
每日一道 LeetCode (9):实现 strStr()

❝每天 3 分钟,走上算法的逆袭之路。
❞
前文合集
每日一道 LeetCode 前文合集
代码仓库
GitHub:https://github.com/meteor1993/LeetCode
Gitee:https://gitee.com/inwsy/LeetCode
题目:实现 strStr()
题目来源:https://leetcode-cn.com/problems/implement-strstr/
实现 strStr() 函数。
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
示例 1:
输入: haystack = "hello", needle = "ll"
输出: 2
示例 2:
输入: haystack = "aaaaa", needle = "bba"
输出: -1
说明:
当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与 C 语言的 strstr() 以及 Java的 indexOf() 定义相符。
解题思路:暴力方案
解题思路?
这道题还搞啥解题思路?
题目都直接把答案写出来了,「这与 C 语言的 strstr() 以及 Java的 indexOf() 定义相符」,我直接用 indexOf() 它不香么?
public int strStr(String haystack, String needle) {
return haystack.indexOf(needle);
}
看着效率,杠杠的,我可真是个小机灵鬼。

但是如果你在面试的时候这么答,会不会被面试打个半死我就不知道了。
那么接下来,最符合常人的暴力思路来袭,我就喜欢干这事儿。
借一张官方的图:
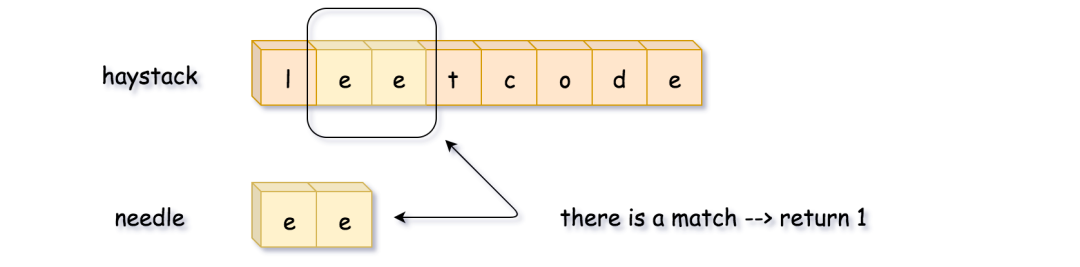
我做一个循环,直接比较 needle 长度的字符串,如果相等就可以直接返回了,如果比到最后没比出来,就返回 -1 ,解题结束。
我就是这么的直接。。。以及。。。暴力。。。
能用暴力解决的问题,绝不多动脑子。
public int strStr_1(String haystack, String needle) {
int h = haystack.length(), n = needle.length();
for (int i = 0; i < h - n + 1; i++) {
if (needle.equals(haystack.substring(i, i + n))) {
return i;
}
}
return -1;
}
好像结果也还算可以嘛,没有那种慢到不可接受。
解题思路:暴力方案优化
做完题好习惯看看答案,然后知道了我上面的这种暴力方案是基于一个叫 「滑动窗口」 的东西,这个名字倒是蛮形象的。
上面的暴力方案有一个缺点是,会将 haystack 所有长度为 n 的子串都和 needle 做比较,那么能不能少比较几次呢?
当然是可以的,以下内容来源于官网:
第一件事儿就是只有第一个字符相等的才有比较的意义,如果第一个字符都不相等,这也就不用比了(图片来源于官方)。
接着一个字符一个字符比较,一旦不匹配了就立刻终止(图片来源于官方)。
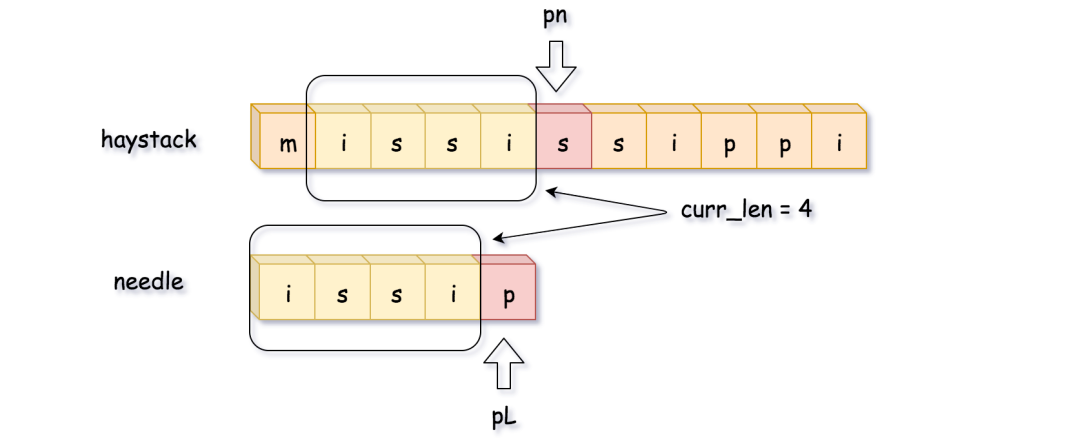
