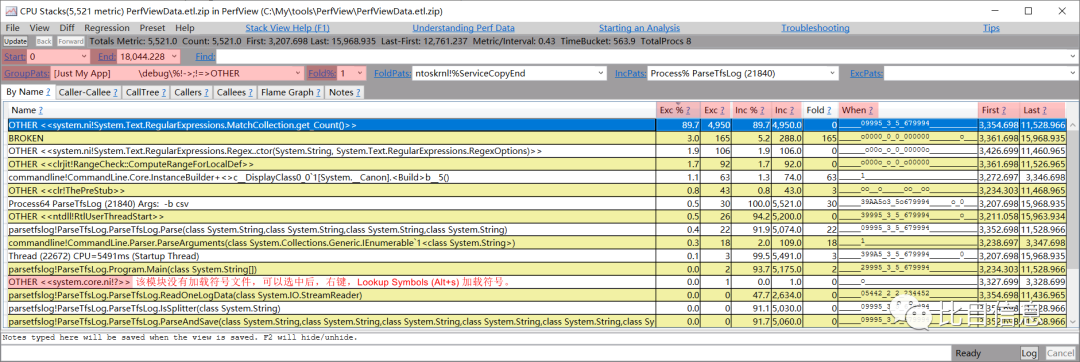
在开始分析前,先简单介绍一下上图中涉及到的几个关键点,对理解采集到的数据非常有帮助。
Start和End表示采集的起始时间和终止时间。如果只关心某一时间段内的数据,可以调整起始时间和终止时间。这两个值可以单独修改其中的一个,也可以通过Set Time Range (Alt+R)修改。GroupPats表示列表中显示的记录是按什么规则分组的,默认选择的是[Just My App] \debug\%!->;!=>OTHER。意思是.exe所在路径以外的任何模块的任何代码都会被当成OTHER。比如,第一条记录被归类到OTHER里了,因为这条记录对应的地址是在system.ni模块中的,该模块并不在ParseTfsLog.exe所在的目录下。图中第5条记录属于CommandLine.dll模块(与.exe在同一个目录下),图中最后3条记录属于ParseTfsLog.exe模块。Fold%表示折叠出现频率低于指定值的记录。设置一个合理的Fold%值,可以很好的过滤一些无关紧要的记录。Exc %和Exc表示当前函数的采样百分比和采样数,不包含子函数的采样数据。Inc %和Inc与Exc正好相反,表示包含当前函数及其子函数的采样数据。When表示事件发生的时刻,PerfView会把整个时间段分成32份,然后把采样数据按照时间点划分到32份中的一份中。_表示没有采样数据。First和Last分别表示第一条和最后一条采样数据的时间点。
说明: 每一项都可以通过点击右侧的问号查看对应的帮助文档。下图是官方帮助文档中的解释。
perfview-official-help-document

