
伴鱼事件分析平台设计
背景
在伴鱼,服务器每天收集的用户行为日志达到上亿条,我们希望能够充分利用这些日志,了解用户行为模式,回答以下问题:
最近三个月,来自哪个渠道的用户注册量最高?
最近一周,北京地区的,发生过绘本浏览行为的用户,按照年龄段分布的情况如何?
最近一周,注册过伴鱼绘本的用户,7 日留存率如何?有什么变化趋势?
最近一周,用户下单的转化路径上,各环节的转化率如何?
为了回答这些问题,事件分析平台应运而生。本文将首先介绍平台的功能,随后讨论平台在架构上的一些思考。
功能
总的来说,为了回答各种商业分析问题,事件分析平台支持基于事件的指标统计、属性分组、条件筛选等功能的查询。其中,事件指用户行为,例如登录、浏览伴鱼绘本、购买付费绘本等。更具体一些,事件分析平台支持三类分析:「事件分析」,「漏斗分析」,和「留存分析」。
事件分析
事件分析是指,用户指定一系列条件,查询目的指标,用于回答一个具体的分析问题。这些条件包括:
事件类型:指用户行为,采集自埋点数据;例如登录伴鱼绘本,购买付费绘本
指标:指标分为两类,基础指标和自定义指标基础指标:总次数(pv),总用户数(uv),人均次数(pv/uv)自定义指标:事件属性 + 计算类型,例如 「用户下单金额」的「总和/均值/最大值」
过滤条件:用于筛选查询所关心的用户群体
维度分组:基于分组,可以进行分组之间的对比
时间范围:指定事件发生的时间范围
