
伴鱼大数据权限系统的设计与实现

- 前言 -
伴鱼早期,整个大数据仓库下的数据基本处于裸奔状态,没有做任何的权限校验与审计,用户可以对数据为所欲为,这个阶段主要考虑效率优先。随着业务的发展,数据安全的重要性愈发突显,大数据权限系统因运而生,本文将向大家介绍伴鱼大数据权限系统的设计与实现。
- 背景 -
数据访问方式
在伴鱼,离线数仓下的数据主要有以下几种访问方式:
Hive:有两种方式,一是 Hive CLI,一个逐渐被淘汰的工具,但目前仍然在各种脚本中被使用。Hive CLI 是一个胖客户端,官方推荐使用 Beeline CLI(HiveServer2 JDBC Client)替代它,并建议在生产环境中使用其远程模式(轻客户端模式)。另一个是 HiveServer2 JDBC API。
Presto:Presto JDBC API。
Hadoop:HDFS CLI。
Flink:HDFS Client API。
数据访问渠道
上述几类访问方式对应的访问渠道主要有以下几种:
集群节点上安装的各类客户端工具。
Metabase(BI 平台):Metabase 可以配置各种「数据源」,数据报表开发时必须选择一个对应的「数据源」。目前我们主要使用两类数据源:Hive 数据源(使用 HiveServer2 JDBC API 的方式)以及 Presto 数据源(使用 Presto JDBC API 的方式)。而对于开发之后的报表,Metabase 内部实现了一套自己的授权方式。
离线开发平台(DolphinScheduler,简称 DS):DS 同样抽象了数据源的概念,目前主要使用的 Hive 数据源(使用 HiveServer2 JDBC API 的方式)。此外,DS 也支持 Shell 脚本类型的工作流节点,使用此类方式脚本中基本是采用 CLI 的访问方式,本质上要求 DS worker 节点提前安装好各类客户端工具。
实时开发平台:与具体的实时任务相关,主要体现在与 Hive 集成的任务。
设计目标
管控与效率两者之间是天然对立的,我们需要做的是在这之间寻求一种平衡。就目前的形式来看,我们期望达到以下目标:
尽量收紧非数仓团队的各类权限:此为核心目标。非数仓团队访问数据主要通过是通过 Metabase,目前针对不同的数据库(如:Hive)都基本是使用同一个数据源,该数据源配置的拥有最高权限,导致各方都可以查看任何数据。
逐渐规范化数仓团队数据访问方式:逐步替换 Hive CLI 方式至 Beeline CLI。
统一整合权限系统与各相关系统的权限操作:在大数据权限系统平台即可完成各类授权的操作。
调研
权限管控主要体现在两个方面:用户认证(authentication)与权限认证(authorization)。
用户认证
大数据各组件支持不同的用户认证方式,这里主要看下我们所关注的组件支持的认证方式。
Hive
HiveServer2:用户认证支持 Kerberos、SASL、NOSASL、LDAP、PAM 和 Custom 的方式。
Presto
Presto 用户认证支持 Kerberos、LDAP 和 Password File 的方式。
Hadoop
Hadoop 各组件仅支持 Kerberos 的用户认证方式。
