
公厕里的二进制究竟写的什么
hello,大家春节好啊,我是小楼。
春节带娃逛公园,在公园厕所里发现了一张有意思的图:

好几种语言写的 “往前一小步,文明一大步”,男同胞应该大部分都看过类似的标语,但这个二进制有点意思。
我把这个图发给一个公务员朋友,他说这个只有你们程序员看得懂,我说我也看不懂。
原来在外行眼里,程序员竟然还能看懂二进制~
回到家后,我在想,这二进制究竟写的啥?难道设计者是程序员?又或许是设计者瞎写的?
为了看懂这段二进制,得先想办法把这段01组成的文本搞出来。
靠肉眼加手敲显然不行,我想到了微信自带的识别文字:

显然不对,丢了很多。
接着我想到了 OCR,但是搜了一下发现全是接口文档的广告,还需要自己实现,显然不可能为了识别一张图片去开发个程序,于是又继续搜如何提取图片文字,发现了一款微信小程序,试了下,还真就识别出来了

11100101100100001001000111100101100010011000110111100100101110001000000011100101101100001000111111100110101011011010010100100000111001101001011010000111111001101001100010001110111001001011100010000000111001011010010010100111
111001101010110110100101
看了下,248个0和1的组合,248比较特殊,可以被8整除,斗胆猜测是 ASCII 码,每8位表示一个,于是我简单写了个Go程序验证下:
func TestBinary(t *testing.T) {
str := "11100101100100001001000111100101100010011000110111100100101110001000000011100101101100001000111111100110101011011010010100100000111001101001011010000111111001101001100010001110111001001011100010000000111001011010010010100111111001101010110110100101"
for i := 0; i < len(str); i = i + 8 {
code, _ := strconv.ParseInt(str[i:i+8], 2, 64)
fmt.Printf("%c", int(code))
}
}
结果一运行出现了:
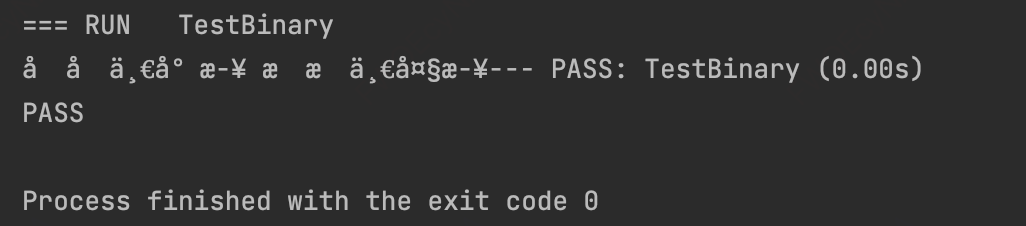
这是啥玩意?难道是我代码写错了?

