
浅谈RabbitMQ的基石—高级消息队列协议(AMQP)
点击上方蓝色字体,选择“设为星标”




前言
自从去年做了不少流式系统(Flink也好,Spark Streaming也好)对接RabbitMQ的实时作业。之前一直都在Kafka的领域里摸爬滚打,对RabbitMQ只是有浅薄的了解而已。随着自己逐渐把RabbitMQ的官方文档大致翻完,了解到它是高级消息队列协议(Advanced Message Queuing Protocol, AMQP)的一种标准实现。也就是说,搞清楚AMQP是掌握好RabbitMQ哲学的基础。
当前AMQP的最新版本为1.0,而主要使用的(也是RabbitMQ实现的)版本为0-9-1。这两个版本之间的差别非常大,本文抄录的是AMQP 0-9-1的部分细节。
AMQP及其模型
通俗地讲,AMQP是一个专门为消息中间件设计的、开放标准的应用层协议,它规定了消息系统中三大组件——消息服务器/代理节点(server/broker)、生产者/发布者(producer/publisher)、消费者/订阅者(consumer/subscriber)之间的通信规范,以及代理节点的设计规范等。
AMQP采用的模型就叫做高级消息队列模型,即AMQ模型,它的组成可以用下面的简图来表示。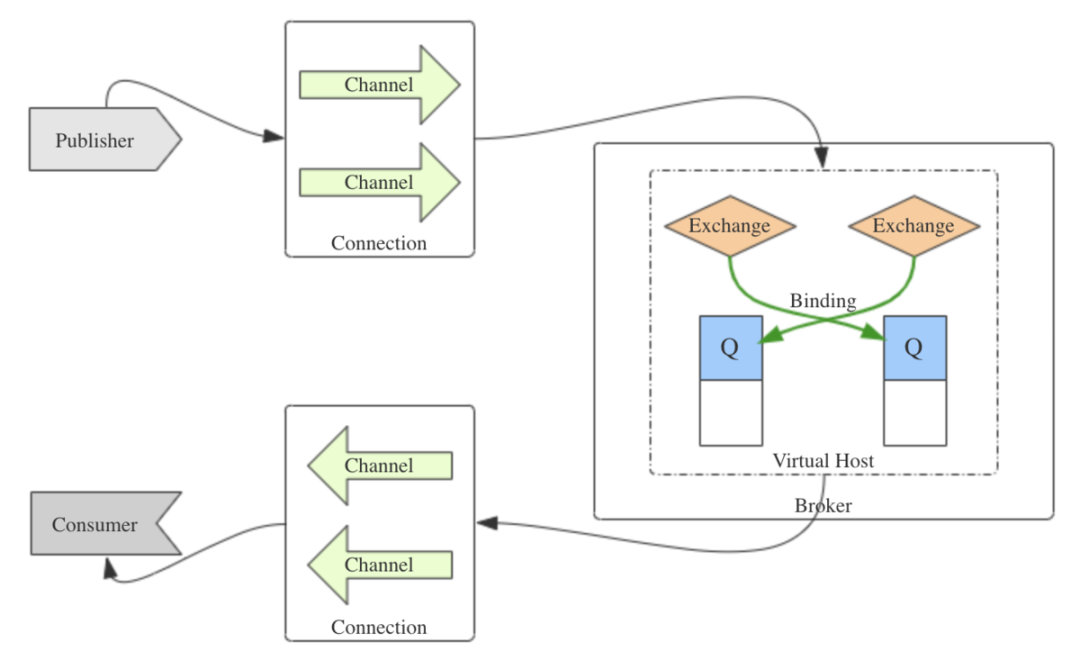
下面就图中出现的一些名词进行解释。
交换器(exchange):负责将生产者发来的消息按照特定的路由关键字(routing key)投递到相应的队列。
队列(queue):代理节点中存储将要被消费的消息的载体。
绑定(binding):交换器与队列之间的映射关系,可以理解为消息的路由规则。
AMQP实体(AMQP entity):交换器、队列和绑定三者合起来就称为一个AMQP实体,图中未示出。交换器、队列和绑定都可以有一个或多个。
虚拟主机(virtual host):在代理节点上逻辑划分的隔离的环境,其内部包含一个或多个AMQP实体,且虚拟主机之间互不影响。虚拟主机可以复用节点,并实现权限管理和多租户。
连接(connection):发布者、消费者与代理节点之间建立的连接,为了保证可靠性,一般都是TCP长连接。
通道(channel):对连接的轻量级复用,主要针对多线程的发布者、消费者,因为建立多个TCP连接是很贵的操作,频繁建立和销毁连接也是不科学的。
接下来对交换器和队列这两个比较重要的组件进行介绍,顺便牵出一些其他的东西。
交换器
交换器在AMQP实体中负责消息路由。它的路由目的地除了由用户设置的绑定规则来决定之外,还与交换器的类型有关。AMQP定义了几种默认的交换器。
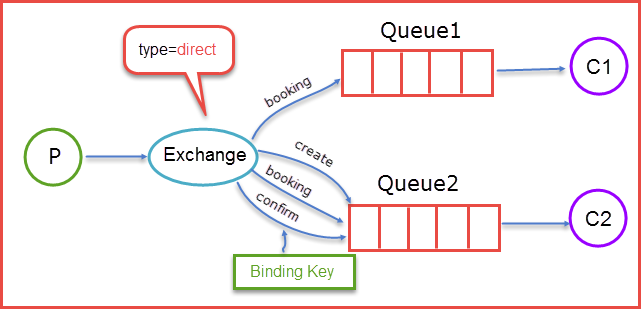
直连交换器(direct exchange)
直连交换器非常简单,它检查绑定关键字(binding key)与路由关键字(routing key),只要两者相同,即进行投递。
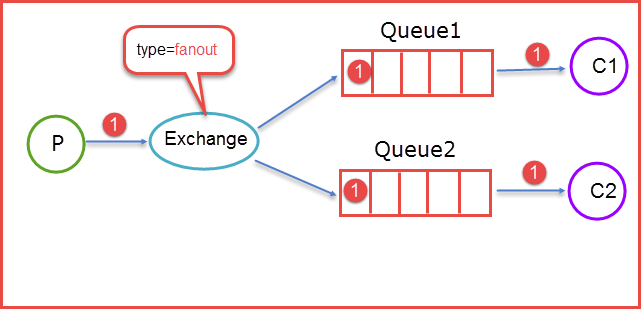
扇出交换器(fanout exchange)
扇出交换器比直连交换器更简单,它会直接将消息路由到所有与它绑定的队列中。
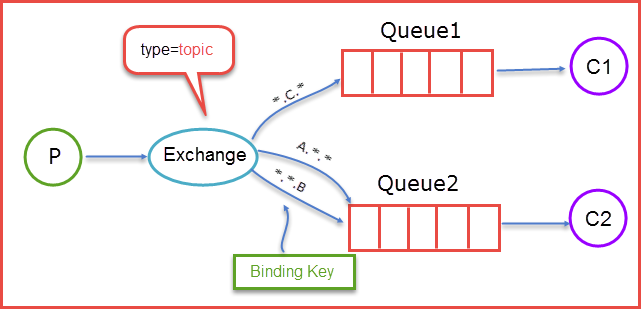
