
测试面试题集-MySQL数据库灵魂拷问

25
2020-09
今天距2021年97天
这是ITester软件测试小栈第162次推文

点击上方蓝字“ITester软件测试小栈“关注我,每周一、三、五早上 08:30准时推送,每月不定期赠送技术书籍。
微信公众号后台回复“资源”、“测试工具包”领取测试资源,回复“微信群”一起进群打怪。
本文3905字,阅读约需10分钟
事务是数据库操作的最小工作单元,是作为单个逻辑工作单元执行的一系列操作,这些操作作为一个整体一起向系统提交,要么都执行、要么都不执行,是一组不可再分割的操作集合。
通俗理解就是做一件事情的过程,事务封装了一条dml、或者多条dml语句。这个过程有两种结果:要么全部成功、要么全部失败。
A=Atomicity ,原子性:事务是数据库最小逻辑单位。事务中包含的各项操作在一次执行过程中,只允许出现两种状态之一,要么全部执行成功 ,要么全部执行失败。任何一项操作都会导致整个事务的失败,同时其它已经被执行的操作都将被撤销并回滚,只有所有的操作全部成功,整个事务才算是成功完成。C=Consistency ,一致性:系统总是从一个一致性的状态转移到另一个一致性的状态。例如从 A 账户转账到 B 账户,不能因为 A 账户扣了钱,而 B 账户没有加钱,无论 A 和 B 怎么转账,系统中总额是固定的。如果数据库系统运行中发生故障,有些事务尚未完成就被迫中断,这些未完成事务对数据库所做的修改有一部分已写入物理数据库,这时数据库就处于一种不正确的状态,或者说是不一致的状态。
I=Isolation ,隔离性: 通常来说一个事务在完全提交之前,对其他事务是不可见的。也就是说,不同的事务并发操作相同的数据时,每个事务都有各自完整的数据空间。一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务是不能互相干扰的。
D=Durability ,持久性:事务一旦提交,将永久存在,接下来的其它操作或故障不应该对其执行结果有任何影响。即使服务器系统崩溃或服务器宕机等故障。只要数据库重新启动,那么一定能够将其恢复到事务成功结束后的状态。
MySQL 的隔离等级对加锁有影响,所以在分析具体加锁场景时,首先要确定当前的隔离等级,分为以下几个等级:
读未提交(Read Uncommitted ,简称 RU):可以读到未提交的读,基本上不会使用该隔离等级,所以暂时忽略。
读已提交(Read Committed ,简称 RC):存在幻读问题,对当前读获取的数据加记录锁。
可重复读(Repeatable Read ,简称 RR):不存在幻读问题,对当前读获取的数据加记录锁,同时对涉及的范围加间隙锁,防止新的数据插入,导致幻读。
序列化(Serializable):从 MVCC 并发控制退化到基于锁的并发控制,不存在快照读,都是当前读,并发效率急剧下降,不建议使用。
隔离级别与对应问题矩阵如下所示:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 | 是 | 是 | 是 |
| 不可重复读 | 否 | 是 | 是 |
| 可重复读 | 否 | 否 | 是(MySQL否) |
| 串行化 | 否 | 否 | 否 |
注,常见数据库的默认级别:
MySQL数据库的默认隔离级别是 Repeatable read (可重复读)级别。Oracle数据库中,只支持 Seralizable(顺序读) 和 Read committed(读已提交)级别,默认的是 Read committed 级别。SQL Server数据库中,默认的是 Read committed(读已提交) 级别。
事务的隔离级别有4种:读未提交、读已提交、可重复读、串行化,关于在MySQL中InnoDB引擎是如何解决幻读,一张图甚过千言万语:
