为什么说强化学习是针对优化数据的监督学习?
共
4417字,需浏览
9分钟
·
2021-01-27 13:09

作者 | Ben Eysenbach、Aviral Kumar、Abhishek Gupta 出品 | AI科技大本营(ID:rgznai100)强化学习(RL)可以从两个不同的视角来看待:优化和动态规划。其中,诸如REINFORCE等通过计算不可微目标期望函数的梯度进行优化的算法被归类为优化视角,而时序差分学习(TD-Learning)或Q-Learning等则是动态规划类算法。虽然这些方法在近年来取得了很大的成功,但依然不能很好地迁移到新任务上。相较于这些强化学习方法,深度监督学习能够很好的在不同任务之间进行迁移学习,因此我们不禁问:是否能将监督学习方法用在强化学习任务上?
在这篇博文中,我们讨论一种理论上的强化学习模型。首先我们认为强化学习可以看作是高质量数据上的监督学习,在此基础上,获取高质量数据(好数据)本身也具有挑战性(除非是模仿学习),因此强化学习可以进一步看作是针对策略和数据的联合优化问题。从监督学习的角度来看,许多强化学习算法可以被认为是在交替地寻找更好数据 和 对数据进行监督学习。那么如何更有效地获取更好地数据呢?事实证明在多任务环境下,或者在多个问题可以相互转换的条件下更容易获取优质数据。因此,我们主要讨论如何从数据优化的角度来理解诸如hindsight relabeling数据增强法和inverse RL等技术。接下来我们将首先回顾强化学习的两个主要研究视角,即优化和动态规划,然后将从有监督视角深入探讨强化学习。优化视角将强化学习看作是一个最优化问题,只不过目标函数是一个不可导的函数,具体地,期望回馈函数是参数θ在策略下的函数:该函数不仅复杂,且往往不可导,这是因为他取决于依照策略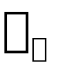 选择的动作(action)以及当前的环境情况。虽然我们可以通过REINFORCE技巧来估计该函数的梯度,但这个梯度仍然依赖于策略参数和数据,而这些数据又通过在模拟器上运行策略得到。不同于优化视角,动态规划观点认为强化学习可以分解为包含多步,并在每一步选择正确行动的多阶段优化问题。通过现有的离散动态理论,我们可以精确地解决这个动态规划问题。例如,例如,Q-learning通过迭代以下更新来估计状态-动作值Q(s,a):在连续空间或状态空间和动作空间较大的情况下,我们可以使用函数逼近器(如神经网络)表示q函数来近似动态规划,并将TD误差的差值最小化,TD误差是上述方程中LHS和RHS之间的平方差值:其中TD目标函数为:
选择的动作(action)以及当前的环境情况。虽然我们可以通过REINFORCE技巧来估计该函数的梯度,但这个梯度仍然依赖于策略参数和数据,而这些数据又通过在模拟器上运行策略得到。不同于优化视角,动态规划观点认为强化学习可以分解为包含多步,并在每一步选择正确行动的多阶段优化问题。通过现有的离散动态理论,我们可以精确地解决这个动态规划问题。例如,例如,Q-learning通过迭代以下更新来估计状态-动作值Q(s,a):在连续空间或状态空间和动作空间较大的情况下,我们可以使用函数逼近器(如神经网络)表示q函数来近似动态规划,并将TD误差的差值最小化,TD误差是上述方程中LHS和RHS之间的平方差值:其中TD目标函数为: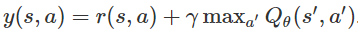 ,注意这是Q函数的损失函数,而不是整个策略的损失函数。这种方法允许我们使用任何类型的数据来优化Q函数,而不依赖于高质量数据。但这种方法也存在优化结果的质量问题,即可能收敛到较差的解决方案,因此可能很难应用到新问题上。
,注意这是Q函数的损失函数,而不是整个策略的损失函数。这种方法允许我们使用任何类型的数据来优化Q函数,而不依赖于高质量数据。但这种方法也存在优化结果的质量问题,即可能收敛到较差的解决方案,因此可能很难应用到新问题上。
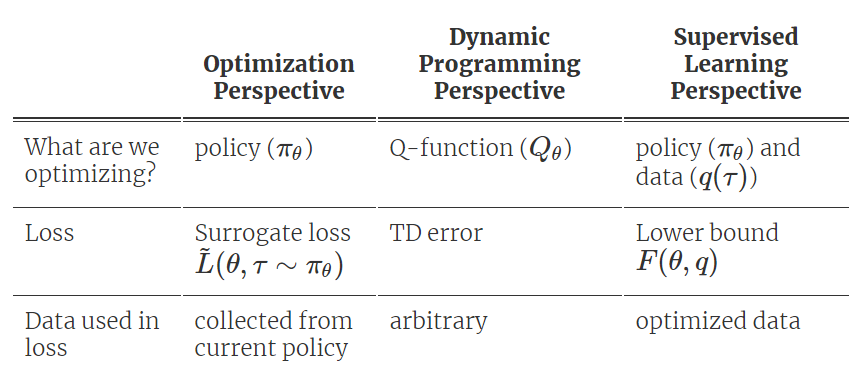
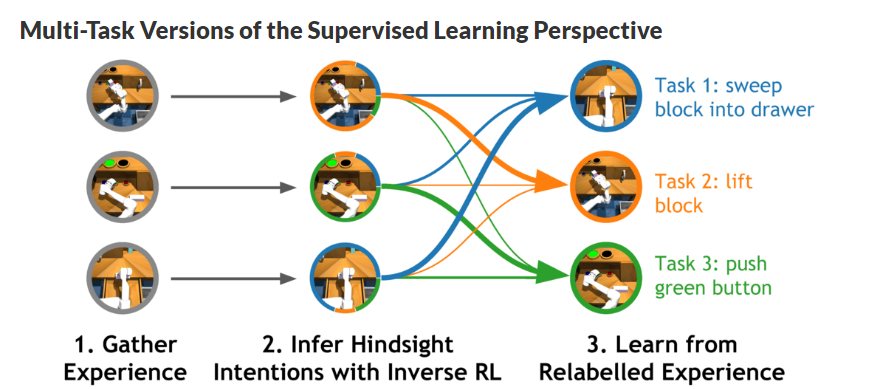