可见统一基于 Kerberos 的方式,可以实现全链路的用户认证。Kerberos 是一个集中式的用户认证管理框架,具备较完备的用户认证能力,但整体运维成本较高,这与我们的期望(尽可能少的引入新的组件)相悖,因此决定采用 LDAP 的方式(目前已具备实操、运维的经验)。也就意味着我们只是在 Hadoop 组件之上进行用户认证,Hadoop 的各组件依旧保持没有任何的用户认证,用户可以在机器节点上伪装任意用户对集群中的数据进行操控,而这类方式对于非开发人员具有一定的门槛,因此也符合我们的设计目标。
权限认证
Hive
HiveServer2:支持基于 SQL 标准的授权,可用于细粒度(如:列)的访问控制。权限认证采用了插件化的实现方式,目前开源实现方案有 Apache Ranger 和 Apache Sentry,两者基本类似,我们选择了 Apache Ranger。
Presto、Hadoop
Presto 和 Hadoop 各组件权限认证同样采用了插件化的实现方式,可以采用 Apache Ranger 方案实现。
系统设计
当前数据链路各组件的关系以及权限控制如下图所示:
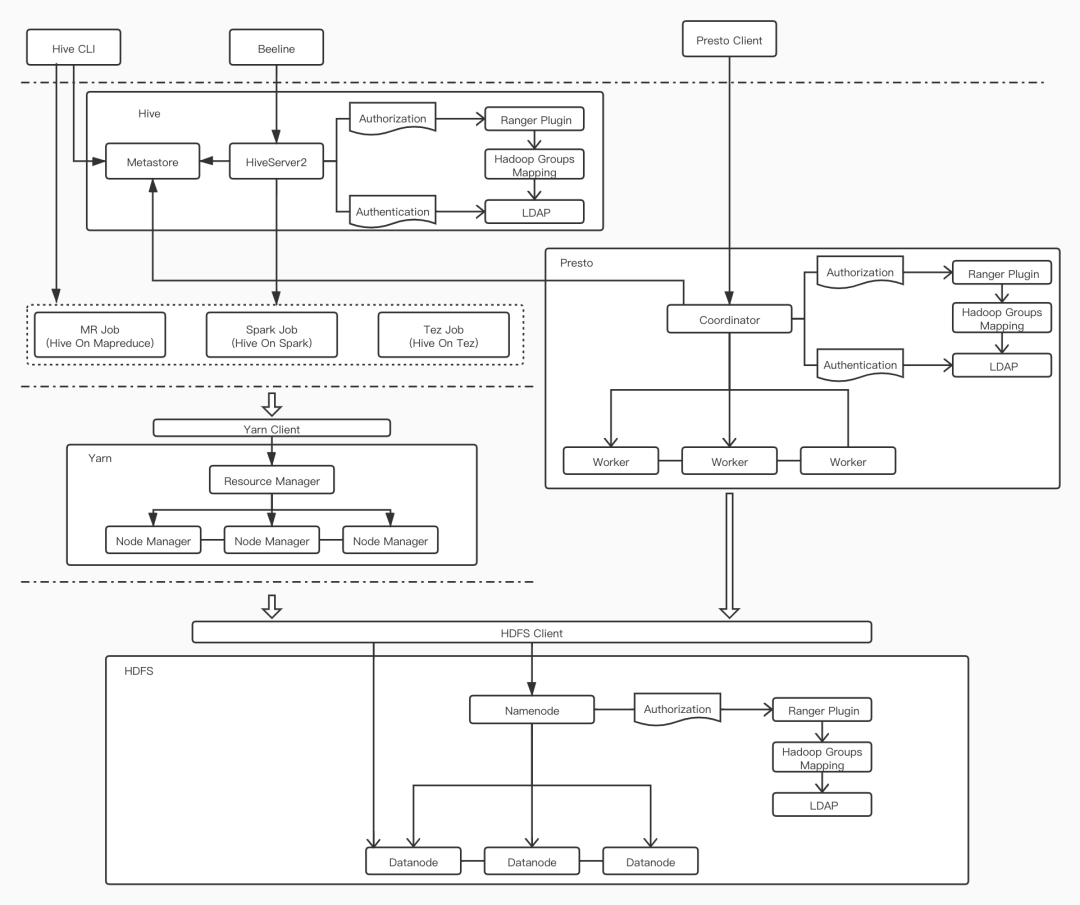
我们在 Hive 的 HiveServer2 和 Presto 的 Coordinator 组件上进行了用户认证和授权,而在 HDFS 的 NameNode 组件只进行了授权。注意到,在授权流程中 Ranger Plugin 依赖了 Hadoop Group Mapping,而它又依赖了 LDAP,关于这些关系将在下文中阐述。
用户认证
用户认证即对请求中的用户名、密码进行校验,逻辑相对简单。只需对相应的组件进行简单的配置即可,如下是 HiveServer2 组件配置示例:
hive.server2.authentication LDAP hive.server2.authentication.ldap.baseDN ou=People,dc=ipalfish,dc=com hive.server2.authentication.ldap.url ldap://*****:389 hive.server2.authentication.ldap.userDNPattern cn=%s,ou=bigdata_user,ou=People,dc=ipalfish,dc=com
- 权限认证 -
用户和用户组
用户和用户组是权限认证的基本对象,引入用户组的目的是为了提升效率。设想这么一个场景:一批用户需要同一批库表的权限,最直接的想法是每一个用户都申请一遍权限,从算法的角度看,时间复杂度是 O(N) 的。如果可以抽象出用户组的概念,这批用户加入同一个用户组,同时保证组内的成员可以继承组的所有权限,那么就可以只为用户组申请一次权限即可,时间复杂度降到了 O(1)。
Ranger 中 User 对应用户,Group 对应用户组,一个用户可以加入多个组,它实现了 User 继承 Group 权限的特性。权限认证时判定一项策略是否通过,会判定用户的 User 或用户所属的任意一个 Group 是否在策略中配置,如有则通过。这里引申出一个问题,用户所属的 Groups 如何获取?