简单介绍后,就可以查看数据了。可以看到 MatchCollection.get_Count 占用了绝大部分 CPU(大概 89.7%)。看来正则表达式确实占用了很多时间。时间到底花在哪里了呢?点击 MatchCollection.get_Count 对应的单元格,右键,选择 Drill Into (Ctrl+D) 即可查看MatchCollection.get_Count() 函数内部的详细信息了。如下图: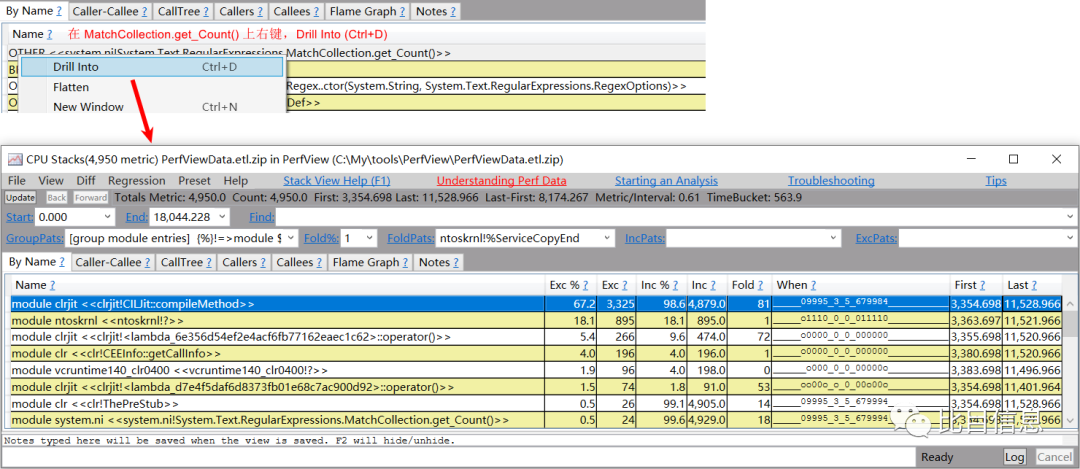
从上图可知,clrjit!CILJit::compileMethod 居然占了大部分 CPU(Exc % 是 67.2,Inc % 是 98.6%)。
除了可以像上面那样查看 MatchCollection.get_Count 的相关信息,还可以通过调用栈来自顶向下的查看相关信息。
查看调用栈
在查看前可以先取消分组(把 GroupPats 设置为 [no grouping] 即可取消分组,非必须,取消分组后可以看到更符合直觉的调用栈),然后选择 CallTree 。逐层点击调用栈进行查看,如下图:
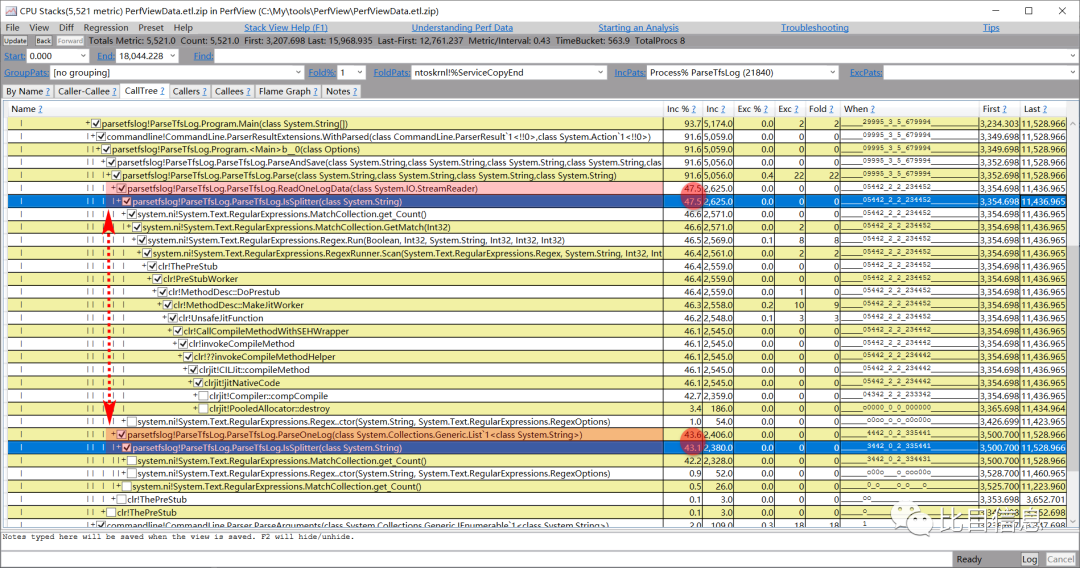
从上图可知,采集到的数据跟实际代码逻辑是完全吻合的。在 Parse() 函数中会不断的调用 ReadOneLogData() 读取提交记录后,调用 ParseTfsLog.ParseOneLog() 对读取到的记录进行解析。ReadOneLogData() 和 ParseTfsLog.ParseOneLog() 内部都会调用 IsSplitter() 判断某一行是否是分隔符。
看来是 IsSplitter() 函数中的 JIT 相关代码占用了大部分 CPU。
据我所知,一般一个托管函数只需要执行一次 JIT,下次调用的时候会执行编译好的原生代码。为什么会有这么多时间花在 JIT 上呢?在 JIT 哪些函数呢?