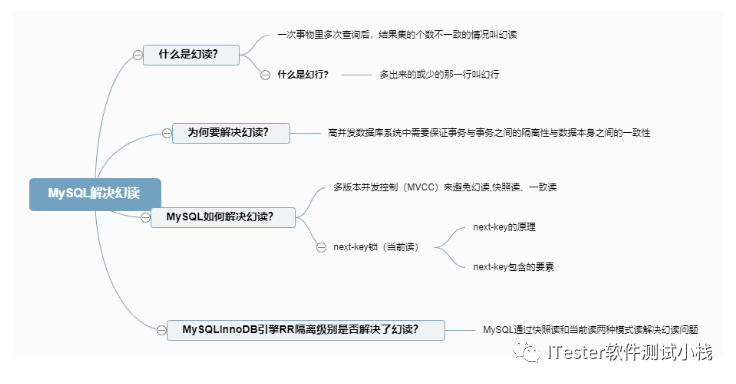
综上,高并发数据库系统中,为保证事务与事务之间隔离性和数据一致性,MySQL InnoDB引擎默认是RR的隔离级别,在MySQL 中通过MVCC快照读和next-key(当前读)两种模式解决幻读问题。
2个事务交叉:同一个事务中出现delete,insert操作;3个insert事务,一个回滚:三个事务的 insert 语句都是insert ignore into t1(a, b)values("1", "1");多个事务,间隙锁造成死锁:同一个事务中多个update操作导致锁升级(行锁升级为表锁),并发操作时会导致死锁;
解决方式:事务拆分,同一个事物中不要出现锁升级,如果业务需求确实导致有表锁的出现,直接使用悲观锁。
drop:drop是DDL,会隐式提交,所以,不能回滚,不会触发触发器;drop语句删除表结构及所有数据,并将表所占用的空间全部释放,底层系统文件会变小;drop语句将删除表的结构所依赖的约束,触发器,索引,依赖于该表的存储过程/函数将保留,但是变为invalid状态。
truncate:truncate是DDL,会隐式提交,所以,不能回滚,不会触发触发器;truncate会删除表空间,底层系统文件会变小。并且将重新设置高水线和所有的索引,缺省情况下将空间释放到minextents个extent,除非使用reuse storage。不会记录日志,所以执行速度很快,但不能通过rollback撤消操作,如果一不小心把一个表truncate掉,也是可以恢复的,只是不能通过rollback来恢复;对于外键(foreignkey )约束引用的表,不能使用 truncate table,而应使用不带 where 子句的 delete 语句;truncatetable不能用于参与了索引视图的表。
delete:delete是DML,执行delete操作时,每次从表中删除一行,并且同时将该行的的删除操作记录在redo和undo表空间中以便进行回滚(rollback)和重做操作,但要注意表空间要足够大,需要手动提交(commit)操作才能生效,可以通过rollback撤消操作;delete可根据条件删除表中满足条件的数据,如果不指定where子句,那么删除表中所有记录,只删表数据,删除操作后,底层系统文件不会变小;delete语句不影响表所占用的extent,高水线(high watermark)保持原位置不变。
总结:
在速度上,一般来说,drop> truncate > delete。
在使用drop和truncate时一定要注意,虽然可以恢复,但为了减少麻烦,还是要慎重。
如果想删除部分数据用delete,注意带上where子句,回滚段要足够大;如果想删除表,用drop; 如果想保留表而将所有数据删除,如果和事务无关,用truncate即可;如果和事务有关,或者想触发trigger,还是用delete; 如果是整理表内部的碎片,可以用truncate跟上reuse stroage,再重新导入/插入数据。
索引大大减小了
服务器需要扫描的数据量;索引可以帮助服务器避免排序和临时表;
索引可以将随机IO变成
顺序IO;
类型转换:当存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引;
索引列加函数:加了函数无法使用上索引;
字符校对规则不对;
没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷);
没有创建计算列导致查询不优化;
查询出的数据量过大(可以采用多次查询或其他方法降低数据量);
查询语句需要优化;

个人微信:Cc2015123
添加请注明来意 :)