我们现在讨论另一种强化学习理论模型,其主要思想是将RL视为策略和经验的联合优化问题,即我们希望找到高质量数据和良好策略。直觉上,我们期望高质量数据满足:我们将好的政策简单地定义为可能产生好数据的政策。如下图:许多旧的和新的强化学习算法可以被看作是在优化数据上进行行为克隆(即监督学习)。这里主要讨论了最近将这一想法扩展到多任务视角的工作,在多任务视角下优化数据实际上变得“更容易”了。把“好的数据”转换成“好的策略”很容易,只需要进行监督学习即可。然而,将“好的策略”转换为“好的数据”稍微更具挑战性,我们将在下一节中讨论几种方法。事实证明,在多任务场景中,或者通过人为地稍微修改问题定义,将“好的策略”转换为“好的数据”要容易得多。倒数第二部分将讨论如何在多任务场景中重新标记目标,修改问题定义,以及通过inverse RL提取“好的数据”。现在我们通过期望最大化的方式来公式化监督学习视角[Dayan 1997, Williams 2007, Peters 2010, Neumann 2011, Levine 2013]。为了简化表示,我们使用 πθ(τ) 作为策略 πθ 产生轨迹 τ 的概率,并使用 q(τ) 表示将优化的数据分布。同时我们将预期奖励目标函数以对数形式表示为logJ(θ),由于对数函数是单调递增的,因此最大化对数函数等同于最大化期望回报。然后我们应用Jensen不等式将对数移动到期望内:Jensen不等式得到了目标函数的一个下界。这个下界的有用之处在于,它允许我们使用来自不同策略的采样数据来优化策略。同时这个下界也明确表明,强化学习是一个关于策略和经验(数据)的联合优化问题。下表将监督学习视角与优化和动态规划视角进行了比较:因此寻找好的数据和策略等同于优化函数下限F(θ,q)。最优化下界的一个常用方法是对其参数进行坐标上升,即交替循环地对数据分布 q(τ) 和策略 πθ 进行优化,直至收敛。这个观察结果令人兴奋,因为监督学习通常比RL算法稳定得多。此外,这一观察结果表明,之前使用监督学习作为子任务的RL方法[Oh20 18, Ding 2019]实际上可能在优化期望回报的下限。数据分布的优化目标是在不偏离当前策略太远的情况下最大化期望回报,因此需要一个额外的约束:上面的KL约束使得对数据分布的优化较为保守,宁愿以略低的回报为代价保持在当前策略的附近。优化对数回报而不是期望回报,进一步降低了优化问题的风险性,因为对数log函数时一个凹函数。有很多方法可以优化数据分布。一个直观的(如果效率低下的话)方法是用当前策略的一个来噪声版本来收集经验,并保留获得最高奖励的10%的经验。另一种方法是轨迹优化,即沿单一轨迹来优化状态。第三种方法则通过当前奖励来重新调整之前收集的数据轨迹的权重。此外,数据分布q(τ)可以有多种表示方式——根据先前的观测轨迹继非参数离散分布,或分解每一对状态-动作的分布,亦或是半参数模型。有许多之前的算法隐式地进行了策略优化和数据优化。例如,奖励加权回归 [Williams 2007]和优势加权回归[Neumann 2009, Peng 2019]通过对奖励数据和加权数据进行行为克隆,将这两个步骤结合起来。自我模仿学习[Oh 2018]根据奖励来对观察轨迹进行排序,并选择top-k个轨迹的平均分布来得到数据分布。MPO [Abdolmaleki 2018]通过从策略中采样动作,构建一个数据集,重新对那些预期会带来高回报(即高回报+价值)的动作进行权重分配,然后对这些动作执行行为克隆。许多近期的多任务强化学习算法根据每个轨迹所解决的任务来整合他们。这种事后组织的过程与hindsight labeling和反向RL密切相关,是近年来基于监督学习的多任务RL算法的核心思想。近期的一些工作可以看作是这些算法的变体,主要变化是在多任务场景中寻找好数据变得更加容易了。这些工作要么在多任务设置中直接操作,要么修改单任务设置,使其看起来像一个任务。当我们增加任务的数量时,所有的经验对于某些任务来说都是最佳的。我们可以从这个角度来分析近期的三篇工作:条件目标模仿学习[Savinov 2018, Ghosh 2019, Ding 2019, Lynch 2020]在一个有具体目标的任务中,我们的数据包括状态(state)和动作(action),以及尝试的目标。