主题交换器(topic exchange) 此主题非彼(对就是Kafka里的)主题,而更类似wildcard matching。具体来讲,绑定关键字是由多个域组成的点号分隔的字符串,每个域可以是实际的单词,也可以是通配符,如星号 " * " 表示一个词,"#" 表示0个或多个词。在实际路由时,根据路由关键字与绑定关键字的匹配结果来投递。比如在下图中,带有"little.C.magic"关键字的消息会投递到队列1,而带有"bla.bla.B"关键字的消息会投递到队列2。
头部交换器(header exchange) AMQP消息与HTTP报文的格式类似,都有头部(header)和消息体(body),其中头部会保存与消息相关的许多元数据,消息体才是有效的载荷(payload)。头部交换器就不依赖绑定关键字和路由关键字的匹配,而是检查消息头部中的元数据是否匹配,相对而言更加灵活。
根据AMQP的规定,交换器的几个重要属性有:
名称(name);
持久性(durable):当代理节点或虚拟主机重置后,交换器是被保留还是被删除;
自动删除(auto-delete):是否在所有队列的绑定解除之后被删除;
扩展参数(arguments)。
如果交换器无法将消息路由到队列该怎么办呢?AMQP给出了几种解决方法,一是直接丢弃,二是返还给生产者,三是放入死信队列中等待进一步处理。这由消息头部中的属性来决定。
队列和消息
队列相对而言比较简单,它的主要功能就是存储要被消费的消息。队列也有一些重要的属性,如下:
名称(name);
持久性(durable):当代理节点或虚拟主机重置后,队列是被保留还是被删除;
独占性(exclusive):是否只允许被一个连接使用;
自动删除(auto-delete):是否在所有消费者取消订阅之后被删除;
扩展参数(arguments):如队列缓存长度、消息TTL等。
需要注意,如果一个队列是持久的,那么只是代表重启之后这个队列不用重新创建而已,但其中的消息还是有可能被删除。只有那些被标记为persistent的消息才不会被删除。
AMQP规范下的队列和消费者都同时支持推模式和拉模式消费。前者即AMQP实体将消息投递到消费者,后者即消费者主动地从队列中获取消息。无论推模式还是拉模式,每个消费者也有一个标识,称为tag。
在队列中的消息投递出去之后,消费者需要告诉代理节点自己是否收到了它,因此会涉及消息确认(ack)的问题。AMQP默认定义了两种ack机制:
自动ack:当消息从队列中出去后就删除它(即at most once);
显式ack:当消费者发送的确认回执到达代理节点后,再从队列中删除它。如果ack超时,则会再次尝试投递(即at least once)。
除了ack之外,消费者在处理时有可能会出现问题,或认为此消息非法,因此也会出现拒绝消息(reject)的情况。此时代理节点可以销毁这条消息,也可以重新将它放入队列并投递给另一个消费者。
vs Kafka?
说了这么多,那么Kafka和AMQP有什么关系呢?答案是没关系。
也就是说,Kafka不是消息队列。按官方说法,Kafka是一个流式处理平台(stream processing platform)。Kafka在设计之初是为了支持高吞吐量的日志处理的,只不过它恰好也可以实现消息队列的大部分功能而已。Kafka所用的“黑科技”(如零拷贝/内存映射,以及对page cache的利用)都是脱离标准消息队列的设计范畴的,所以不能简单地认为Kafka比RabbitMQ等符合AMQP的消息队列更优。例如,RabbitMQ支持死信队列、延迟队列、优先队列、多租户、推模式消费等,Kafka统统不支持。


版权声明:
文章不错?点个【在看】吧! ?