查阅代码,不难发现使用 Hadoop 的 Hadoop Groups Mapping 机制。下图为 ranger presto plugin 部分代码片段:
private RangerPrestoAccessRequest createAccessRequest(RangerPrestoResource resource, SystemSecurityContext context, PrestoAccessType accessType) {String userName = null;Set<String> userGroups = null;if (useUgi) { UserGroupInformation ugi = UserGroupInformation.createRemoteUser(context.getIdentity().getUser()); userName = ugi.getShortUserName();String[] groups = ugi != null ? ugi.getGroupNames() : null;if (groups != null && groups.length > 0) { userGroups = new HashSet<>(Arrays.asList(groups)); } } else { userName = context.getIdentity().getUser(); userGroups = context.getIdentity().getGroups(); } RangerPrestoAccessRequest request = new RangerPrestoAccessRequest( resource, userName, userGroups, accessType );return request; }可以看出,使用了 org.apache.hadoop.security 包下的 UserGroupInformation 信息,这即是 Hadoop Groups Mapping 相关的实现代码。Hadoop Groups Mapping 支持 LDAP 的方式获取 User 和 Group 信息,我们也采用了这种方式,因此上文中提到的用户认证流程和授权流程最终都将依赖 LDAP。
权限等级
一个数据表的不同的列具有不同的信息价值和数据敏感度,因此需要为每一列都划分一个权限等级,用户申请权限是按照列的粒度进行申请。不同的权限等级对应着不同的权限审批流程,目前我们划分了三种权限等级:P0、P1 和 P2,级别由高到低,P0 级别的列信息最敏感,因此拥有最长的审批流程。
权限策略
Ranger 的策略类型主要有两种:Access 和 Mask。