让我们举个具体的例子。我们希望回答「最近一周,在北京地区,不同年龄段的用户在下单一对一课程时,下单金额的平均数对比」这个问题。这个问题可以很直观地拆解为下图所示的事件分析,其中:
事件类型 = 下单一对一课程
指标 = 下单金额的平均数
过滤条件 = 北京地区
维度分组 = 按照年龄段分组
时间范围 = 最近一周

图注:事件分析创建流程
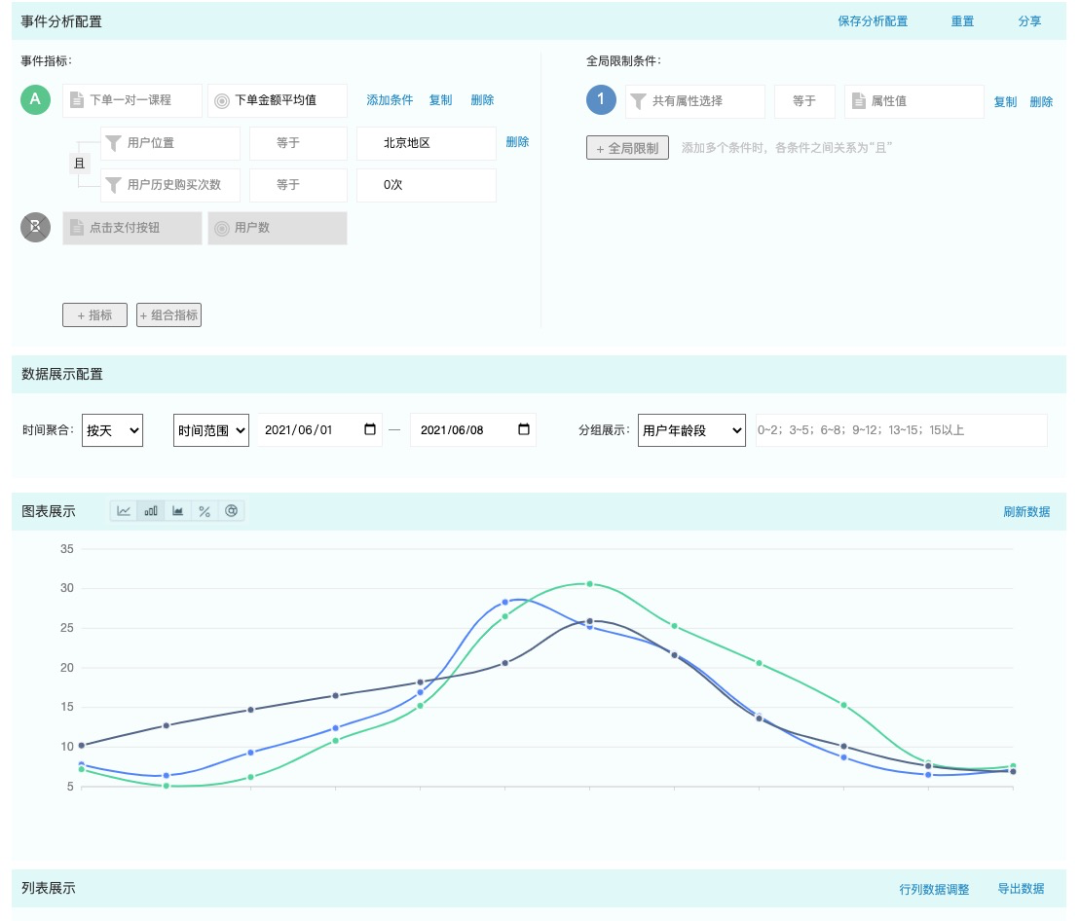
图注:事件分析界面
漏斗分析
漏斗分析用于分析多步骤过程中,每一步的转化与流失情况。
例如,伴鱼绘本用户的完整购买流程可能包含以下步骤:登录 app -> 浏览绘本 -> 购买付费绘本。我们可以将这个流程设置为一个漏斗,分析整体以及每一步转化情况。
此外,漏斗分析还需要定义「窗口期」,整个流程必须发生在窗口期内,才算一次成功转化。和事件分析类似,漏斗分析也支持选择维度分组和时间范围。

图注:漏斗分析创建流程
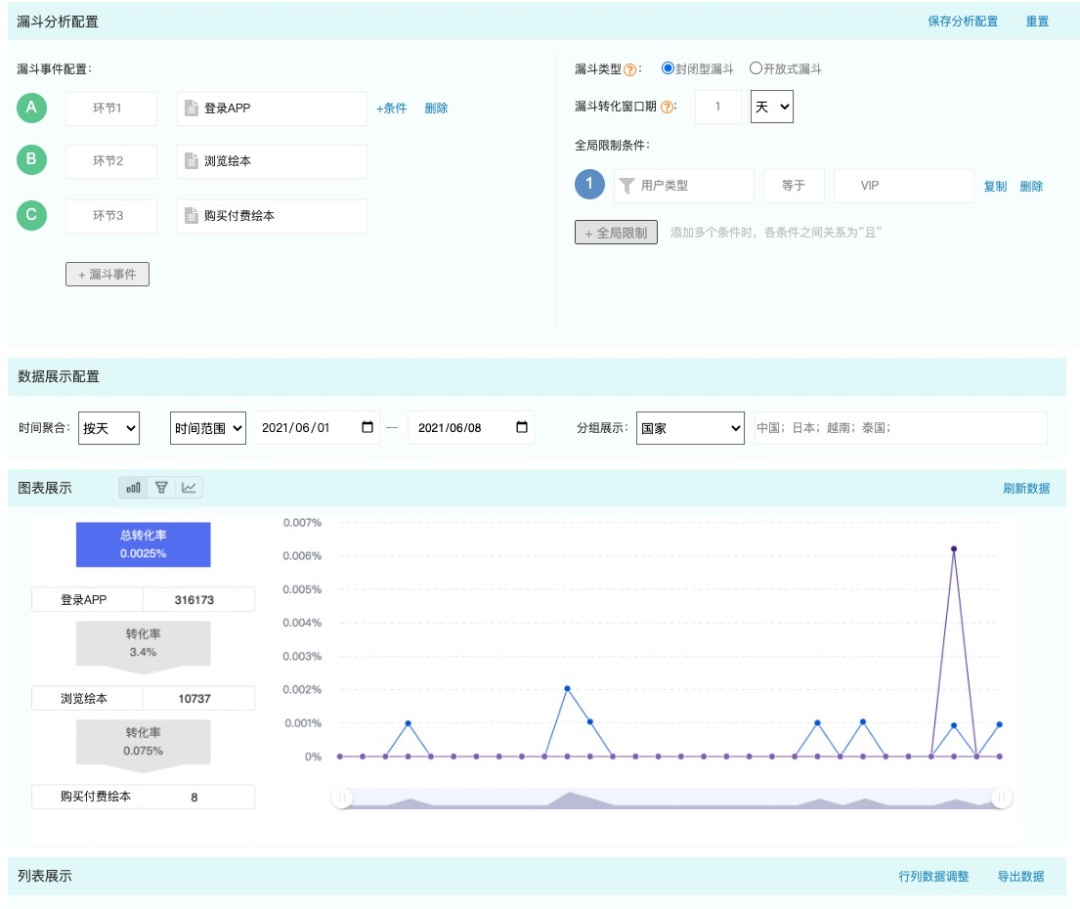
图注:漏斗分析界面
留存分析
在留存分析中,用户定义初始事件和后续事件,并计算在发生初始事件后的第 N 天,发生后续事件的比率。这个比率能很好地衡量伴鱼用户的粘性高低。
在下图的例子中,我们希望了解伴鱼绘本 app 是否足够吸引用户,因此我们设置初始事件为登录 app,后续事件为浏览绘本,留存周期为 7 天,进行留存分析。