截止到目前,都还是很好理解的,下面这一步就稍微有点抽象了,而这个方案的精髓也是下面这一步。
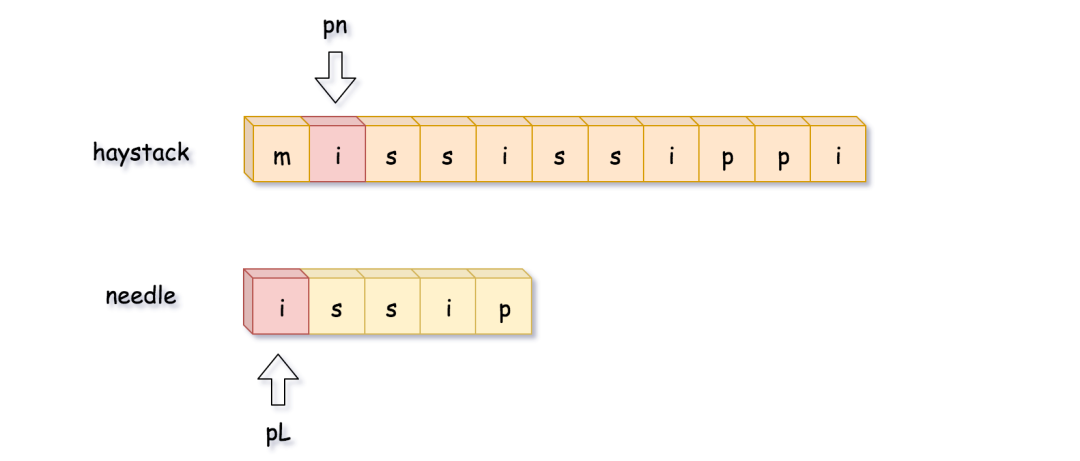
这里,比较到最后一位的时候发现不匹配,开始回溯。需要注意的是,pn 指针是移动到 pn = pn - curr_len + 1 的位置(图片来源于官方)。
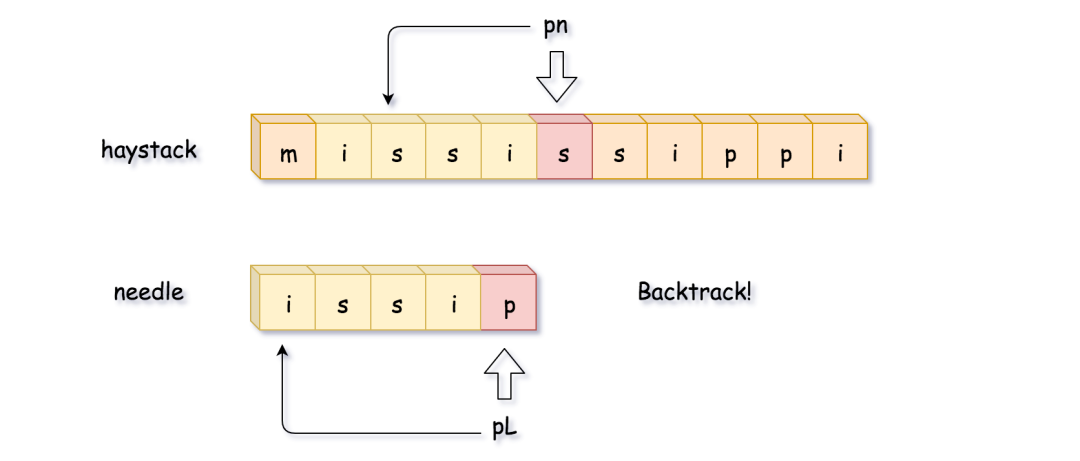
在这之后,接着 ++pn ,寻找开头和 needle第一位相同的子串,找到之后重复上面的比较的过程,然后找到了答案置(图片来源于官方)。
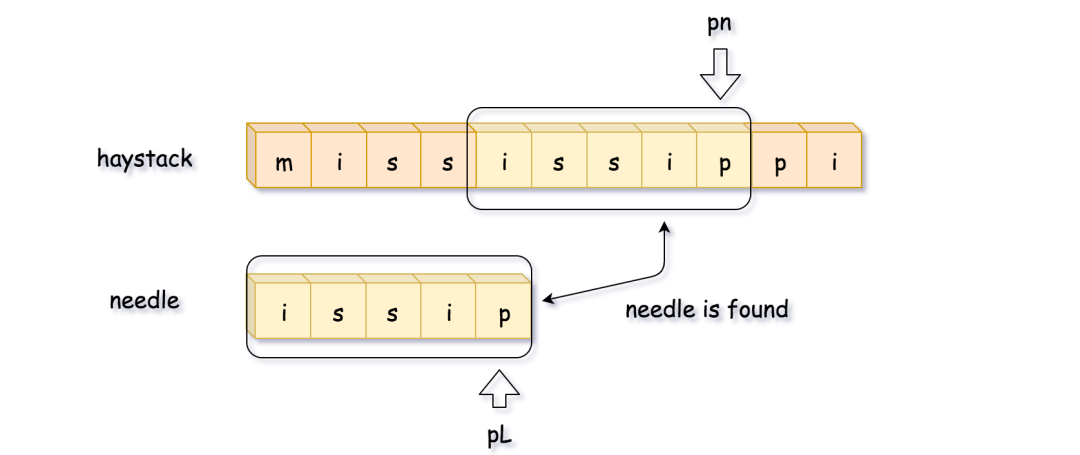
实现代码如下(代码来自于官方):
public int strStr_2(String haystack, String needle) {
int L = needle.length(), n = haystack.length();
if (L == 0) return 0;
int pn = 0;
while (pn < n - L + 1) {
// 第一次循环 pn ,寻找和 needle 第一位相同的子串
while (pn < n - L + 1 && haystack.charAt(pn) != needle.charAt(0)) ++pn;
// 从 pn 开始,按位比较字符,获得相同位数长度 currLen
int currLen = 0, pL = 0;
while (pL < L && pn < n && haystack.charAt(pn) == needle.charAt(pL)) {
++pn;
++pL;
++currLen;
}
// 如果 currLen 长度等于 needle 长度,匹配结束
if (currLen == L) return pn - L;
// 如果不等于,开始回溯
pn = pn - currLen + 1;
}
return -1;
}
这段代码自己做了字符的循环比较,但是很不幸,这种比较方案要比使用 equals() 来的要慢,我稍微修改下:
public int strStr_3(String haystack, String needle) {
int L = needle.length(), n = haystack.length();
if (L == 0) return 0;
int pn = 0;
while (pn < n - L + 1) {
// 第一次循环 pn ,寻找和 needle 第一位相同的子串
while (pn < n - L + 1 && haystack.charAt(pn) != needle.charAt(0)) ++pn;
// 如果 pn + L 的长度大于当前字符串长度,直接返回 -1
if (pn + L > n) return -1;
// 如果 pn + L 得到的子串和 needle 相同,直接返回 pn
if (haystack.substring(pn, pn + L).equals(needle)) {
return pn;
}
// 没匹配到 ++pn
++pn;
}
return -1;
}
思路还是同样的思路,但是我在字符串的比较换成了 equals() ,耗时重回 1ms 。
抛砖引玉
