
?线程池为什么可以复用,我是蒙圈了。。。
点击上方 好好学java ,选择 星标 公众号
重磅资讯、干货,第一时间送达
重磅资讯、干货,第一时间送达
今日推荐:硬刚一周,3W字总结,一年的经验告诉你如何准备校招!
个人原创100W+访问量博客:点击前往,查看更多
个人原创100W+访问量博客:点击前往,查看更多
本章目录
一、线程池状态
二、execute源码
三、addworker源码
四、Worker源码
五、runworker源码
六、getTask源码
七、总结
八、题外话
看了源码才知道,我还是太菜了。。
一、线程池状态
首先我们要明确线程池的几种状态
1. RUNNING
这个状态表明线程池处于正常状态,可以处理任务,可以接受任务
2. SHUTDOWN
这个状态表明线程池处于正常关闭状态,不再接受任务,但是可以处理线程池中剩余的任务
3. STOP
这个状态表明线程池处于停止状态,不仅不会再接收新任务,并且还会打断正在执行的任务
4. TIDYING
这个状态表明线程池已经没有了任务,所有的任务都被停掉了
5. TERMINATED
线程池彻底终止状态
他们的状态转换图如下
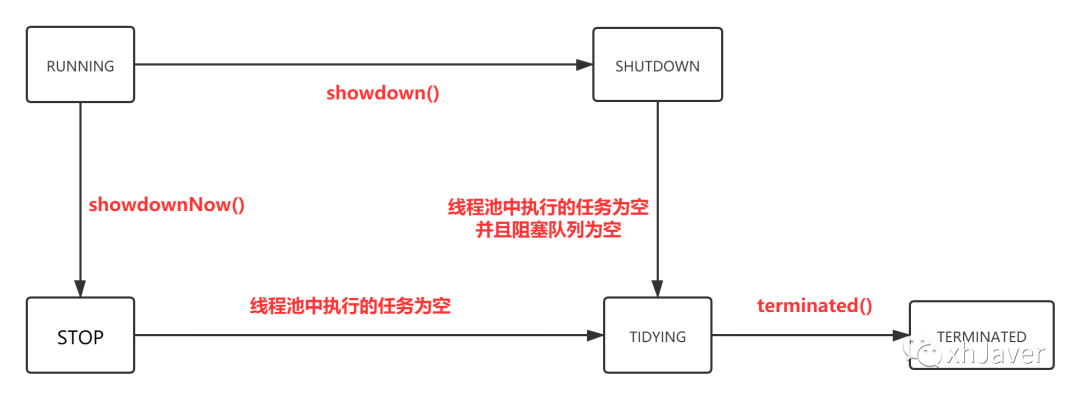
好了,知道了线程池的几种状态和他们是如何转换的关系之后,我们来看一下
当我们提交一个任务时,线程池到底发生了什么?!
我们平常使用线程池是这样使用的
for (int i=0;i<10;i++){//创建10个任务Task task = new Task("task" + i);//让我们自定义的线程池去跑这些任务threadPoolExecutor.execute(task);}
我们来看一下 execute里面究竟有什么奇怪的东西?