图注:留存分析创建流程
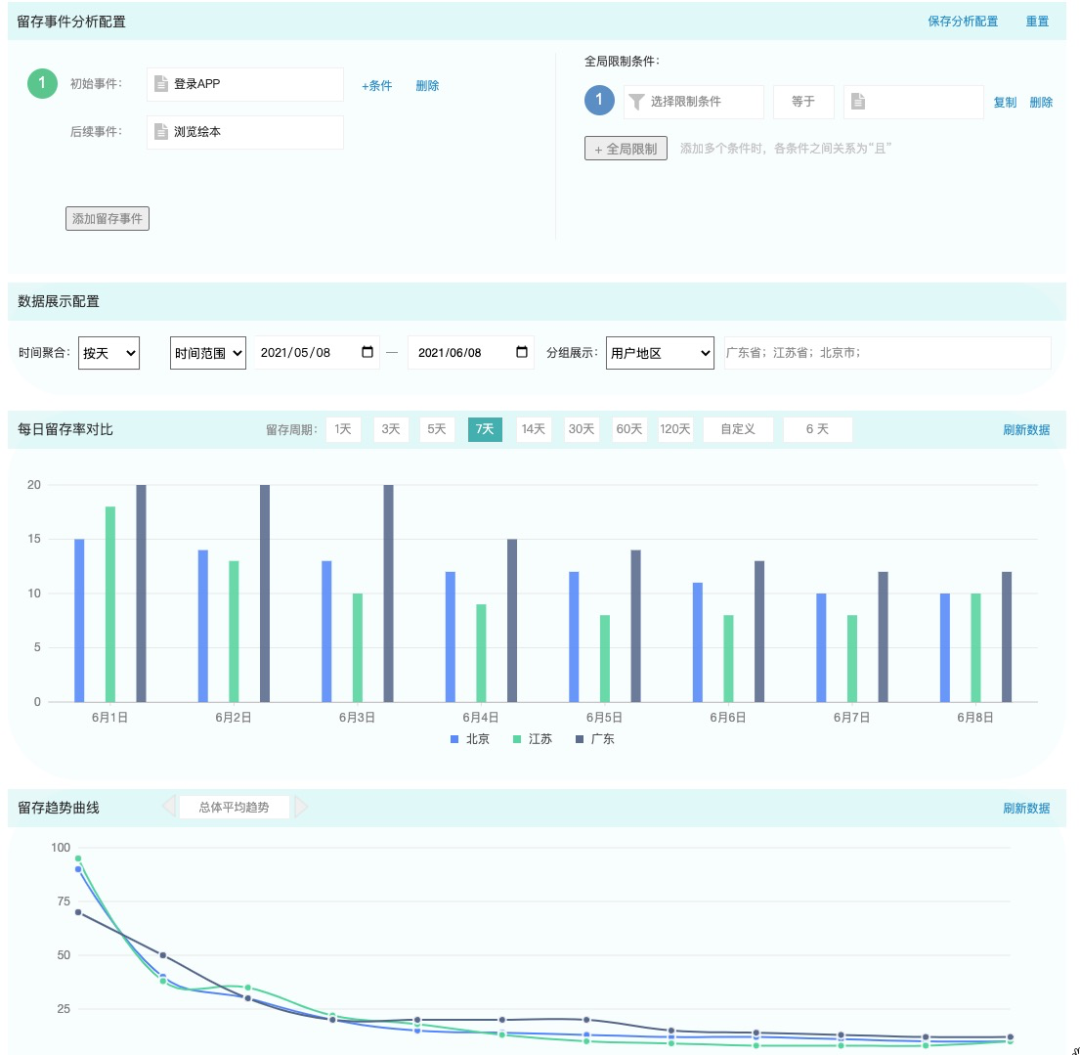
图注:留存分析界面
架构
在架构上,事件分析平台分为两个模块,如下图所示:
数据写入:埋点日志从客户端或者服务端被上报后,经过 Kafka 消息队列,由 Flink 完成 ETL,然后写入 ClickHouse。
分析查询:用户通过前端页面,进行事件、条件、维度的勾选,后端将它们拼接为 SQL 语句,从 ClickHouse 中查询数据,展示给前端页面。
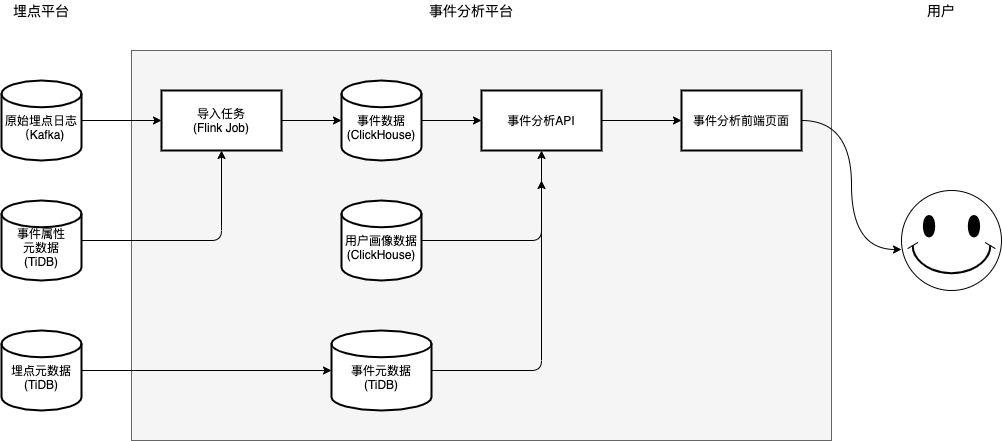
图注:总架构图
不难看出,ClickHouse 是构成事件分析平台的核心组件。我们为了确保平台的性能,围绕 ClickHouse 的使用进行了细致的调研,回答了以下三个问题:
如何使用 ClickHouse 存储事件数据?
如何高效写入 ClickHouse?
如何高效查询 ClickHouse?
如何使用 ClickHouse 存储事件数据?
事件分析平台的数据来源有两大类:来源于埋点日志的用户行为数据,和来源于「用户画像平台」的用户属性数据。本文只介绍埋点日志数据的存储,对「用户画像平台」感兴趣的同学,可以期待一下我们后续的技术文章。
在进行埋点日志的存储选型前,我们首先明确了几个核心需求:
支持海量数据的存储。当前,伴鱼每天产生的埋点日志在亿级别。
支持实时聚合查询。由于产品和运营同学会使用事件分析平台来探索多种用户行为模式,分析引擎必须能灵活且高效地完成各种聚合。
ClickHouse 在海量数据存储场景被广泛使用,高效支持各类聚合查询,配套有成熟和活跃的社区,促使我们最终选择 ClickHouse 作为存储引擎。
根据我们对真实埋点数据的测试,亿级数据的简单查询,例如 PV 和 UV,都能在 1 秒内返回结果;对于留存分析、漏斗分析这类的复杂查询,可以在 10 秒内返回结果。
「存在哪」的问题解决后,接下来回答「怎么存」的问题。ClickHouse 的列式存储结构非常适合存储大宽表,以支持高效查询。但是,在事件分析平台这个场景下,我们还需要支持「自定义属性」的存储,这时「大宽表」的存储方式就不尽理想。
所谓「自定义属性」,即埋点日志中一些事件所独有的属性,例如:「下单一对一课程」这一事件在上报时,会带上「订单金额」这个很多其它事件所没有的属性。如果为了支持「下单一对一课程」这个事件的存储,就需要改变 ClickHouse 的表结构,新增一列,这将使得表结构的维护成本极高,因为每个新事件都可能附带多个「自定义属性」。
为了解决这个问题,我们将频繁变动的自定义属性统一存储在一个 Map 中,将基本不变的公共属性存为列,使之兼具大宽表方案的高效性,和 Map 方案的灵活性。
如何高效写入 ClickHouse?