查看 JIT
在 PerfView 主界面,双击左侧的 Events 视图(在 CPU Stacks 下方),打开所有 ETW 事件记录。可以根据各种条件进行过滤,也可以指定需要显示的列。
在 Process Filter对应的下拉框中输入ParseTfsLog(可以自动补全),表示只关心进程名字中含有ParseTfsLog的事件。在 Filter处输入jit即可过滤Event Types中含有jit的Event,这里只剩下了Microsoft-Windows-DotNETRuntime/Method/JittingStarted,双击即可显示该种event对应的所有记录。可以在 Text Filter处输入过滤关键字,只保留符合条件的记录。!表示反向过滤,比如!CommandLine表示不显示包含CommandLine的记录。点击 Columns To Display右侧的Cols按钮设置需要显示的列,按住ctrl或者shift选择多列,选好后按回车即可。我选择了三列:MethodNamespace,MethodName和*。列宽,列位置等均可手动调整,单击列头可以根据对应的列进行排序。
过滤后的事件如下图所示:
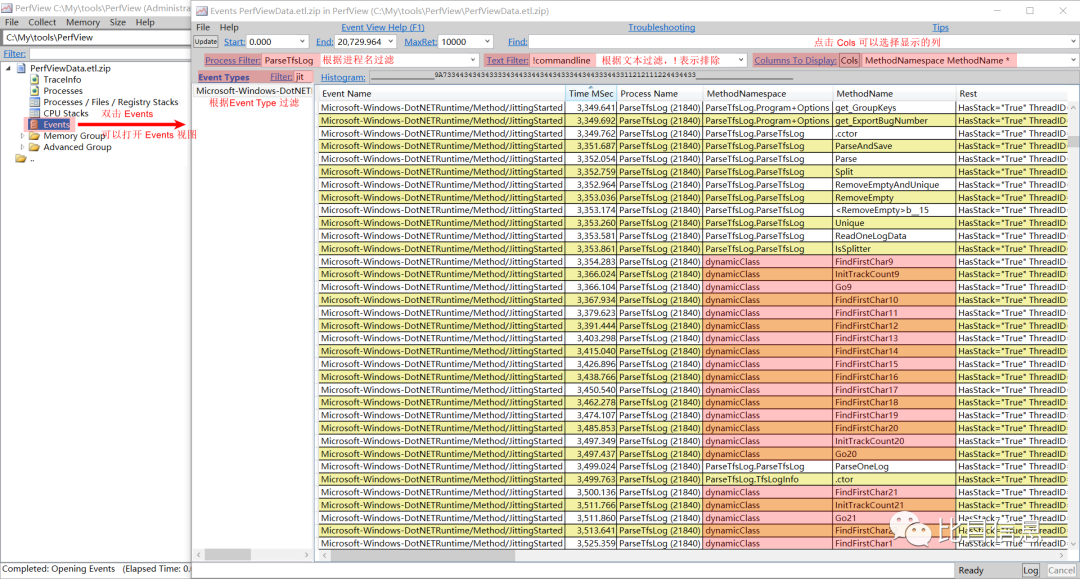
浏览过后发现,很多函数(包括 IsSplitter)都只被 JIT 了一次,符合认知。但是,有一种 JIT 比较特殊 —— MethodNamespace 为 dynamicClass 的 JIT 记录。这种记录对应的 MethodName 也比较有规律 —— 名称+数字。比如,FindFirstChar9,Go9,Go20,Go21 等等。随便选择其中一条记录,在其 Time MSec 列上右键,选择 Open Any Stacks (Alt+s) 即可查看相关的调用栈。这里只列出 FindFirstChar9 对应的调用栈。如下图:
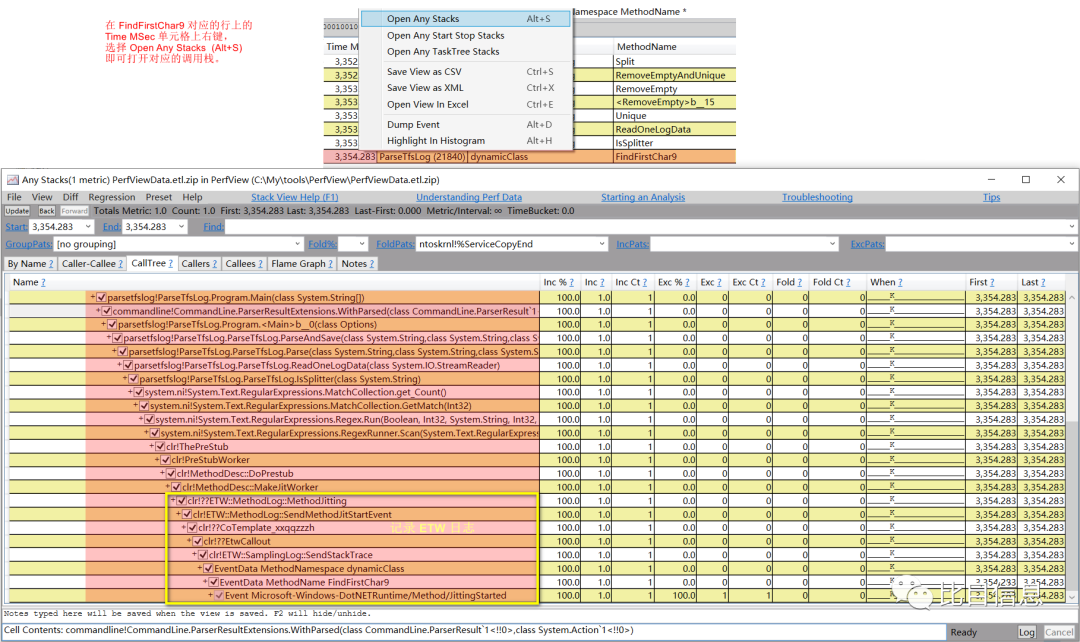
浏览了几个函数后,感觉这些函数名好像是根据某些规则自动生成的。猜测是每次循环都会生成一次动态代码。该如何确认这个猜想呢?