二、execute源码
public void execute(Runnable command) {//1.先判断提交的任务是不是空的if (command == null)throw new NullPointerException();//2.获得线程池状态int c = ctl.get();//3.判断线程池数量是否小于核心线程数if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}//4.线程池数量大于等于核心线程数并且线程池处于Running状态,这时添加任务至阻塞队列if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();if (! isRunning(recheck) && remove(command))reject(command);else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 5.走到这里说明添加阻塞队列失败,// 创建非核心线程也失败的话,执行拒绝策略else if (!addWorker(command, false))reject(command);}
然后我们来看3那里,
//3.判断线程池数量是否小于核心线程数if (workerCountOf(c) < corePoolSize) {//如果小于核心线程数//3.1添加workerif (addWorker(command, true))//添加成功,返回return;//3.2添加失败,获取线程池状态c = ctl.get();}
我用头发想想都知道,线程复用的秘密肯定藏在了addworker里,哦对我没有头发 我们再来看一看他里面有什么鬼
三、addworker源码
private boolean addWorker(Runnable firstTask, boolean core) {//标志位,一会儿会跳过来retry:for (;;) {//判断线程池状态int c = ctl.get();int rs = runStateOf(c);//如果状态非法则返回falseif (rs >= SHUTDOWN && ! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()))return false;for (;;) {//判断线程池线程总数量int wc = workerCountOf(c);//如果数量不符合要求则返回falseif (wc >= CAPACITY || wc >= (core ? corePoolSize : maximumPoolSize))return false;//线程池数量加1if (compareAndIncrementWorkerCount(c))//跳到开始 retry处且往下执行,不在进入大循环break retry;//数量增加失败的话判断当前线程池状态若和刚才状态不一致则继续执行大循环c = ctl.get(); // Re-read ctlif (runStateOf(c) != rs)continue retry;}}boolean workerStarted = false;boolean workerAdded = false;Worker w = null;try {//将提交的任务封装进workerw = new Worker(firstTask);//得到worker中的线程final Thread t = w.thread;if (t != null) {final ReentrantLock mainLock = this.mainLock;mainLock.lock();try {//得到线程池状态int rs = runStateOf(ctl.get());//如果状态合法if (rs < SHUTDOWN ||(rs == SHUTDOWN && firstTask == null)) {if (t.isAlive())throw new IllegalThreadStateException();//将worker添加至workers中 (这是个set集合,真正的线程池)workers.add(w);//判断线程数量int s = workers.size();if (s > largestPoolSize)largestPoolSize = s;//添加worker成功workerAdded = true;}} finally {mainLock.unlock();}if (workerAdded) {//执行worker中的线程t.start();workerStarted = true;}}} finally {if (! workerStarted)addWorkerFailed(w);}return workerStarted;}
其中很重要的一段代码是
//将提交的任务封装进workerw = new Worker(firstTask);//得到worker中的线程final Thread t = w.thread;.........//执行worker中的线程t.start();
主要我们看这其中的worker是什么东西 (截取了worker中一部分源码)
四、Worker源码
private final class Workerextends AbstractQueuedSynchronizerimplements Runnable{private static final long serialVersionUID = 6138294804551838833L;/** Thread this worker is running in. Null if factory fails. */final Thread thread;/** Initial task to run. Possibly null. */Runnable firstTask;/** Per-thread task counter */volatile long completedTasks;Worker(Runnable firstTask) {//线程池状态设为runningsetState(-1); // inhibit interrupts until runWorker//用户提交的任务this.firstTask = firstTask;//通过创建一个线程,传入的this是woker自身 worker继承了Runnable 那么这个线程在t.start就是调用重写的run()方法了this.thread = getThreadFactory().newThread(this);}/** Delegates main run loop to outer runWorker */public void run() {runWorker(this);}
我们注意到刚才的t.start(),就是执行woker中的run方法,run方法又执行了runworker() 方法
我们再来看下 runworker() 方法
五、runworker源码
final void runWorker(Worker w) {//得到当前线程Thread wt = Thread.currentThread();//这是我们提交的任务Runnable task = w.firstTask;w.firstTask = null;w.unlock(); // allow interruptsboolean completedAbruptly = true;try {//线程复用的密码就在这里,是一个while循环,判断如果提交的任务不为空或者队列里有任务的话while (task != null || (task = getTask()) != null) {w.lock();if ((runStateAtLeast(ctl.get(), STOP) ||(Thread.interrupted() &&runStateAtLeast(ctl.get(), STOP))) &&!wt.isInterrupted())wt.interrupt();try {//执行前的函数,用户可以自己拓展beforeExecute(wt, task);Throwable thrown = null;try {//任务自己的run方法task.run();} catch (RuntimeException x) {thrown = x; throw x;} catch (Error x) {thrown = x; throw x;} catch (Throwable x) {thrown = x; throw new Error(x);} finally {//执行后的函数,用户可以自己拓展afterExecute(task, thrown);}} finally {task = null;w.completedTasks++;w.unlock();}}completedAbruptly = false;} finally {//销毁线程processWorkerExit(w, completedAbruptly);}}
重点来了,我们来看一下 getTask()
六、getTask源码
private Runnable getTask() {boolean timedOut = false; // Did the last poll() time out?for (;;) {int c = ctl.get();int rs = runStateOf(c);if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {decrementWorkerCount();return null;}//得到线程池线程数量int wc = workerCountOf(c);// 是否设置超时时间 allowCoreThreadTimeOut默认是false//判断线程池数量是否大于核心线程数,如果大于的话 timed为trueboolean timed = allowCoreThreadTimeOut || wc > corePoolSize;if ((wc > maximumPoolSize || (timed && timedOut))&& (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null;continue;}try {//这里 timed为ture的时候,采用带超时时间的获取元素的方法, 否则采取一直阻塞的方法Runnable r = timed ?workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :workQueue.take();//获取到任务就返回if (r != null)return r;timedOut = true;} catch (InterruptedException retry) {timedOut = false;}}}
由此可见 getTask里面是有超时标志的timed的,我们在第一篇不会吧,就是你把线程池讲的这么清楚的?里面说的线程池原理里面讲到,若非核心线程空闲keepAliveTime分钟则销毁,就是在这里,keepAliveTime时间内未获取到任务,即为线程空闲状态,就退出了runWorker中的while循环,进行销毁线程的操作。
核心线程一定不会销毁吗?
