
讲讲大数定理

前面我们讲过中心极限定理,没看过的同学可以去看看:讲讲中心极限定理。这一节来讲讲大数定理,大数定理和中心极限定理是比较接近的两个概念,这两个定理经常一起出现。我们来具体看下大数定理的内容:
大数定律是指:随着样本容量n不断增加,样本平均数将越来越接近于总体平均数(期望 μ),我们把总体的平均数称为期望,关于均值与期望的差别,我们在前面的文章中写过:均值与期望到底是不是一回事?
基于大数定理的存在,所以我们日常分析过程中一般都会使用样本的均值来估计总体的均值。比如大家所熟知的实验,其实就是拿总体中的部分样本去做实验,然后在部分样本上得到的均值效果就可以等效代替是在全部样本上得到的效果。
不过需要注意的是,我们上面说到的是随着样本数的增加,样本均值会越来越接近总体样本均值,接近不代表等于,所以样本均值和总体还是会有一些偏差的,但在实际业务中我们一般又无法拿到总体的均值,所以只能用样本均值,但是要知道还是有一些偏差的。
接下来,我们用数据模拟下:
我们先随机生成10w个值,把这10w个值作为我们的总体,然后随机从这10w里面抽取100、200、300 …… 99900、100000,针对每次抽取出来的样本计算一个均值,最后会得到99900个均值,我们把这些均值按照样本容量从小到大排序,最后绘制出均值趋势图如下:
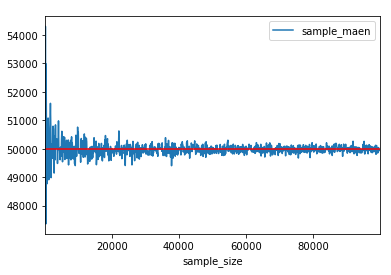
上图中的红线是代表总体均值,可以看出,随着样本容量n不断增加,样本均值的波动幅度越来越小,越接近于总体均值。上面过程的Python实现代码如下:
import numpy as np
import pandas as pd
all_value = np.random.randint(1,100000,100000)
sample_size = []
sample_maen = []
for i in range(100,100000,100):
sample_size.append(i)
sample_maen.append(np.random.choice(all_value,i).mean())
pd.DataFrame({"sample_size":sample_size,"sample_maen":sample_maen}).set_index("sample_size").plot()
plt.axhline(all_value.mean(),color = "red")
大家可以把代码复制下来,自己运行一遍。

 扫描二维码
扫描二维码 评论