添加自定义 ETW 日志
在 IsSplitter() 函数内部增加一个自动输出 ETW 日志的功能,通过添加的 using 语句可以在进入函数和退出函数的时候分别输出 ETW 日志(输出日志的逻辑可以参考 AutoScopeLogger 类,这里从略)。修改后的 IsSplitter() 如下:
private static bool IsSplitter(string curLine)
{
using (var autoLogger = new AutoScopeLogger("[IsSplitter]"))
{
var splitterRegex = new Regex(@"-{100,}", RegexOptions.Compiled | RegexOptions.IgnoreCase);
MatchCollection matches = splitterRegex.Matches(curLine);
return (matches.Count > 0);
}
}
编译通过后,重新使用 PerfView 采集 ETW 日志。这次需要设置 Additional Provider 为 *EtwLogger:*:*:@StacksEnabled=true 才能采集到新加的日志(@StacksEnabled=true 非必须,但是加上就可以看到调用栈)。这次 PerfView 的相关设置如下图:
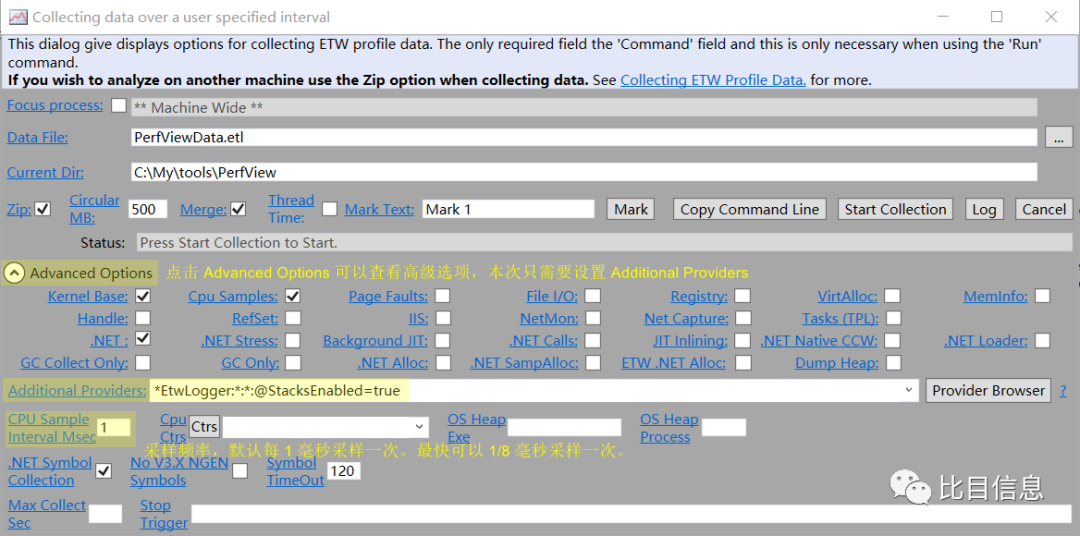
采集好日志后再次查看 Events。这次 Event Types 的 Filters 需要改成 jit|Etwlogger,表示只关心 Event Types 中包含 jit 或者 EtwLogger 的 Event 。过滤后的记录下图所示:
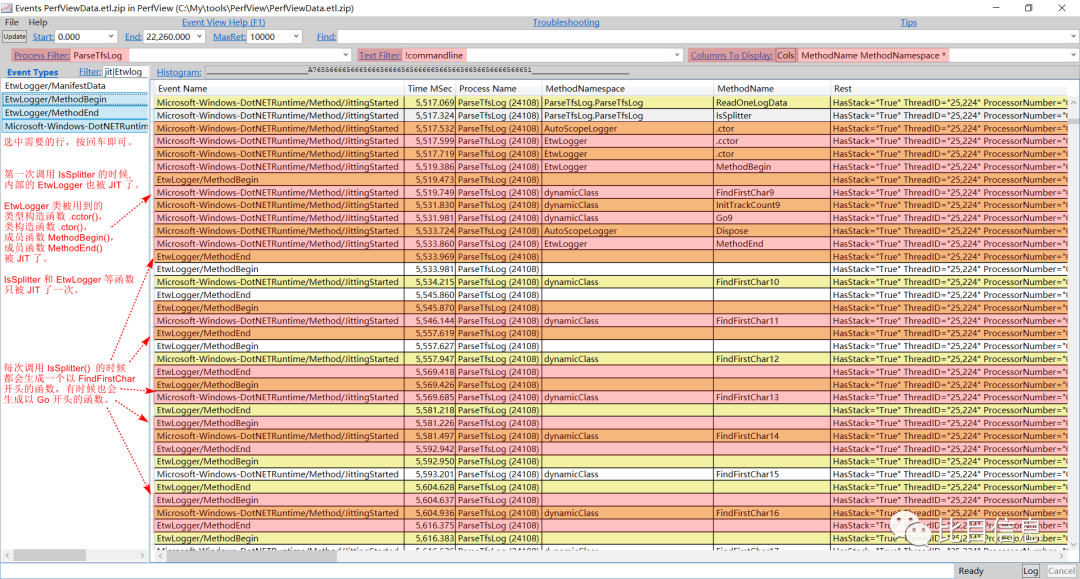
可以发现,基本每个 IsSplitter() 调用都会产生一个以 FindFirstChar 开始的动态函数,有时候也会产生以 Go 开头的动态函数。
至此,基本上已经知道程序运行慢的原因了 —— 每次调用 IsSplitter() 都会执行 JIT。但是为什么呢?这就到了我的知识盲区了。只能搜搜看了,在 google 中输入 .net regex slow,出来一堆结果,从里面发现了一个非常有帮助的官方文档 —— Best practices for regular expressions in .NET。
官方文档
Best practices 翻译成中文就是最佳实践,看名字就知道是好资料(不夸大,务实)。文档里提到的一个比较重要的概念:
Defining a regular expression involves tightly coupling the regular expression engine with a regular expression pattern.