Access:正向策略。如一个数据表有三个字段,我们可以为每一字段创建一条 Access 策略,将申请了权限的用户或组配置进策略即可。乍一看,这种策略即可满足我们的需求,不过考虑这么一个场景:一个拥有 50 个字段的数据表,某一个用户申请其中 40 个字段的权限(另外一些字段的权限等级可能属于 P0 级别)。当想要查看表数据时,一般的写法是「SELECT * FROM Table」,这种形式的语句在权限认证环节要求具备全部字段的权限,否则将会返回权限不足的错误,而我们期望是对于未授权的字段可以使用特殊的脱敏标识符打标,这就需要借助到 Ranger 提供的另一种 Mask 策略。
Mask:补充策略。该策略用于保护敏感数据,对数据进行脱敏。Mask 策略是建立在 Access 策略之上的,即使用 Mask 策略优先得具备列的 Access 策略。因此当用户申请权限时,我们可以为用户授予数据表全部字段的 Access 策略(只需一个策略,策略中的 column 配置成通配符 * )的权限,同时为每一个字段生成 Mask 策略,对于没有申请权限的字段,将 User 或 Group 配置进策略即可。
注:所有在 Ranger Admin 配置的策略将由 Ranger Plugin 中的线程定期 Pull 至组件,并在运行时执行权限认证。
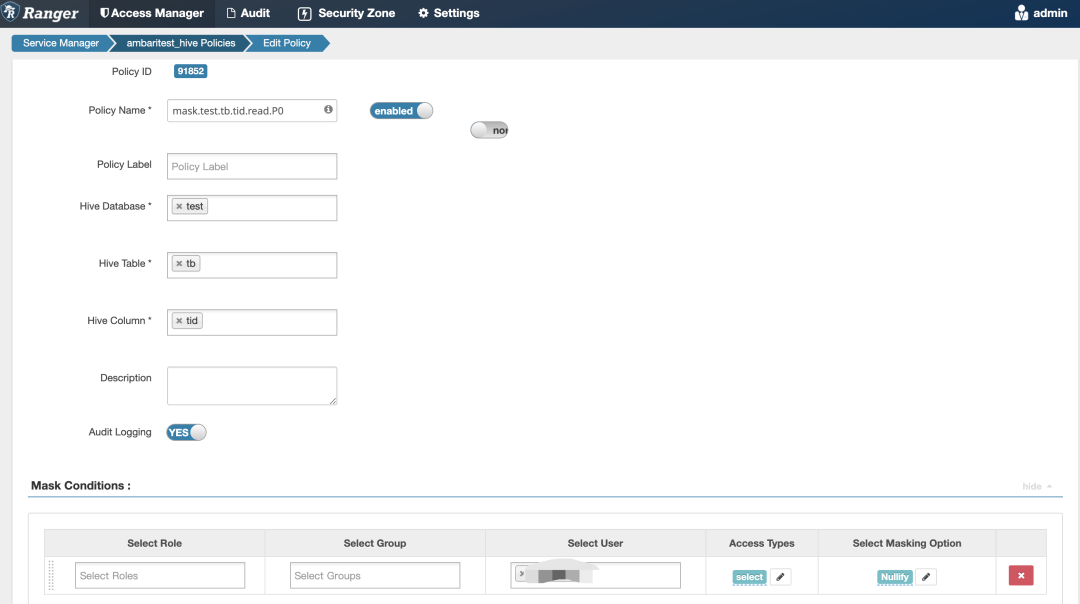
下图展示了在权限系统申请库 test 表 tb 下字段名为 tid 的权限时对应的 Ranger 策略示例:
权限申请工单
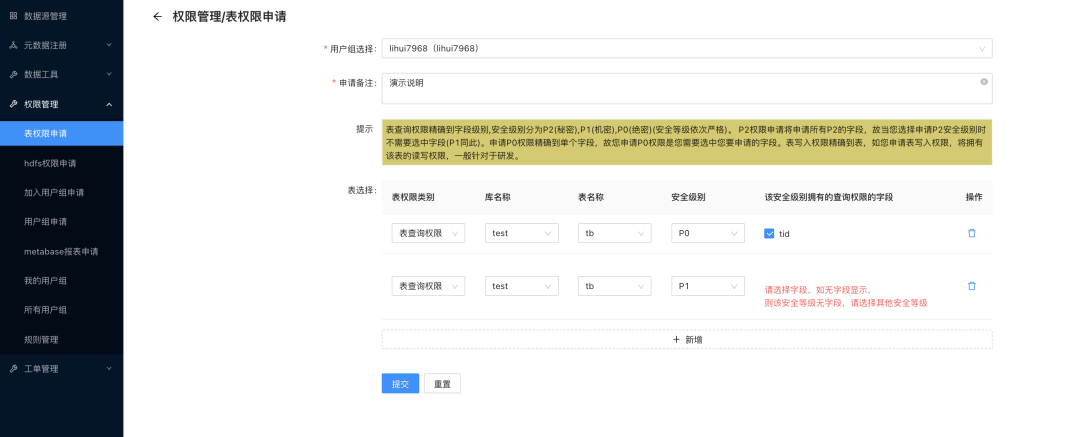
Access Policy

Mask Policy
- 策略成本 -
以上从原理层面介绍了基于 Ranger 进行权限认证的几个重要概念,通过修改相关组件的配置,即可使权限认证生效。本节将从平台的角度看一下如何生成 Ranger 中的策略配置。
首先需要考虑权限策略初始化的问题。一张 Hive 表的权限策略必然是在表创建之后生成的,我们期望表创建时创建者能够直接指定各列对应的权限等级,同时创建者作为表的 Owner 直接拥有表所有列的全部权限。主要可以从两个方向考虑:
同步创建
同步创建方案通过将建表逻辑和策略初始化逻辑包装成一段程序,在建表成功后执行策略初始化。不幸的是,目前我们的建表渠道有多种方式,主要包括:
数据建模平台:数据建模平台约束了建表规范,同时收集了表的附加元信息,如表字段的权限等级,这些元信息将通过 API 传递至 Hive。可见,数据建模平台本质上是对建表操作的封装和约束,可以实现同步初始化策略的目的。
CLI:指代 Beeline。由于并未完全约束用户在建模平台建表,开发人员可以直接在自己脚本中通过 CLI 直接建表,这种情况下表的元信息是缺失的。
我们很难将所有渠道统一起来,即便最终建表行为可以收敛至建模平台,但从系统边界的角度考虑,建模和权限分属两个系统,权限策略的创建应当收敛至权限系统。
异步创建