在设计 ClickHouse 的部署方案时,我们采用了业界常用的读写分离模式:写本地表,读分布式表。在写入侧,分为 3 个分片,每个分片都有双重备份。
由于事件分析的绝大多数查询,都是以用户为单位,为了提高查询效率,我们在写入时,将数据按照 user_id 均匀分片,写入到不同的本地表中。如下图所示:
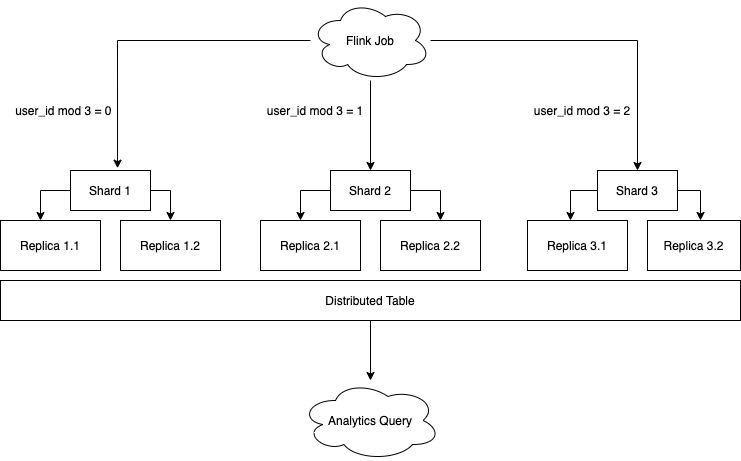
图注:将埋点数据写入到 ClickHouse
之所以不写分布式表,是因为我们使用大量数据对分布式表进行写入测试时,遇到过几个问题:
Too many parts error:分布式表所在节点接收到数据后,需要按照 sharding_key 将数据拆分为多个 parts,再转发到其它节点,导致短期内 parts 过多,并且增加了 merge 的压力;
写放大:分布式表所在节点,如果在短时间内被写入大量数据,会产生大量临时数据,导致写放大。
如何高效查询 ClickHouse?
我们可以使用 ClickHouse 的内置函数,轻松实现事件分析平台所需要提供的事件分析、漏斗分析和留存分析三个功能。
事件分析可以用最朴素的 SQL 语句实现。例如,最近一周,北京地区的,发生过绘本浏览行为的用户,按照年龄段的分布,可以表述为:
SELECT count(1) as cnt, toDate(toStartOfDay(toDateTime(event_ms))) as date, ageFROM event_analyticsWHERE event = "view_picture_book_home_page" AND city = "beijing" AND event_ms >= 1613923200000 AND event_ms <= 1614528000000GROUP BY (date, age);
留存分析使用 ClickHouse 提供的 retention 函数。例如,注册伴鱼绘本后,计算浏览绘本的次日留存、7 日留存可以表述为:
SELECT sum(ret[1]) AS original, sum(ret[2]) AS next_day_ret, sum(ret[3]) AS seven_day_retFROM(SELECT user_id, retention( event = "register_picture_book" AND toDate(event_ms) = toDate('2021-03-01'), event = "view_picture_book" AND toDate(event_ms) = toDate('2021-03-02'), event = "view_picture_book" AND toDate(event_ms) = toDate('2021-03-08') ) as retFROM event_analyticsWHERE event_ms >= 1614528000000 AND event_ms <= 1615132800000GROUP BY user_id);
漏斗分析使用 ClickHouse 提供的 windowFunnel 函数。例如,在 浏览绘本 -> 购买绘本,窗口期为 2 天的这个转化路径上,转化率的计算可以被表达为:
SELECTarray( sumIf(count, level >= 1), sumIf(count, level >= 2) ) AS funnel_uv,FROM (SELECTlevel,count() AS countFROM (SELECT uid, windowFunnel(172800000)( event_ms, event = "view_picture_book" AND event_ms >= 1613923200000 AND event_ms <= 1614009600000, event = "buy_picture_book") AS levelFROM event_analyticsWHERE event_ms >= 1613923200000 AND event_ms <= 1614182400000GROUP BY uid )GROUP BY level)