大白话翻译就是:使用正则表达式前需要与正则表达式引擎绑定,绑定后就可以用来匹配文本了。
文档里介绍了四种方法并分析了每种方法的适用场景,我按照理解整理如下:
| 名称 | 使用方法 | 优缺点 |
|---|---|---|
静态正则表达式 (Static regular expressions) | 调用静态函数,比如 Regex.IsMatch(string input, string pattern)。 | 使用简单,生成的 operation code 和 MSIL 都可以缓存到引擎内部。可以代替重复实例化具有相同表达式的正则表达式对象。 |
解释型的正则表达式 (Interpreted regular expressions) | 实例化一个 Regex 对象,并且在实例化的时候不传递 Compiled 标志。 | 启动相对快,执行相对慢。适用于重复调用次数比较少的情况。调用次数越多,执行慢的缺点越明显。 |
编译型的正则表达式 (Compiled regular expressions) | 实例化一个 Regex 对象,并且在实例化的时候传递 Compiled 标志。 | 启动相对慢,执行相对快。适用于调用次数比较多的情况。调用次数越多,执行快的优点越明显。 |
编译正则表达式到独立的程序集 (Regular expressions: Compiled to an assembly) | 通过 Regex.CompileToAssembly 把正则表达式编译到独立的程序集中。 | 实现复杂,需要引入额外的程序集。 |
文档中关于 Compiled regular expressions 的说明摘录如下:
Regular expression patterns that are bound to the regular expression engine through the specification of the Compiled option are compiled. This means that, when a regular expression object is instantiated, or when a static regular expression method is called and the regular expression cannot be found in the cache, the regular expression engine converts the regular expression to an intermediary set of operation codes, which it then converts to MSIL. When a method is called, the JIT compiler executes the MSIL.