异步化创建的方式需要借助消息队列,需要将所有的建表事件投递至一个 Topic,权限系统后台监听此 Topic 消息,从而触发策略的初始化。那么如何捕捉全部的建表事件并投递至一个消息队列?这就需要借助我们提供的「元数据中心」平台,它统一管理了全部数据的元信息。我们的「元数据中心」平台是在 Apache Atlas 基础上搭建的。Apache Atlas 通过其提供的各类组件的 Atlas Hook 以此来捕捉元信息。以 Atlas Hive Hook 为例,我们提交给 Hive 的建表信息包括附加的元信息都可以在此 Hook 中被捕捉,这些信息紧接着会被发送至 Atlas Server 进行存储,与此同时 Atlas Server 可以通过配置一个对外的 Topic 统一将这些消息发送至外部的监听系统。通过这种机制,我们就达到异步初始化权限策略的目的。
值得一提的是,字段权限等级的修改有且仅能在元数据中心进行,等级的修改将影响到对应的权限策略。对于这一事件,将通过同样的方式,被权限系统后台监听,并触发相应的动作。
整个过程如下图所示:
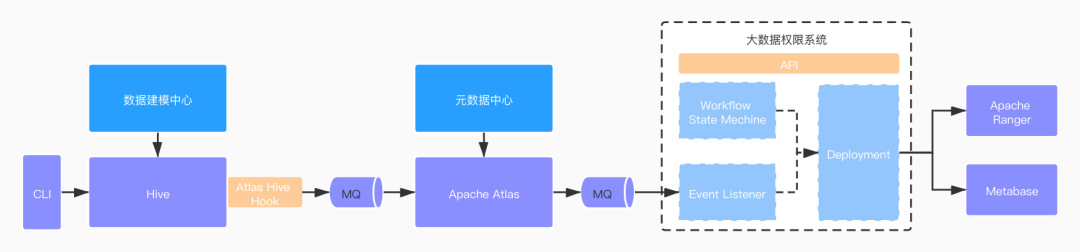
大数据权限系统主要划分为三部分:
Workflow State Machine:工作流状态机,负责各级工单状态流转。
EventListener:负责监听元信息变更事件。
Deployment:负责将策略部署至 Ranger。同时,由于涉及到权限整合还有和 Metabase 的交互,将在下文阐述。
权限整合
BI 系统可以说得上是一家公司使用最频繁的一款数据产品,数据开发工程师、分析师在上面开发报表,产品、运营等业务方在上面查看报表。我们的 BI 系统是基于开源的 Metabase 搭建的,前文提到,Metabase 自身具备一套权限管控的机制,但实践下来十分难用且由于没有审批工单机制,往往需要人工线下确认,增加了沟通的成本。同时审批工作都由管理员完成,十分耗费个人的人力成本。基于此,我们决定在权限系统中整合 Metabase 相关的权限操作。
报表开发权限
任意平台用户都具备报表的开发权限,但开发一个报表需要选择一个对应的「数据源」,因此开发权限体现在对于「数据源」的权限控制上。我们在权限系统提供了「同步账户」的操作,用户可以执行此操作,操作中的一个步骤就是创建数据源,使用的是其对应的用户名和密码,用户开发报表时选择自己的数据源即可,会为该对象的 Metabase 账户授予此数据源的权限。报表查看权限
Metabase 报表权限是按照「分组」进行授权的,平台用户需加入某一个「分组」,然后为此「分组」授予报表权限,用户方可查看报表。因此「同步账户」时还会为用户或用户组创建与之对应的「分组」,同时将其下所有成员的 Metabase 账户加入此「分组」。报表的权限申请提供了单独的申请入口,用户填入报表地址即可,工单进入不同的审批流程,审批完成则将自动为其对应的「分组」授予权限。
Metabase 报表权限申请工单示例:
- 总结 -
本文阐述伴鱼大数据权限系统的核心设计要点,目前 Presto、Hive、HDFS、Metabase的权限都得到了收敛,工单化的申请流程极大的降低了授权申请的成本,自动化程度比较高,效果比较理想。
作者:李辉
来源:tech.ipalfish.com/blog/2021/10/07/data_access_control/