于是我想直接问一下百度,这串二进制如何转换为ASCII码

百度丢给我一段 python 代码,虽然我对 py 不太熟,但还是知道怎么运行,于是我把它粘贴到文件里,保存为 test.py 文件,然后执行 python test.py
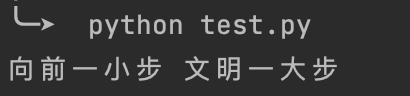
AI 还真是厉害!
原来这里是对中文的编码,我一直以为是英文。这里应该是 unicode 编码,通常用 UTF-8 来存储 unicode 字符,它是一种变长的存储方式,比较节省空间,使用1~4个字节表示字符,汉字通常是3~4个字节。
那么问题来了,给一串二进制怎么知道字符使用了几个字节表示呢?其实是有个规定:
- 1字节:0xxx xxxx
- 2字节:110x xxxx 10xx xxxx
- 3字节:1110 xxxx 10xx xxxx 10xx xxxx
- 4字节:1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx
用上面的二进制举例,可以把第一个汉字捞出来:
1110 0101 1001 0000 1001 0001
对应上面规则为3字节,再把固定的前缀去掉,得到unicode编码:
0101 0100 0001 0001
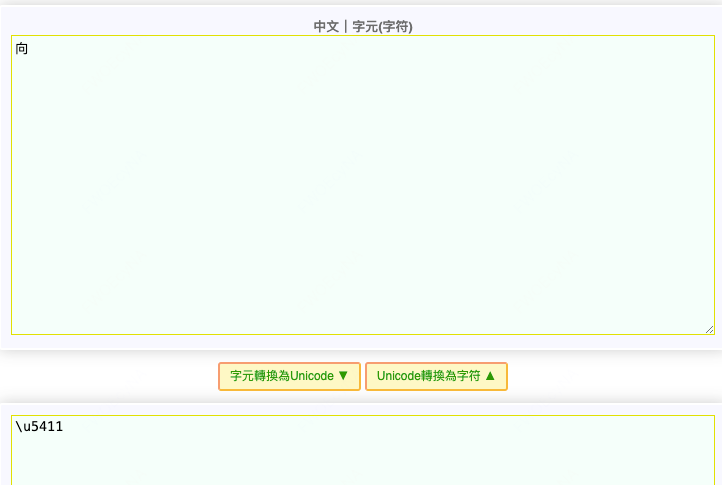
转换为16进制:\u5411,查询下果然是“向”
同理可得其他字符。按照这个逻辑来写代码解析就比较简单了,但 python 的 chr 函数还是有点意思,为什么这么说呢?因为它不是按照我们这个逻辑去解析的,它是固定8位8位地解析,结果也能解析完整。如果把每次调用 chr 的结果都输出,你就会发现它的厉害之处:
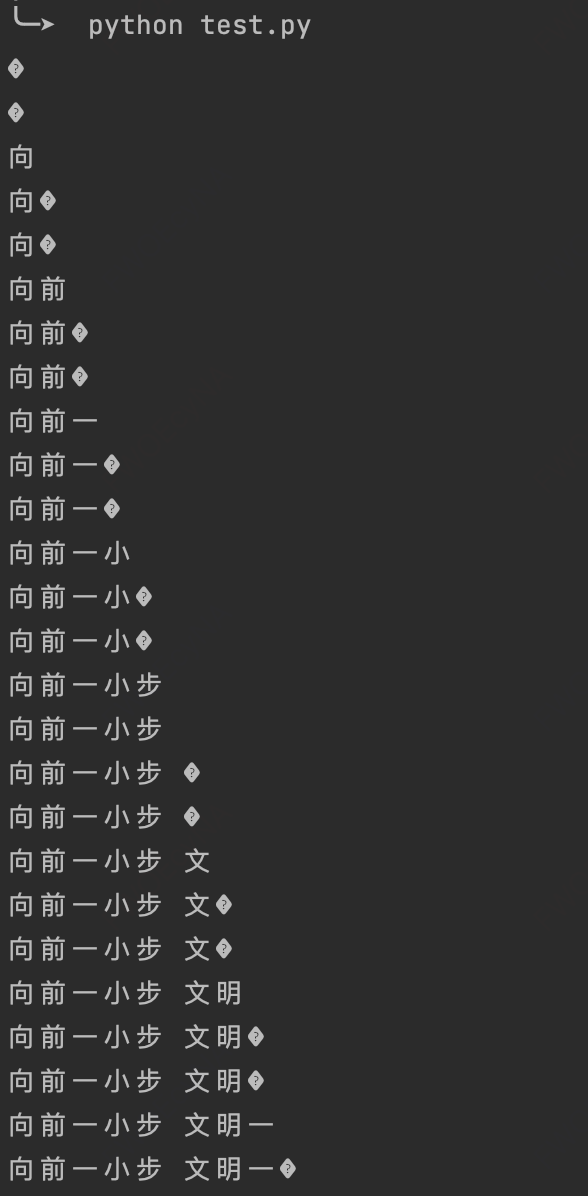
好了 python 这个彩蛋留给大家去探索,本文到此为止,我们下期再见~