到这里,我们往回看一个问题,为啥 jdk 提供的 indexOf() 这个方法,可以把耗时压缩到 0ms ?为何 indexOf() 这个方法如此 NB ?
点开源码,找到核心方法(jdk 版本: 1.8.0_221):
static int indexOf(char[] source, int sourceOffset, int sourceCount,
char[] target, int targetOffset, int targetCount,
int fromIndex) {
// 1、当开始查找位置 大于等于 源字符串长度时,如果[查找字符串]为空,则:
// 返回字符串的长度,否则返回-1.
if (fromIndex >= sourceCount) {
return (targetCount == 0 ? sourceCount : -1);
}
// 2、如果 fromIndex 小于 0 ,则从 0 开始查找。
if (fromIndex < 0) {
fromIndex = 0;
}
// 3、如果[查找字符串]为空,则返回 fromIndex
if (targetCount == 0) {
return fromIndex;
}
// 4、开始查找,从[查找字符串]中得到第一个字符,标记为 first
char first = target[targetOffset];
int max = sourceOffset + (sourceCount - targetCount);
// 4.1、计算[源字符串最大长度]
for (int i = sourceOffset + fromIndex; i <= max; i++) {
// 4.2.1、从[源字符串]中,查找到第一个匹配到[目标字符串] first 的位置
// for循环中,增加 while 循环
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
// 4.2.2、如果在[源字符串]中,找到首个[目标字符串],
// 则匹配是否等于[目标字符串]
/* Found first character, now look at the rest of v2 */
if (i <= max) {
// 4.2.2.1、得到下一个要匹配的位置,标记为 j
int j = i + 1;
// 4.2.2.2、得到其余[目标字符串]的长度,标记为 end
int end = j + targetCount - 1;
// 4.2.2.3、遍历,其余[目标字符串],从 k 开始,
// 如果 j 不越界(小于 end ,表示:其余[目标字符串]的范围),
// 同时[源字符串]==[目标字符串],则
// 自增,继续查找匹配。j++ 、 k++
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
// 4.2.2.4、如果 j 与 end 相等,则表示:
// 源字符串中匹配到目标字符串,匹配结束,返回 i 。
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
这段代码看起来平平无奇,而且查找的方式和我们上面的优化方案非常像,都是先查找首个匹配字符,然后再做循环查找整个匹配的字符串。
单纯的靠代码优化把耗时从 2ms 缩减到了 0ms ,只能是一个大写的佩服,不愧是写 jdk 源码的大神。