当一个编译型的正则表达式对象被实例化时,其对应的正则表达式在缓存中不存在的话,正则表达式引擎会把对应的正则表达式转换成中间操作码,然后被转换成 MSIL。当对象的方法被调用时,JIT 会把对应的 MSIL 翻译成机器指令。
这很好的解释了前面通过 PerfView 采集到的大量 JIT 事件。
修改
知道问题出在哪,改起来就简单了。IsSplitter() 中使用的正则表达式(固定不变,会被重复调用)完美符合使用静态正则表达式的条件,所以可以把原来的逻辑使用 Regex.IsMatch() 重写,重写后的代码如下:
private static bool IsSplitter(string curLine)
{
using (var autoLogger = new AutoScopeLogger("[IsSplitter]"))
{
return Regex.IsMatch(curLine, @"-{100,}");
}
}
另外一种改法是把函数内部实例化的 Regex 对象改成全局变量,只实例化一次。在 IsSplitter() 中直接使用,修改后的代码如下:
private static bool IsSplitter(string curLine)
{
using (var autoLogger = new AutoScopeLogger("[IsSplitter]"))
{
// 修改 splitterRegex 为全局变量
//var splitterRegex = new Regex(@"-{100,}", RegexOptions.Compiled | RegexOptions.IgnoreCase);
MatchCollection matches = splitterRegex.Matches(curLine);
return (matches.Count > 0);
}
}
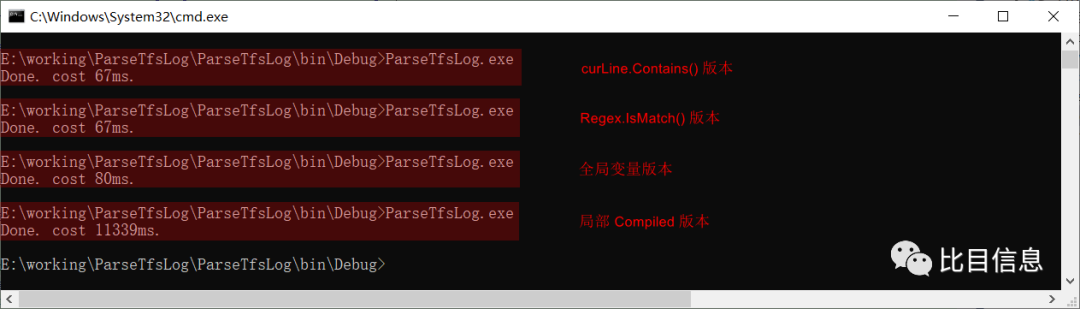
经测试,不使用正则表达式(curLine.Contains())需要 67ms,使用静态正则表达式的版本需要 67ms,使用全局变量的版本需要 80ms。与未修改的版本(需要 11339ms)相比都有了极大的提高。而且静态正则表达式版本的耗时与字符串查找耗时基本一致。可见,如果正确使用正则表达式,效率还是非常高的。
总结
PerfView绝对是windows平台下的性能分析神器,开源免费,绿色免安装,体积小巧,功能强大,既能采集又能分析。尤其适合分析.NET程序。静态正则表达式可以很好的使用正则表达式引擎的缓存,有效提升正则表达式的效率。 不要在循环中定义固定模式的编译型正则表达式对象,使用静态正则表达式替换。
参考资料
PerfiView帮助文档Best practices for regular expressions in .NEThttps://docs.microsoft.com/en-us/dotnet/standard/base-types/best-practices
彩蛋
本来以为已经调查完毕,而且优化完成了,可以完美收工了。但是在测试过程中偶然去掉了实例化 Regex 的代码中的 RegexOptions.Compiled,相关代码如下:
private static bool IsSplitter(string curLine)
{
using (var autoLogger = new AutoScopeLogger("[IsSplitter]"))
{
var splitterRegex = new Regex(@"-{100,}", RegexOptions.IgnoreCase);
MatchCollection matches = splitterRegex.Matches(curLine);
return (matches.Count > 0);
}
}
您猜耗时多久?与全局变量版本非常接近,大概耗时 79ms。surprise!

看来还有东西没“格”尽啊!下篇文章再格吧。