也许算法没有达到指令目标,但对于它的实际目标来说是成功的,因此我们可以通过用实际达到的目标替换原来的指令目标,从而优化数据分布。因此,由目标条件模仿学习[Savinov 2018, Ghosh 2019, Ding 2019, Lynch 2020]和后验经验回顾 [Andrychowicz 2017 ]进行的后验重标记,可被视为对非参数型数据分布的优化。此外,目标条件模仿可以看作是简单地在优化数据上进行监督学习(即行为克隆)。有趣的是,当这种带有重新标签的目标条件模仿过程被迭代地重复时,可以证明这是一个从头开始学习策略的收敛过程,即使根本没有提供专家数据![Ghosh 2018]这是非常有前途的方法,因为它从本质上为我们提供了一种不用明确地要求任何引导或价值函数学习的强化学习技术,显著地简化了算法和调优过程。条件回报策略[Kumar 2019, Srivastava 2019]有趣的是,如果我们可以将从次优政策中收集的非专家轨迹视为对某些任务类的最优监督,我们可以将上面讨论的内容扩展到单任务强化学习场景。当然,这些次优轨迹可能不会使回报最大化,但它们在匹配给定轨迹的回报时是最优的,这也是条件回报策略的含义所在。虽然实现目标的算法和数据集优化之间的联系是清晰的,但直到最近人们还不清楚如何将类似的想法应用到更一般的多任务场景中,比如一个离散的奖励函数集,或者由奖励和惩罚条件的可变(线性)组合定义的奖励集。为了解决这个开放问题,我们从优化数据分布对应于回答以下问题的直觉开始:“如果你假设你的经验是最佳的,你试图解决什么任务?”有趣的是,这正是inverse RL所回答的问题。我们可以简单地使用inverse RL在任意多任务场景中重新标记数据,反向RL为跨任务共享经验提供了理论上的基础机制。 未来的探索方向在本文中,我们讨论了如何将RL视为使用优化的(重新标定的)数据来解决一系列标准监督学习问题。深度监督学习在过去十年的成功表明,这种方法在实践中可能更容易使用。虽然到目前为止进展很有希望,但仍有几个尚未解决的问题。首先,是否还有其他(更好的)方式可以获得最优化的数据? 重估或重新组合现有经验是否会在学习过程中产生偏差? RL算法应该如何探索以获得更好的数据? 在这方面取得进展的方法和分析也可能为从RL的不同角度衍生的算法提供深刻见解。其次,这些方法可能提供了一种简单的方法,将实践技术和理论分析从深度学习转移到RL,否则由于非凸目标(如政策梯度)或优化和测试时间目标不匹配(如Bellman误差和政策回报)而难以实现。我们非常看好这些方法提供的几个可能的应用前景,例如改进的实用RL算法,改进对RL方法的理解等等。https://bair.berkeley.edu/blog/2020/10/13/supervised-rl/
未来的探索方向在本文中,我们讨论了如何将RL视为使用优化的(重新标定的)数据来解决一系列标准监督学习问题。深度监督学习在过去十年的成功表明,这种方法在实践中可能更容易使用。虽然到目前为止进展很有希望,但仍有几个尚未解决的问题。首先,是否还有其他(更好的)方式可以获得最优化的数据? 重估或重新组合现有经验是否会在学习过程中产生偏差? RL算法应该如何探索以获得更好的数据? 在这方面取得进展的方法和分析也可能为从RL的不同角度衍生的算法提供深刻见解。其次,这些方法可能提供了一种简单的方法,将实践技术和理论分析从深度学习转移到RL,否则由于非凸目标(如政策梯度)或优化和测试时间目标不匹配(如Bellman误差和政策回报)而难以实现。我们非常看好这些方法提供的几个可能的应用前景,例如改进的实用RL算法,改进对RL方法的理解等等。https://bair.berkeley.edu/blog/2020/10/13/supervised-rl/
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报

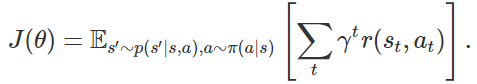
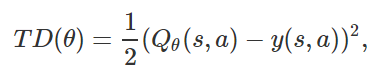




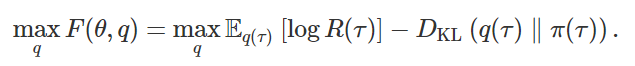
 下载APP
下载APP