我们注意到,这里面有一个allowCoreThreadTimeOut变量,如果他要是为true的话,那么核心线程也是可以销毁的
threadPoolExecutor.allowCoreThreadTimeOut(true);
真的有核心线程与非核心线程之分吗?
其实是没有区别的,他们都是一样的线程,线程池源码中并没有核心线程这个标记,只是有一个核心线程数量,在这个数量之前创建先线程和在这个数量之后创建线程,默认在这个数量之后创建的线程会在keepAliveTime空闲时间内销毁,我们为了方便记忆,而将其称为非核心线程
7、总结
大体流程如下图所示
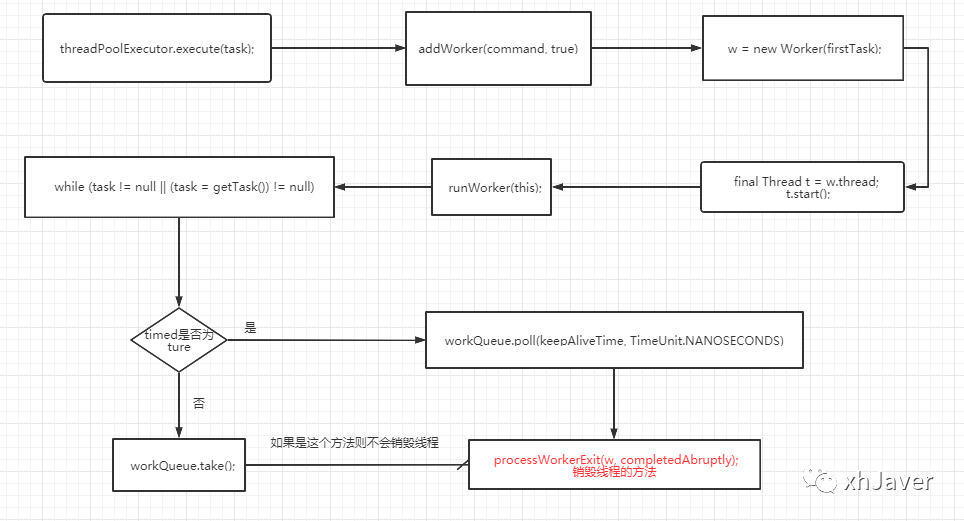
我们向线程池提交任务后,线程池会将我们的任务封装成一个worker,这个worker里面有要执行的线程t和要执行的任务,这个线程t的主要任务就是t.start,运行runWorker方法,在runWorker方法中,会一直while循环获取提交的任务。若没有提交的任务则会看队列里有没有任务,获取队列任务时就会判断超时标志是否为true,如果为true的话,则在超时时间内未获取到任务则返回null,然后销毁当前线程,否则一直等待到获取到任务为止,不销毁线程,这样就做到了线程复用。
最后,给大家准备了一套算法学习教程,从小白到大神,都是这样走过来的,建议学习一下,拿走不谢!
下载方式
1. 首先扫描下方二维码
2. 后台回复「A110」即可获取
